The article contains the knowledge of ES6…
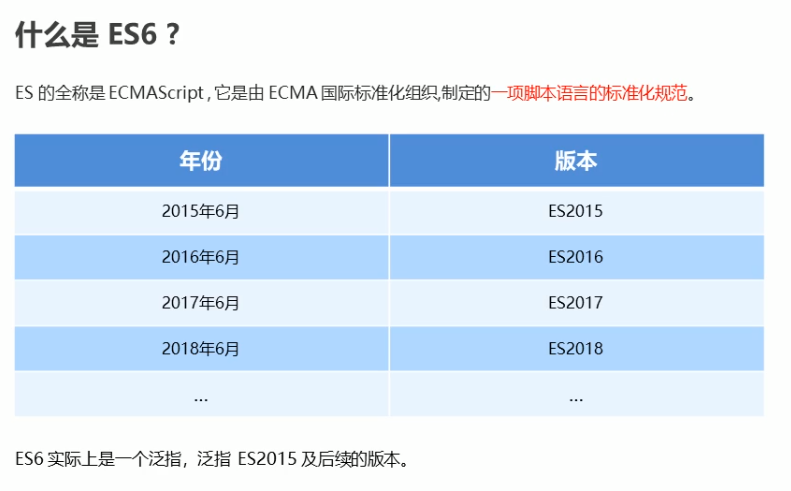
ES6

let

let与var
注意,之前说的闭包里面的某个函数作用域中某个var声明的局部变量在另一个函数作用域中无法使用注意这里是函数作用域不是块级作用域,在块级作用域中var声明的变量在不同块之间是可以访问到的
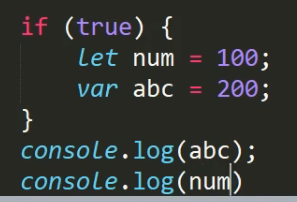
比方说这个案例,abc是可以输出的,但是num不行
let能防止for循环中的变量变成全局变量
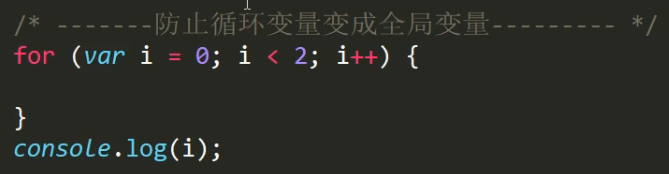
这里的i能输出,且为2
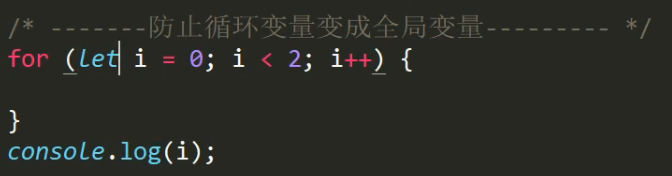
这里的i不能输出
let不存在变量提升
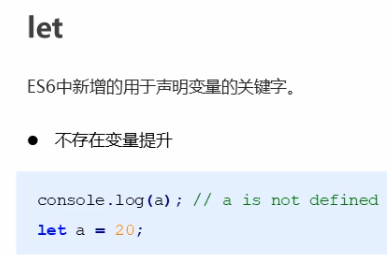
let声明的变量具有暂时性死区的特性

在块级作用域内声明的变量会跟块绑定起来,使其不受外部影响,所以就算外部已经用var声明了这个变量,在块内我们使用let再次声明这个变量,此时块内会以let声明的变量为准,在块内声明的该变量与块外声明的该变量是没有任何关系的,因此上图输出为not defined
典型案例
1.
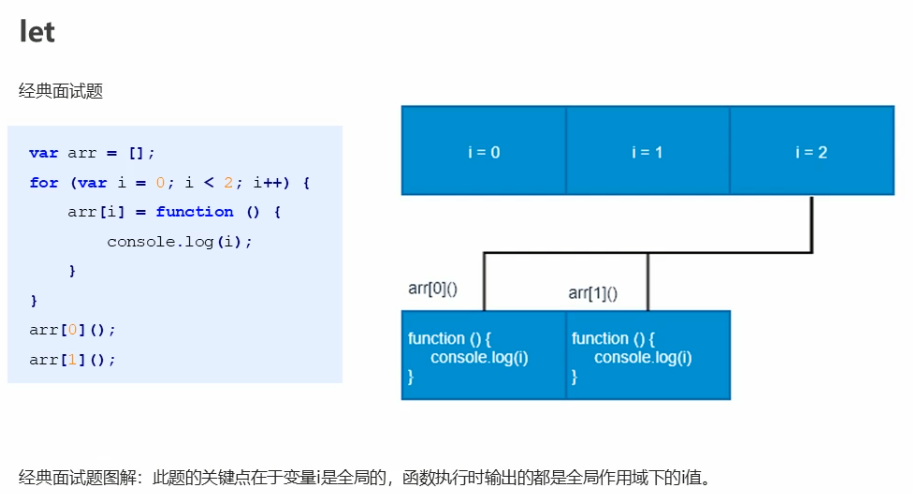
上图由于循环的时候函数arri并没有执行,arri这个函数是在循环结束之后再执行的,并且在函数内部并没有定义i,所以函数执行时在自己的作用域内是找不到变量i值的,根据作用域链原则要向上一层作用域去找i,实际上上层作用域就是全局作用域,而在全局作用域下是有变量i的,实际上就是循环时创建的全局变量i,由于arr0,arr1这两个函数执行的时候循环早就结束了,因此这两个函数用到的都是全局变量i,而且输出的i值为2,且两个函数都是输出2。(这里其实可以这样想:两个函数输出的都是全局变量i,且两个函数都要到循环结束之后再执行,而i到最后跳出循环的时候就是2,所以两个函数输出的都是2)
接下来将上图的var改成let
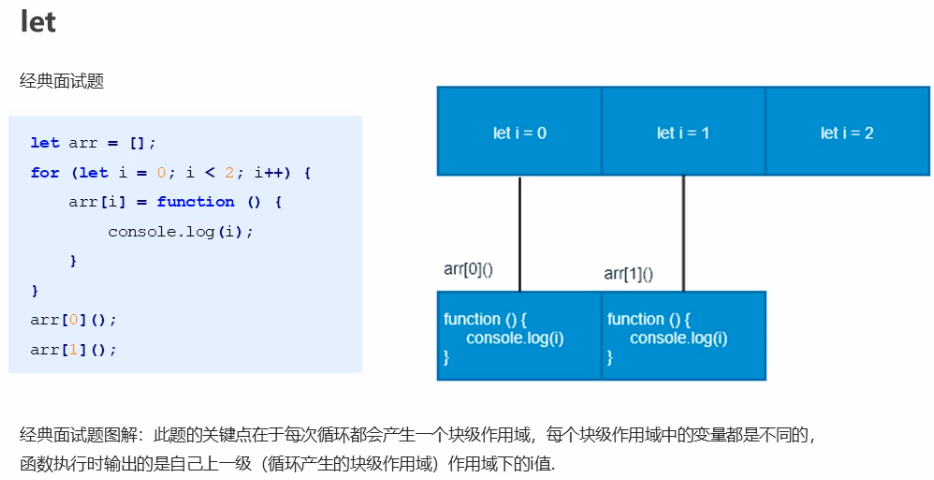
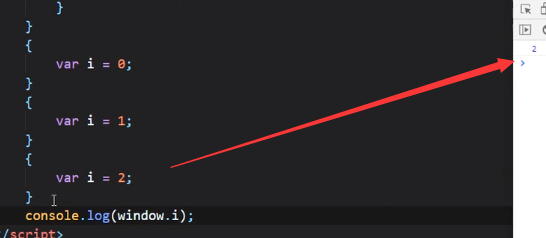
注意,for循环的每一轮循环都有自己的变量i,且由于他们分别处于不同的块级作用域,因此互不影响(这里的let I = 0,let I = 1,let I = 2 这三个i互不影响)
解释一下为什么这里输出是0和1:
因为let使得函数在执行的时候去找上级i的时候是去找同一个块级作用域(或者说是包裹函数自己的那个块级作用域)中的变量i(刚才说了每一次循环都会产生一个块级作用域,块级作用域中的i互不影响)
(这里的查找变量i是指在同一块级作用域中相对函数自身来讲的上级的变量i)
因此i该是几还是几,所以两个函数输出的是0和1
2.
类似的还有这个案例
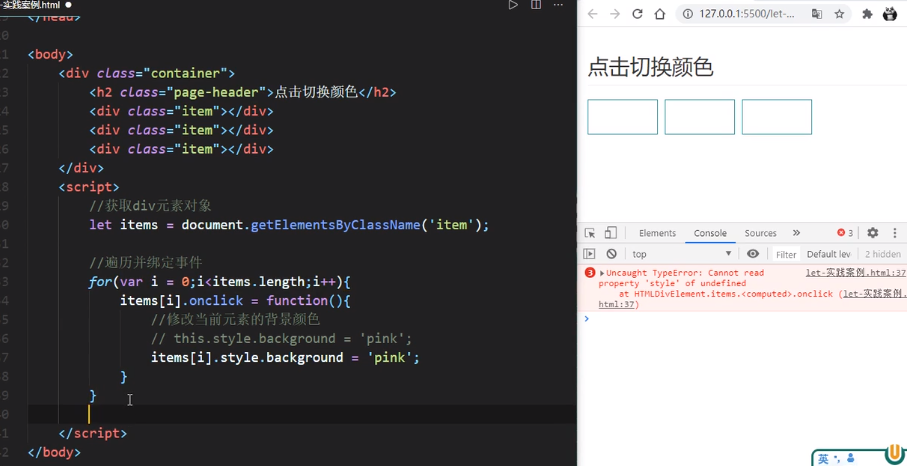
点击事件失效,道理跟上面是一样的
const

const声明的变量也具有块级作用域
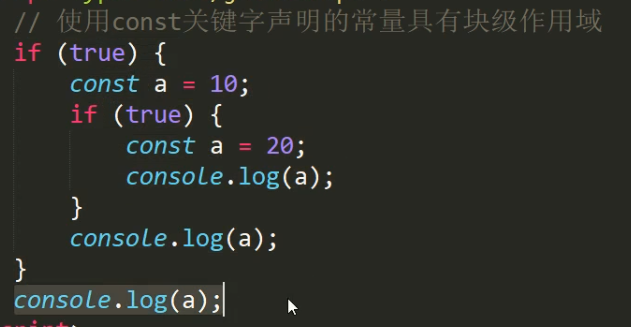
跟let一样,块级作用域之间的变量互不影响,因此这里输出的顺序是:20, 10, not defined
const变量必须赋初始值

const声明的变量赋值之后不能修改

注意我们单独去找ary里面的值并进行修改是可以的,因为这个操作并没有改掉ary的地址,但是直接给ary赋值一个新的数组就不行了,因为这个操作就相当于直接把他的地址给改掉了,会报错,如上图
总结来讲就是简单数据类型值不可修改,复杂数据类型数据结构内部的值可以更改,但是该复杂数据本身不可更改
const跟let一样也有块级作用域

let、const、var的区别
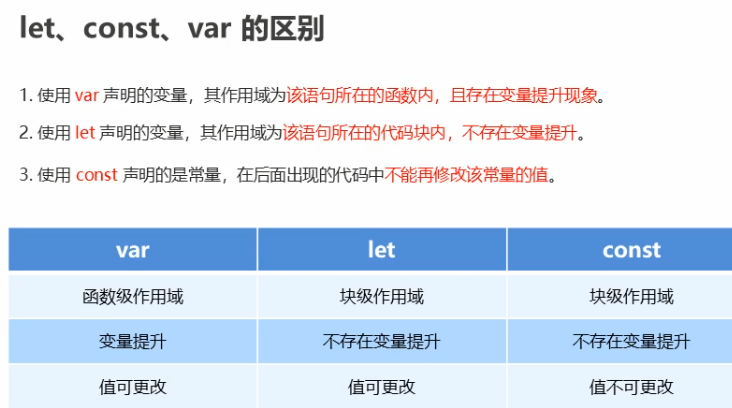
const要比let效率高,因此如果是恒定不变的或者不需要变化的值应该尽量使用const(因为const定义的常量不需要变化,JavaScript解析引擎不需要时时刻刻监控值的变化,所以const关键字要比let关键字效率高)
解构赋值

如果解构的变量数量跟右边数组的长度不对应

上下两个foo都为undefined
对象解构

在ES6之前,我们是这么取的:
person.name,person.age,这样要重复声明两次let变量会非常麻烦,ES6之后直接用对象解构就可以了
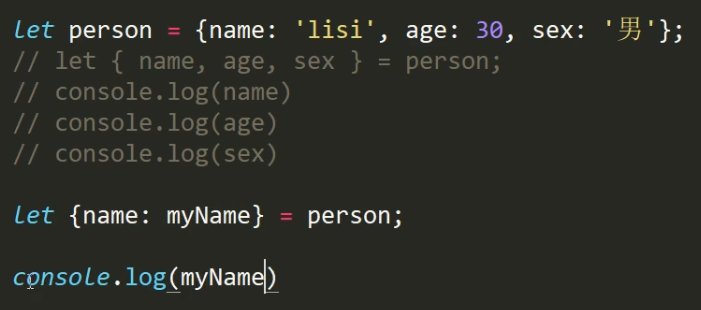
当然也可以直接let {name} = person; 这样可以直接拿到这个name
对象解构的另一种方法
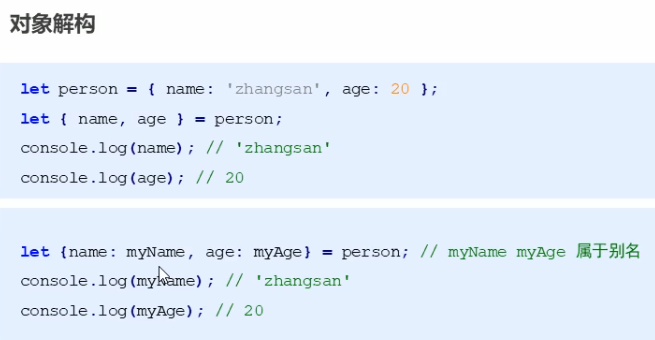
直接写清楚key: value去解析
箭头函数

如果函数体中只有一句代码,且代码的执行结果就是返回值,可以省略大括号

如果形参只有一个,也可以省略小括号


箭头函数不绑定this,箭头函数的this指向的是函数定义位置的上下文this
注意无论用call、bind等都无法改变this指向
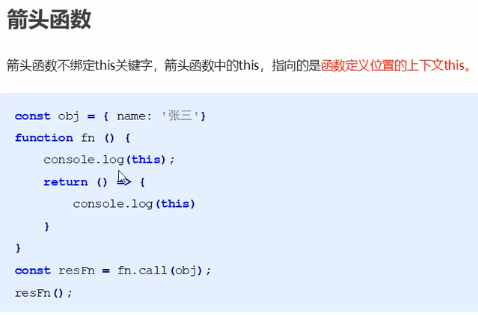
原先我们再上图return的位置写的是return function(){console.log(this)} 如果这么写的话最后调用resFn()的时候this指向的一定是window,但是箭头函数不一样,箭头函数不绑定this,且this指向的是函数定义位置上下文的this,所以在这里return的箭头函数打印的this还是name为“张三”的obj
箭头函数不能作为构造实例化对象

箭头函数不能使用arguments变量
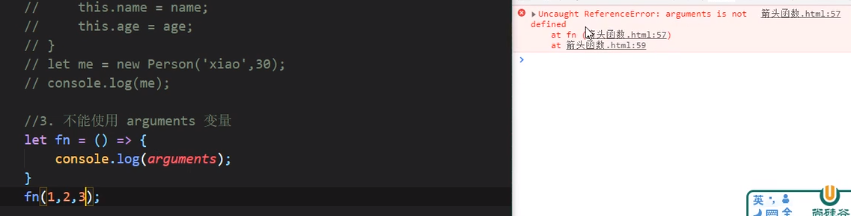
经典易错题
1、
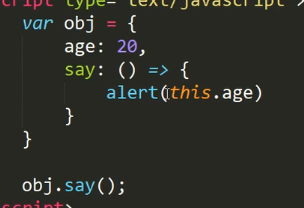
这里输出的是undefined
我们刚刚讲了箭头函数的this指向上下文的this,上面那个案例上下文是指在函数所产生的作用域内的上下文,而这里箭头函数定义在一个obj内,而obj不能产生作用域,因此这里箭头函数的上下文事实上是全局作用域,因此this指向的其实是全局作用域,而全局作用域并没有定义age
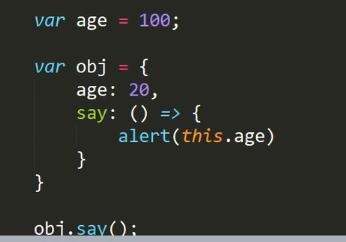
下面我们在全局作用域下定义一个age,结果显示的就是100
(这里其实换做原先的写法 say: function(){alert(this.age)},那最后在调用的时候谁调用this就指向谁,所以会输出20)
2、
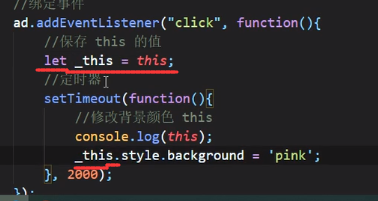
在外层套了一个setTimeout之后this指向window导致属性更改失败:
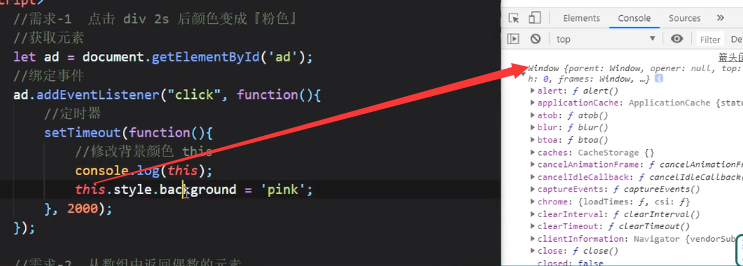
解决方法:
原先:
使用箭头函数:
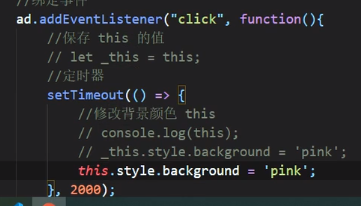
3、
从数组中返回偶数元素:
原先:
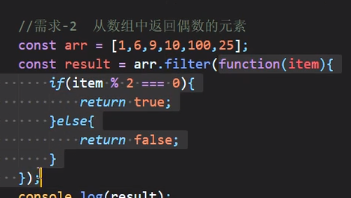
使用箭头函数:
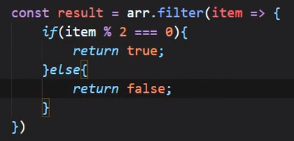
使用箭头函数之后的更加简化的版本:

总结
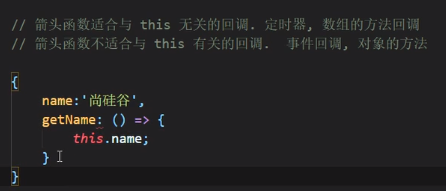
箭头函数适合与this无关的回调,比方说定时器、数组方法的回调
但是,箭头函数不适合与this有关的回调,比方说事件的回调、对象的方法的回调,比如上图,我们知道对象不产生块级作用域,所以上面的getName中的this指向的其实是window(正确的做法是写成原来的function而不是箭头函数)
但是,在某些情况下这样用反而能方便我们的实现
rest(剩余参数)

注意…args必须写在其他参数的后面
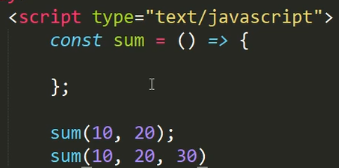
我们想要实现计算括号内的数据之和,在ES6之前通常会用arguments去拿取可变参数,但是箭头函数里面没有arguments
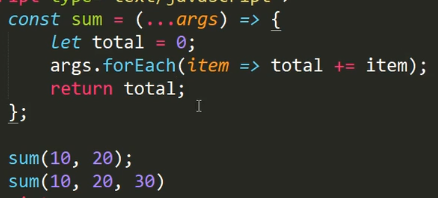
现在的写法是这样的,用…args去拿可变参数,然后用forEach去计算累加,注意在forEach里面的箭头函数要像上图这样写(其实就是Java的lambda表达式)
rest代替arguments
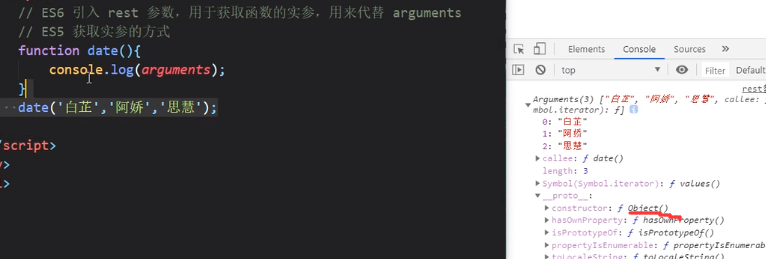
ES5的arguments本质上是一个对象
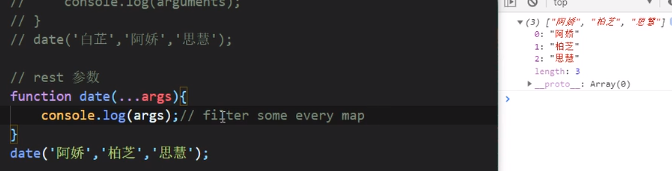
而ES6的rest他是一个数组,可以使用filter、some等函数
剩余参数与解构配合使用

Array的扩展方法,扩展运算符(展开语法)

使用扩展运算符我们可以得到数组或者对象转为用逗号分隔的参数序列,注意这里是有逗号分隔的,当我们将用逗号分隔的参数序列放到console.log()方法中之后,逗号会被当做参数的分隔符,所以这里的逗号才没有输出,为了验证逗号被当作参数分隔符,我们直接打印console.log(1,2,3),发现输出的确实是1 2 3,这个特性会在后面的异步中被广泛应用

扩展运算符用于合并数组

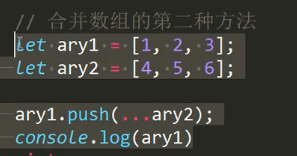
es5合并数组的做法
a1.concat(a2),现在有了扩展运算符就不用这么麻烦了
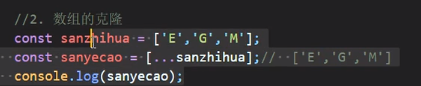
扩展运算符用于克隆数组
扩展运算符将伪数组转化为真正的数组
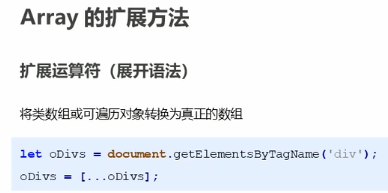
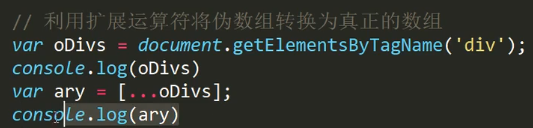
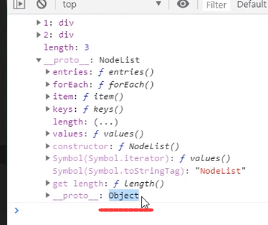
我们知道document.getElementsByTagName()获取来的是伪数组,本质上是一个对象:
伪数组变真正的数组之后就能用数组的方法了
Array.from() 将类数组或可遍历对象转换为真正数组

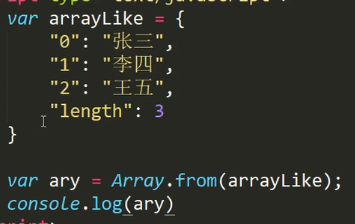
通过Array.from()将伪数组直接转化为真正数组,
注意上面arrayLike的这个对象竟然是一个伪数组
Array.from()中的第二个参数

第二个参数其实就是一个函数,通过该函数来遍历改变数组中的每一个值(类似python的lambda)

查找方法:find()
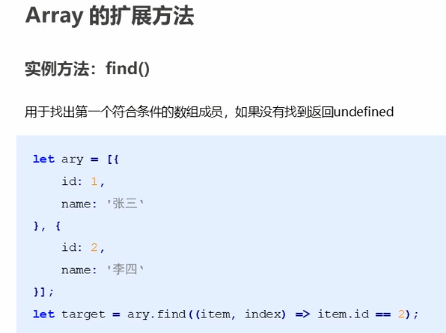
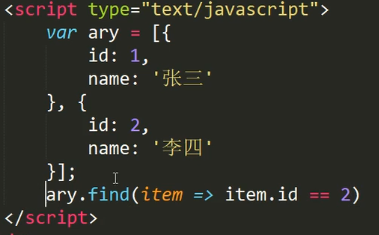
查找数组中符合条件的第一个元素,找不到返回undefined
返回index的查找方法:findIndex()

返回第一个符合条件的元素的下标
判断是否包含方法:includes()

ES6之前我们用indexOf来判断数组中是否存在某个值,ES6之后我们用includes来判断
String的扩展方法
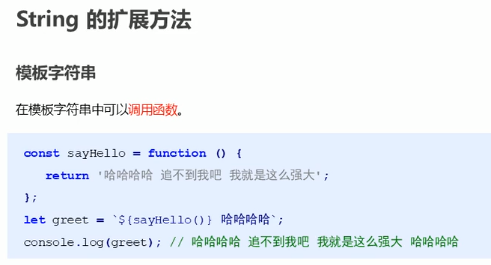
模板字符串

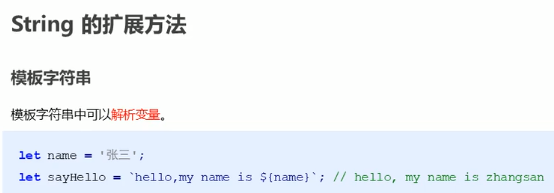
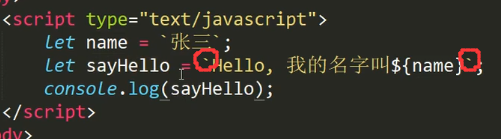
两个字符串都需要用反引号
模板字符串中可以换行

由于可以换行,模板字符串可以写的非常美观
模板字符串可以调用函数
startsWith()与endsWith()

repeat()

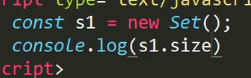
Set

属性size
set配合解构
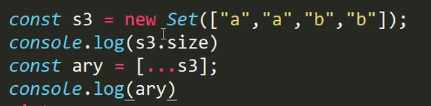
输出的ary是[“a”, “b”]
add()、delete()、has()、clear()

注意,add()返回Set结构本身
forEach遍历Set

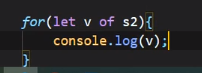
for of遍历Set
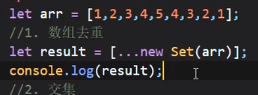
数组去重
交集
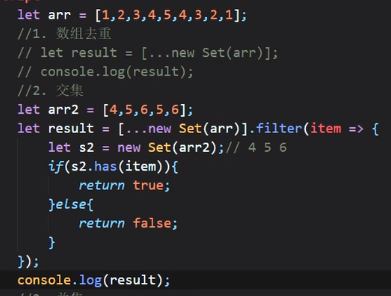
上图代码还可以这么写:

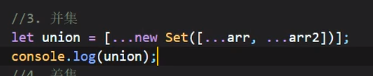
并集
差集

Map

属性size
set()、get()、has()、clear()
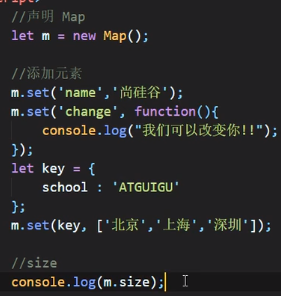
注意,map里面的key还可以是对象,value还可以是函数,如上图
for of遍历

注意for of遍历出来的东西并不是values,而是一个数组,其中第一个放的是key,第二个放的是value
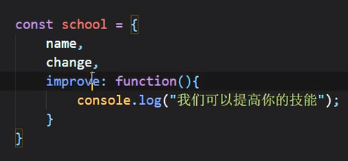
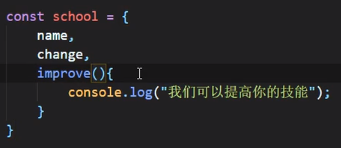
对象简化写法
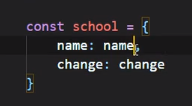
可以写成:
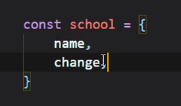
如果是方法的话:
可以写成:
ES6允许给函数参数赋值初始值

ES6允许参数使用解构进行赋值
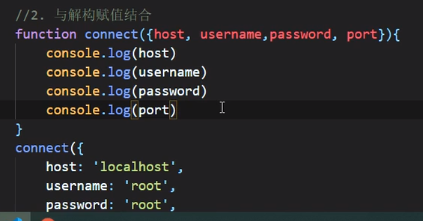
允许在参数解构赋值的情况下再给参数赋值
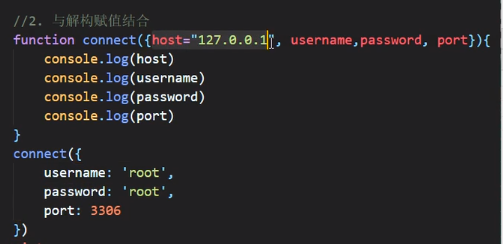
注意这里还没传host,但是有个默认值所以还是可以获取的
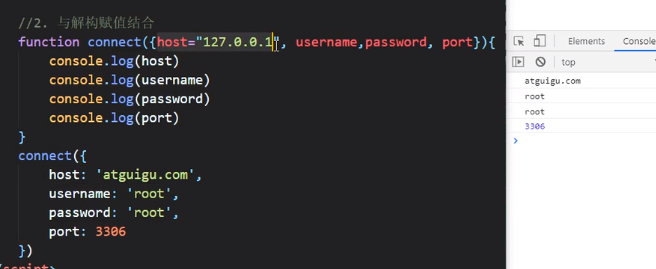
当然,传了就是用传了的值
Symbol基本使用


Symbol这种类型是ES6引入的一种新的数据类型,如上图
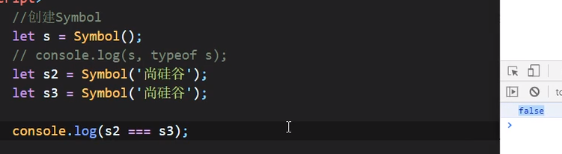
注意Symbol里面写的东西,就比方说上面的“尚硅谷”其实类似于一种注释(这里叫做描述字符串),像这里用Symbol来创建的话即时里面的描述字符串是一样的,两个Symbol也是不一样的,如上图
Symbol.for()
这是第二种创建Symbol的方式,该方式可以通过描述字符串来得出唯一的Symbol值:

如上图s4、s5的描述字符串是相同的,那他们两个拿到的Symbol值就是同一个。这也是与用Symbol创建的区别。
Symbol不能与其他数据进行运算

所有运算和比较在Symbol这里都是不可行的
总结JS中的所有数据类型
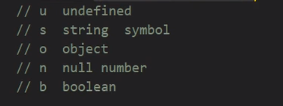
Symbol的作用或者使用场景
有时候我们给对象添加方法但是不确定它里面是否已经有了该名称命名的方法(比如下图,我们完全看不到对象game里面到底有哪些方法),如果直接game.function1
function(){}这样写是可以的,但是有很大的风险(命名冲突导致覆盖),这个时候就可以先用Symbol()做一步初始化:
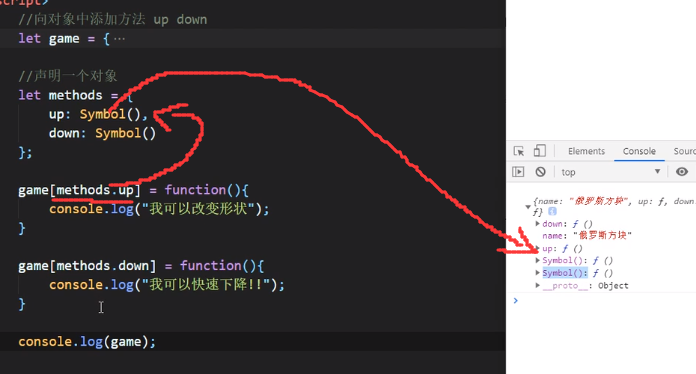
比方说我们先声明了一个methods对象里面用Symbol初始化up和down两个方法,再来给game赋值,如上图
Symbol作为对象的属性名({[Symbol(‘xxx’)]: function(){}})
原先我们给对象添加属性:
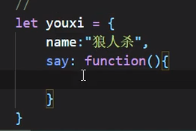
使用Symbol()添加属性:
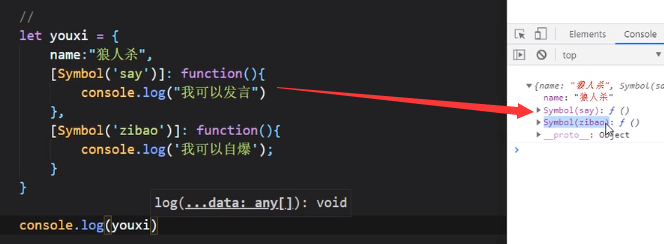
但是由于Symbol()是一个表达式,是动态的,不能直接写:Symbol(): function(){},不然会报错
正确的做法是给Symbol()加上中括号:[Symbol()]: function(){},如上图
Symbol内置值

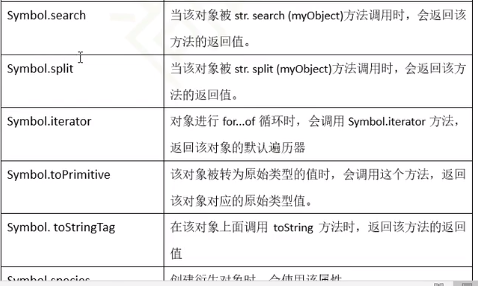

上图Symbol的 . 后面的这些属性都是Symbol的属性,而Symbol.xxx 这个整体是Symbol对象的属性
这些方法跟普通方法不一样,他在某些特定的情况下会触发执行,来改变对象在某些特定场景下的表现,说白了就是扩展对象功能
注意这些都是自动的,手动设置之后不需要我们手动调用
Symbol.hasInstance

注意这里Symbol.hasInstance要用中括号括起来
而且还可以传入param参数:
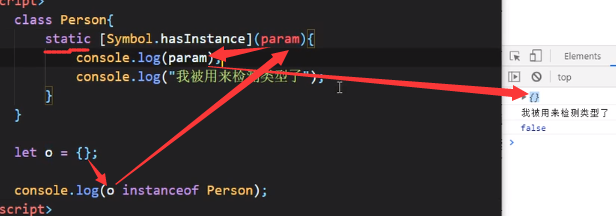
而且还可以返回true|false:
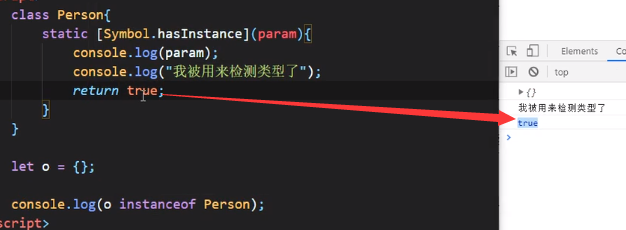
这就是Symbol.hasInstance的作用,可以自己去控制类型检测
Symbol.isConcatSpreadable
控制合并的数组是展开合并还是整体合并:
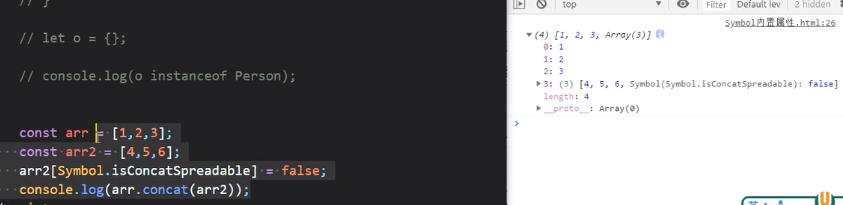
这里设置数组arr2的Symbol.isConcatSpreadable属性为false,现在合并arr1和arr2,发现结果是:[1,2,3,Array(3)],这个Array(3)还能进一步展开;
如果设置Symbol.isConcatSpreadable为true,那就是正常合并,结果为[1,2,3,4,5,6]
迭代器(iterator)

这里的iterator接口指的就是对象里的一个属性,这个属性的名字叫做Symbol.iterator
for in
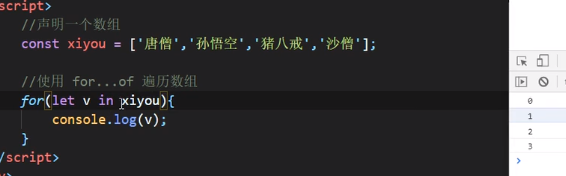
for in 很熟悉,就不多说了,他保存的是键名
for of
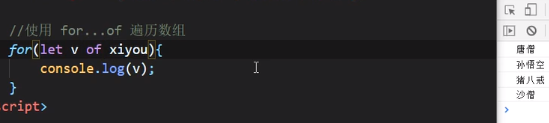
for of 保存的是键值
那么为什么数组也能用for of呢?那是因为数组里面有一个属性叫做Symbol.iterator:
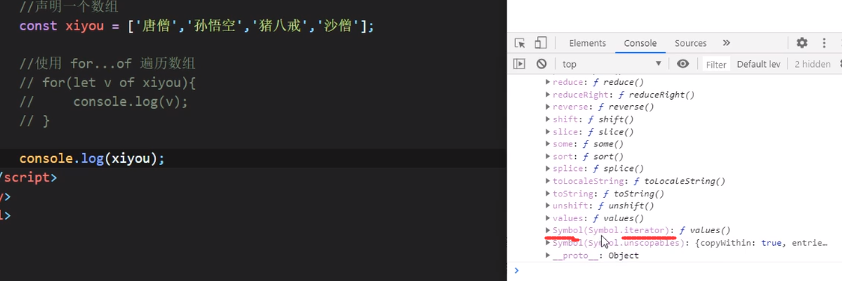
仔细看这个Symbol.iterator对应的是一个函数
原理

我们来看一下Symbol.iterator这个函数的内部:

注意,由于Symbol.iterator是一个函数,所以我们在给它加了一层中括号的同时后面还要加一个小括号让他得以取出真正的Iterator迭代器,如上图(xiyou是上上图的那个数组,xiyou[Symbol.iterator]拿出来的就是xiyou这个数组的Symbol.iterator这个属性,而我们刚刚说了它是一个函数,所以要用xiyouSymbol.iterator 来取出该数组真正的Iterator迭代器,并把它保存到iterator变量中)
之后我们发现Iterator的内部有一个next方法,如上图
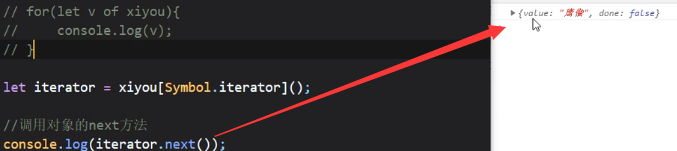
next方法执行结果如上图
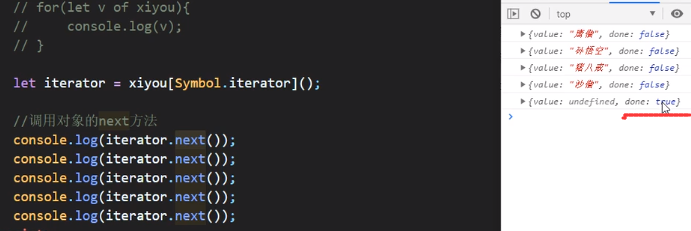
我们发现迭代器next()方法返回的内容里面除了value还有一个done,它是用来表示完成状态的,当迭代完成,也就是指针到达数组最后一个元素的后面(此时指针指向空)的时候,done就会由false变为true
应用场景

当我们需要自定义遍历数据的时候,就需要使用迭代器了
比方说我现在有一个需求:我需要使用for of来遍历banji对象中的stus数组中的内容:
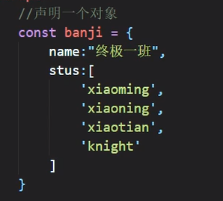
但是banji对象此时并没有Symbol.iterator属性,所以他是用不了for of的,那么我们给它加一个:
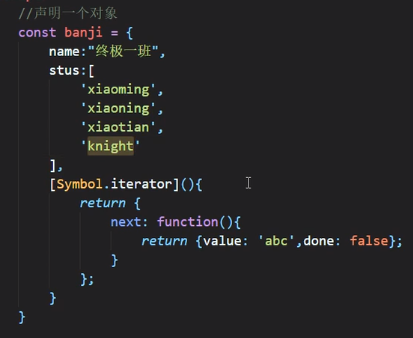
按照Symbol.iterator的需要,里面需要返回一个对象,并且对象里面需要有next方法,并且next方法需要返回一个包含value和done的对象,如上图
此时我们给value随便指定一个值,并执行上图代码,发现他会无限执行,那是因为done一直是false状态
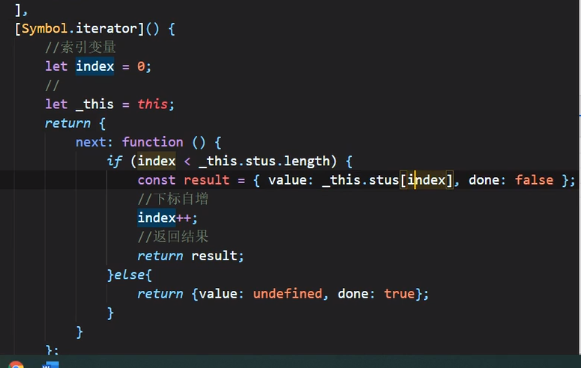
要解决上面的问题,我们需要一个index下标来控制整个流程,这里用_this=this的方法来解决this指向问题,当然也可以直接用箭头函数,如上图
生成器(yield)

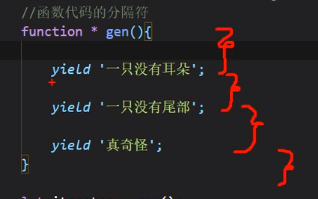
yield可以看作是函数代码的分隔符,三个yield产生四块代码

直接输出上图iterator发现它是一个生成器,只有调用next才会输出值
使用next执行yield代码块
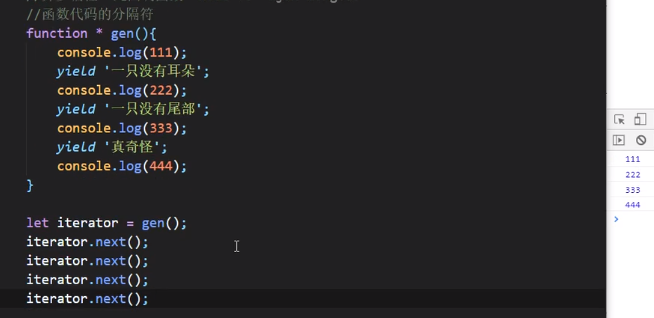
由于yield只是返回值,所以执行之后并没有打印yield里面的内容

使用for of遍历yield函数
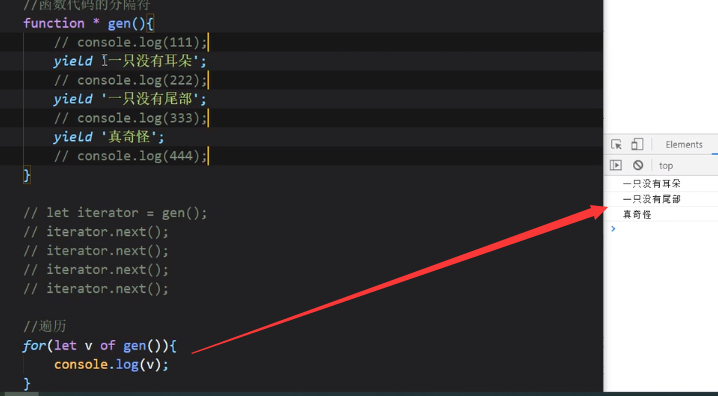
这里打印的是yield的返回值
生成器函数中可以传入实参
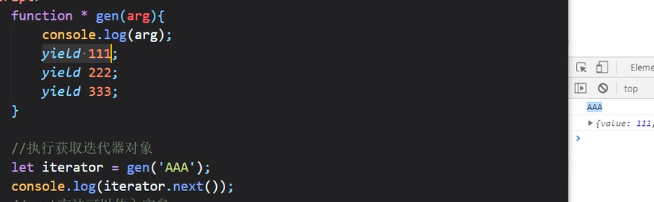
生成器函数的next中也可以传入实参
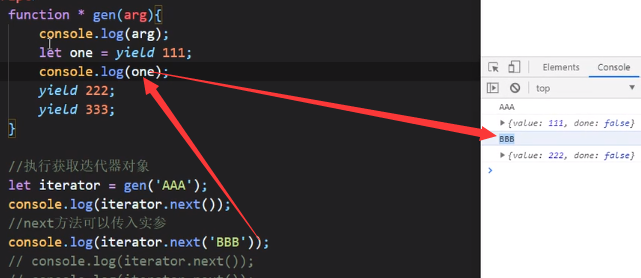
注意,这个传入的“BBB”将作为第一个yield的整体返回值(我们先调用了一次next,说明第一个yield的代码块已经执行完毕,再次调用next并传入“BBB”,在第二个代码块中我们想要输出第一个代码块yield的整体返回值,本来这个值是undefined(注意并不是111),但是现在我们自己传了“BBB”进去,所以他就变BBB了)
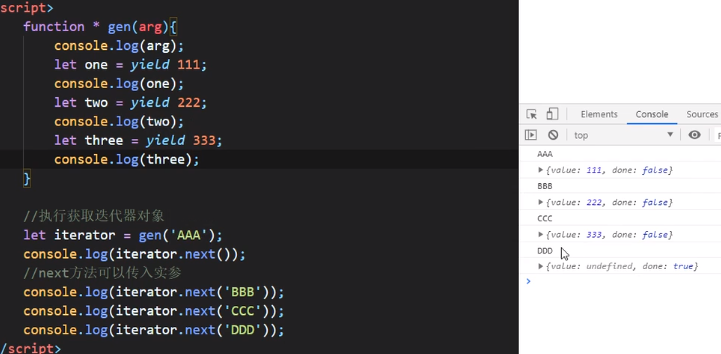
生成器函数实例
1、
生成器是js里面实现异步编程的解决方案,包括文件操作、网络操作(ajax,request)、数据库操作
有一个需求:1s后输出111, 2s后输出222, 3s后输出333
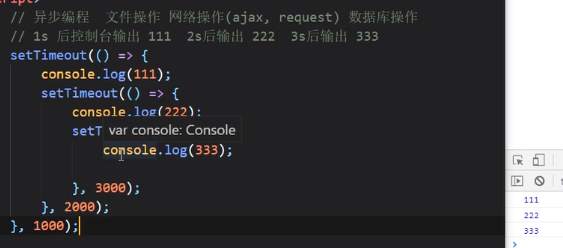
回调地狱了
现在用生成器函数来做一次:

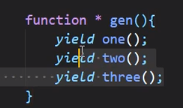
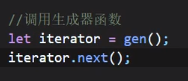
但是这样写只会出现111,因为在111的函数里面没有写调用222的函数,在222的函数里也没有写调用333的函数
正确写法:
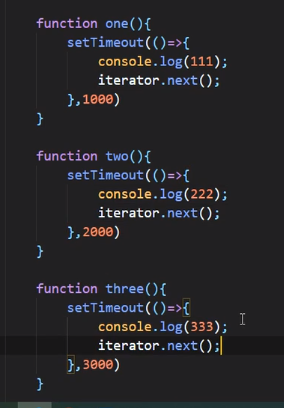

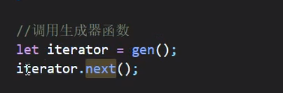
在每一个函数里面再调用iterator.next(),注意这个iterator是在代码最后调用的这个iterator
注意,肯定有人会想:
为什么不直接调用one();two();three();呢?那是因为在实际场景中,后面的函数进行是需要依赖前面的函数的返回值的,所以这么调不符合实际场景
2、

我们来看这个例子,有一个问题:data放在执行函数里面并没有返回,因此无法获取也无法更改
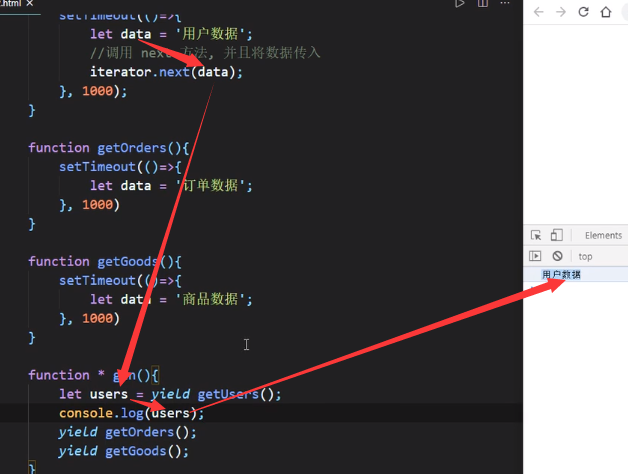
那么这里可以用到之前讲过的一个方法:
在next()里面传值,如上图,上图中是第二个next()里面传入了数据,因此他将作为第一个yield的返回结果。
小结
yield的函数看起来跟同步差不多,其实它是异步的
Promise
读取多个文件:
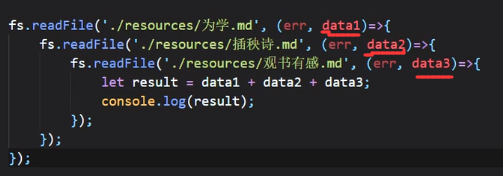
上图回调地狱,每一层函数里面的参数不能重名,比方说上图的data,这也是纯回调函数的一个弊端
Promise可以完美解决
基于Promise的读取多个文件:
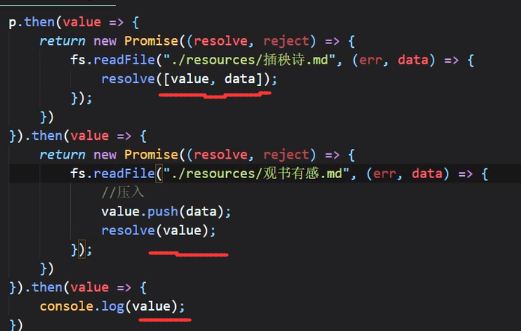
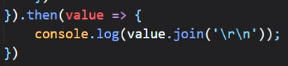
想当于把每一层的value叠到上一层的value里面,最后再输出
当然最终的value是一个数组,我们当然可以用.join()的方法把它变成字符串:
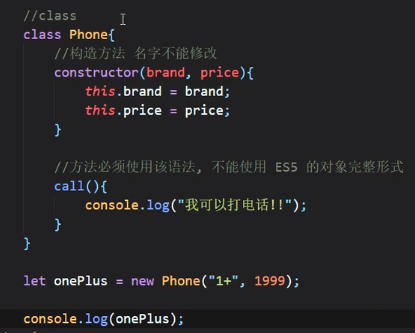
class

ES5:
ES6:
class的static属性
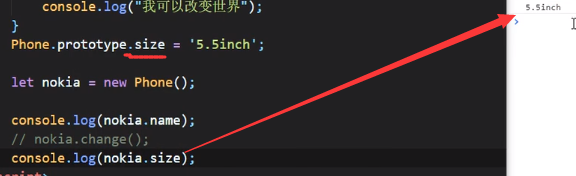
ES5:

可以看到类的静态属性实例是无法访问的,类的静态函数实例也是无法访问的。如果要访问的话应该把属性或者函数直接写在构造函数里面,或者直接写在原型里面:
ES6:
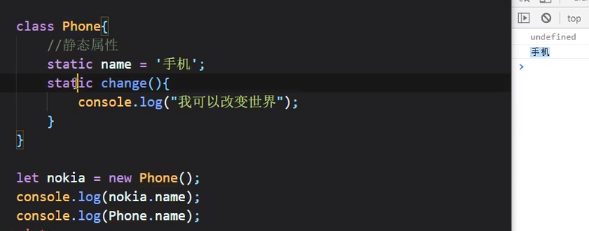
继承
ES5:
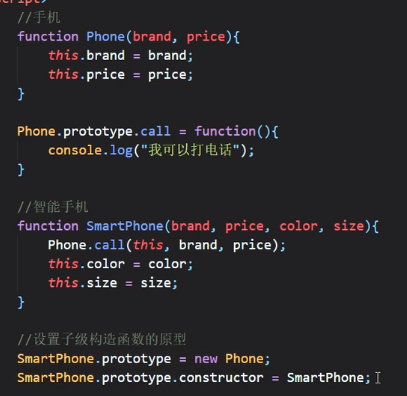
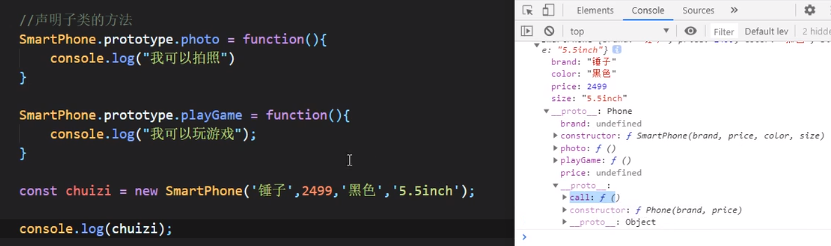
ES6:

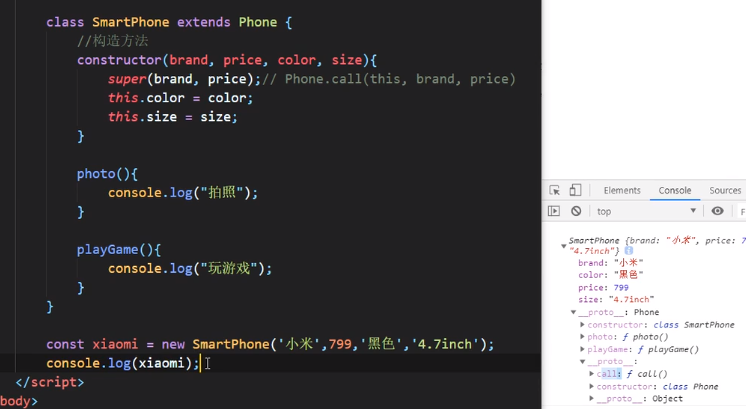
重写
直接在子类里面重写父类同名方法即可,注意!子类的同名方法里面不能写super()去调用父类同名方法方法的:
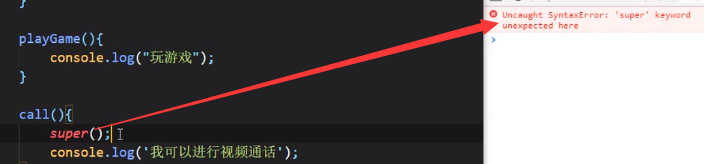
getter和setter
先来看看python的getter和setter:
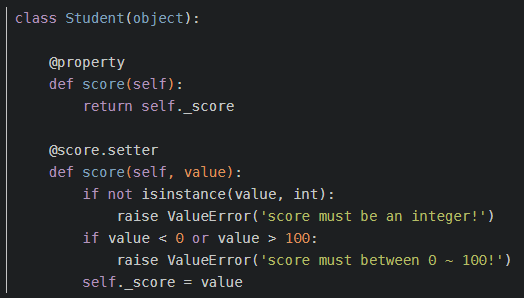

python是用@Property和@xxx.setter来实现getter和setter的,我们也知道,设置了@Property的方法会变成实例的属性,可以由实例直接调用的,其实JS的getter与setter和python是完全一样的。
JS的getter和setter:
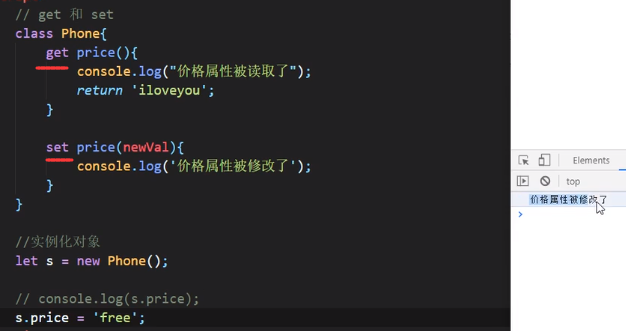
是直接在方法前面加get和set
这个时候可以直接由实例调用price这个属性
技巧
一般来讲getter适用于对象的某些动态的数据的计算,比方说算平均值,他整体的数据是会不断变化的,这个时候用getter就会非常方便,而setter适用于设置的时候判断传入数据是否合法,并进一步决定是否赋值
数值扩展
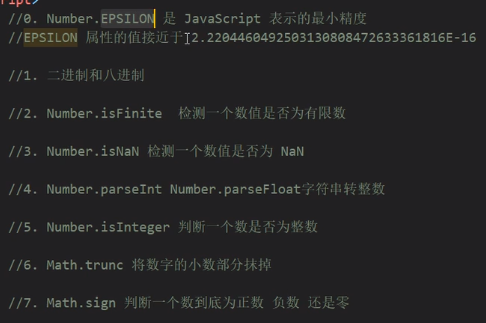
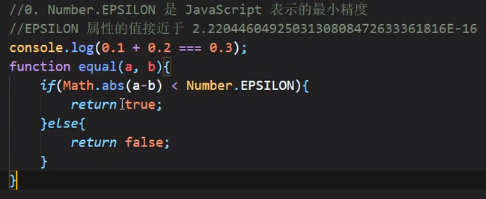
Number.EPSILON
是一个非常小的数,是js能表示的最小精度
主要用于浮点数的运算,对精度做一个设置
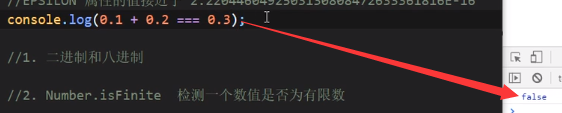
我们发现上面这个0.1+0.2是不等于0.3的
有了Number.EPSILON就可以进行0.1+0.2和0.3的比较了:
二进制和八进制
Number.isFinite
检测一个数值是否为有限数
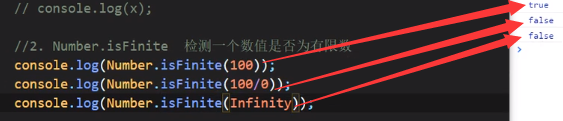
100/0竟然不报错???
Number.isNaN

Number.parseInt与Number.parseFloat

Number.isInteger
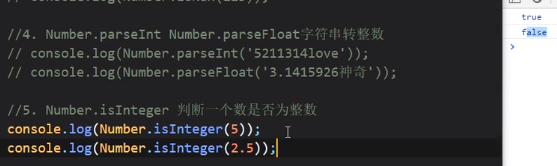
Math.trunc
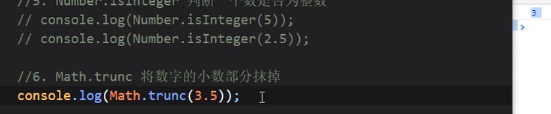
Math.sign
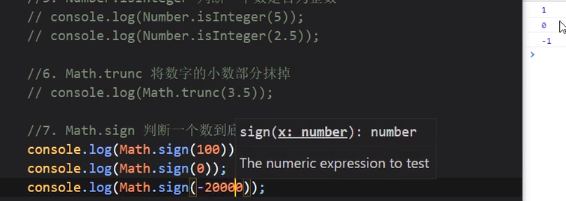
对象方法扩展
Object.is
用于比较两个数值是否相等,类似于 ===
但是当判断NaN和NaN是否相等的时候 === 会显示不等(任何东西与NaN比较 除非是写了一个不等号,否则都是返回false), 而Object.is就会返回true:
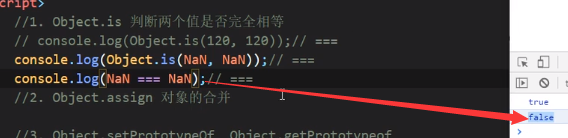
Object.assign
对象的合并
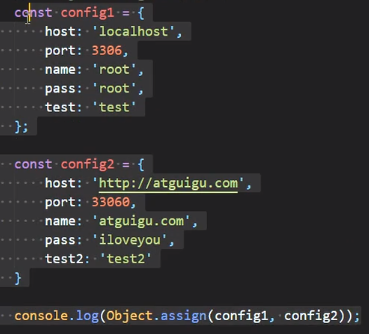
注意:如果前一个有某个属性,后一个没有,那就以前一个为准,如果前一个没有,后一个有,那就以后一个为准,如果前一个有,后一个也有,那还是以后一个为准
Object.setPrototypeOf与Object.getPrototypeOf
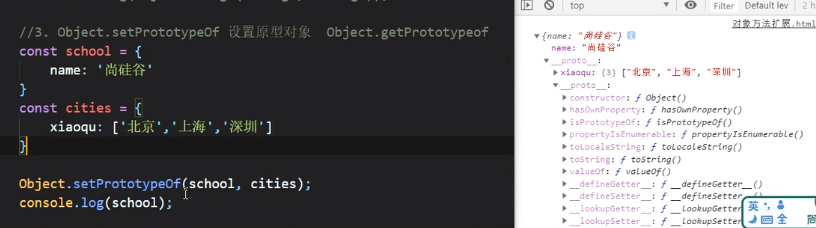
可以将某个对象的原型设置为某个指定的对象
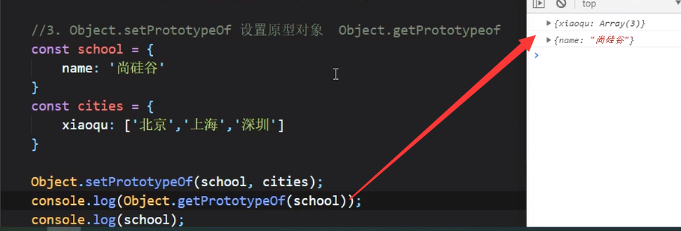
当然也可以用Object.getPrototypeOf获取,如上图
当然,我们不建议这么做,建议在Object.create()创建对象的时候就把他的原型设置上,这样效率是最高的
Object.create(proto[,propertiesObject])

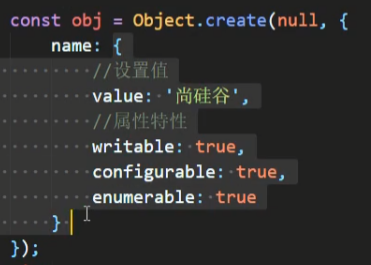
第一个参数指定prototype,第二个参数参考Object.defineProperty()
模块化

-
防止命名冲突:我在A.js中有变量a,我在B.js中也有变量a,两者是不冲突的;
-
封装函数到某个文件之后对外暴露接口;
-
高可维护性:多个人员协同开发减少命名冲突;升级的时候只需部分模块升级;
模块化规范(纸面上的东西):
-
CommonJS,以他为规范的产品有:NodeJS、Browserify;
-
AMD,以他为规范的产品:requireJS;
-
CMD,以他为规范产品:seaJS
AMD、CMD是专门针对浏览器端的
暴露语法

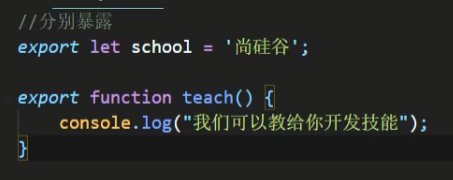
分别暴露
首先写一个js文件:
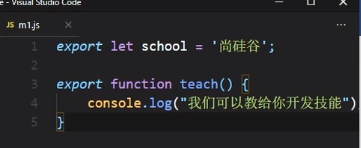
然后引入:
原先我们是直接引入:
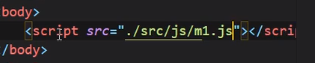
现在我们用模块的方式引入:
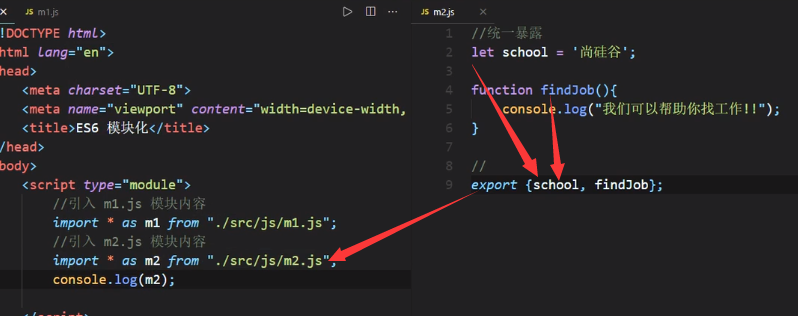
这样可以把目标文件所有export的东西全部引过来
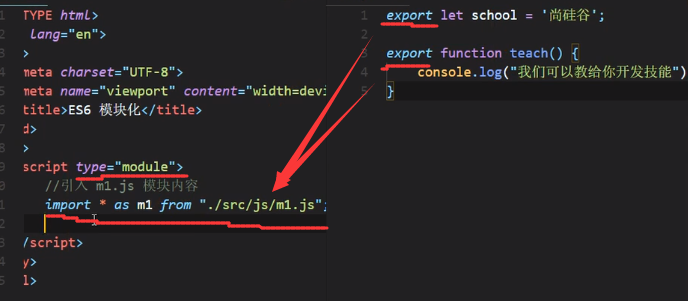
我们把引过来的m1做一个输出:
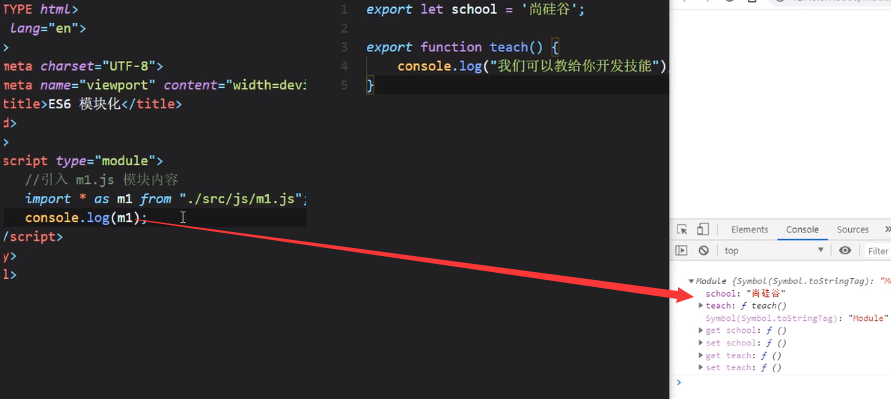
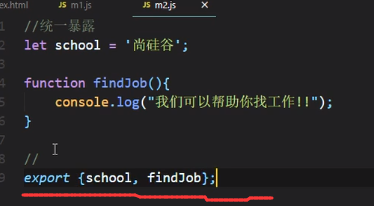
统一暴露
默认暴露
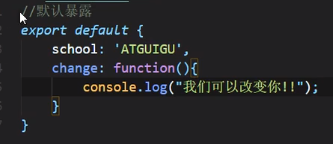
跟上面的不太一样,这种引入方式引入的是一个名为default的Object,在这个Object里面才会有我们想要的数据:
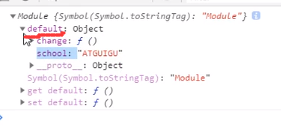
我们如果想要使用里面的方法的话就要对加一层default:

引入语法
通用导入方式
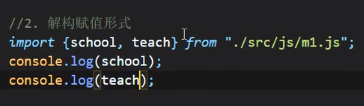
解构赋值形式
这里会有重名的问题:
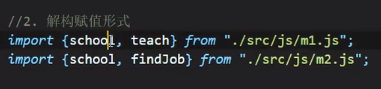
我们发现上图的两个school重名了,因此报错:

解决方法是使用别名:

问题2:
当我们使用export default {}的形式暴露的时候,引入时应该引default,但是不可以直接写default:

这样是会报错的,应该给default一个别名:

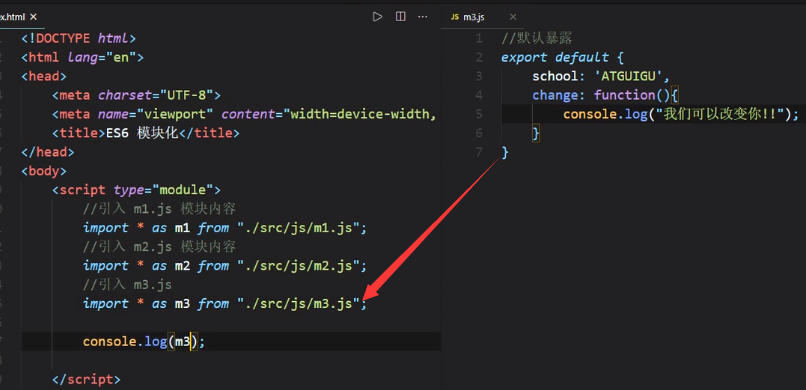
简便形式

当我们用export default {}的形式暴露的时候,引入时可以直接写别名,如上图的m3。除了这种情况以外,别的都不能直接写别名引入。
入口文件
除了直接在html代码中写一个script标签引入module之外,我们还可以将用于引入的代码语句写到一个入口文件里面,这里创建的入口文件是app.js
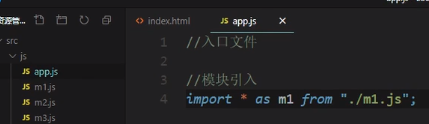
然后在html文件中引入该入口文件

注意要在原先引入js文件的写法的基础上再写一个type=“module”
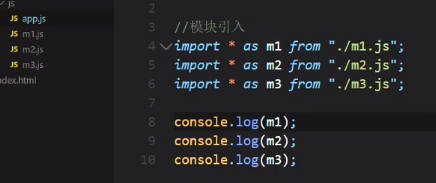
而且,在入口文件app.js里面,我们还可以写其他js的语句,比方说将引入的module输出:
babel对ES6模块化代码转换
在项目中由于兼容性问题以及ES6的模块化还不能对npm安装的一些模块进行导入,因此我们往往不会直接这么写:

而是会通过babel做一个转换
使用流程

安装工具 babel-cli babel-preset-env browserify(webpack); (在正式的项目中一般用webpack打包,但是他配置项多,所以我们暂时用browserify打包)
安装
初始化npm:

之后生成:
开始安装:

-D是指开发依赖
转换
由于上述是本地安装,因此无法直接用命令行调用安装的软件,我们可以用npx来调用:

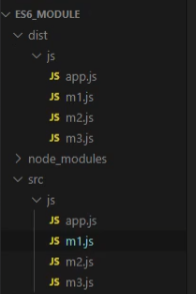
这里src下的文件是我们的原文件,dist下面是转换后的文件。我们来看一下区别:
原文件:
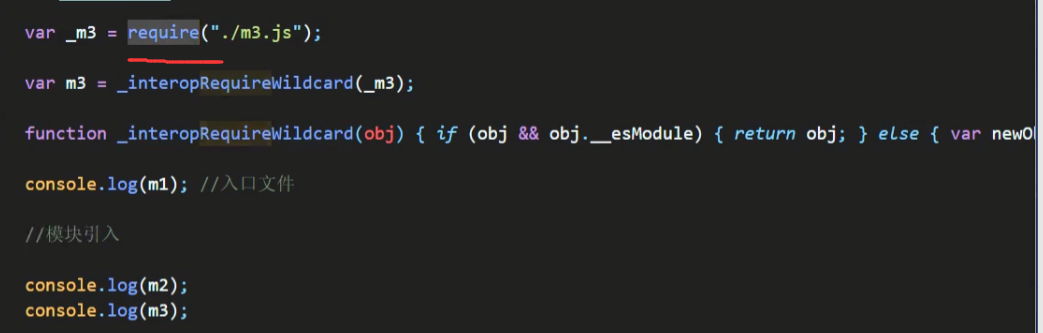
转换后文件:

这里的暴露语法发生了一些变化,转换后文件的暴露语法是一些CommonJS模块化规范的语法

CommonJS上面有介绍过
打包
如果不打包,上面转换后的js代码是不能正常运行的,因为他不识别里面的有些语法,比方说这里他就不识别require的语法:

这里我们给他引入一下,执行之后的结果:
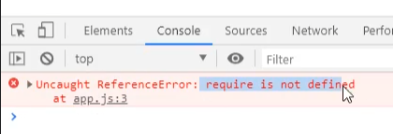
require不识别

我们将转换后的文件的app.js打包到bundle.js

这里-o的意思是output,后面应该写打包到的那个文件
打包好的文件:
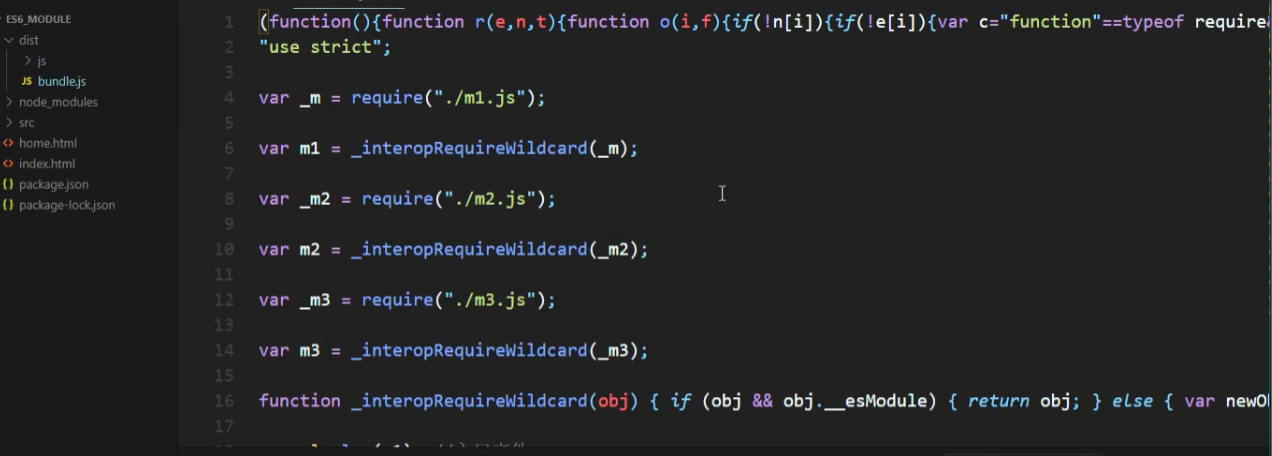
引入
之后引入该bundle.js文件:

之后就正常了:
如何对打包后的文件进行修改
先修改原文件,再重新转换、打包即可
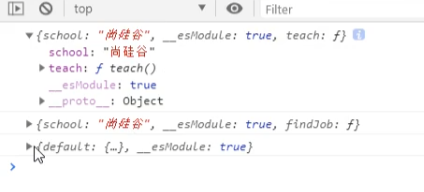
ES6导入npm包的语法
import 变量名 from ‘npm包名’;
它的作用就相当于原先commonjs的语法:
const 变量名 = require(‘npm包名’);
之后就能用该变量名来调用引入的npm包了
导入npm包并用npm包做出修改之后如何使用修改后的代码
跟上面的打包流程是一样的,先转换后打包再引入打包后的js文件最后才能使用
npm
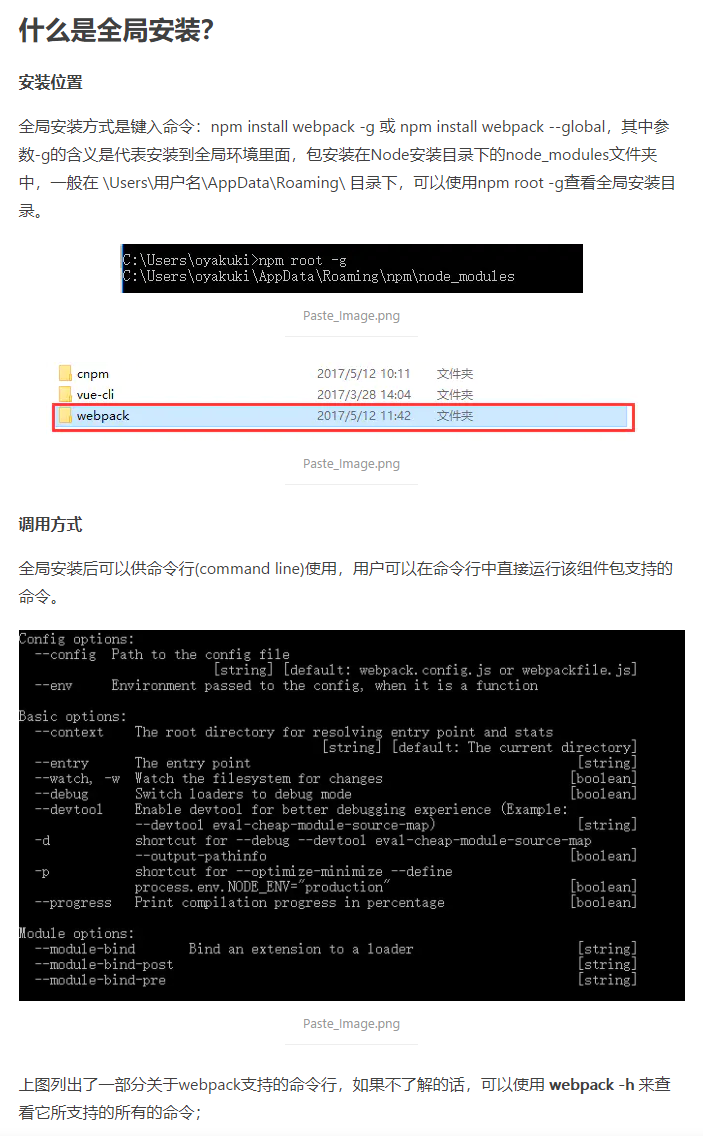
全局安装
npm install xxx -g 或 npm install xxx –-global
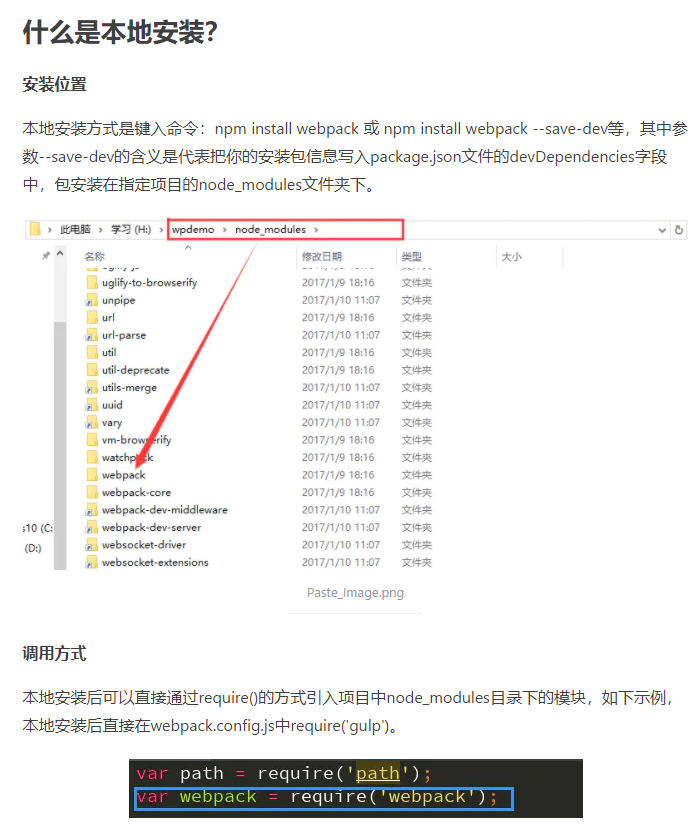
本地安装
npm install xxx 或 npm install xxx –-save-dev
配置镜像
-
方式一(持久使用,推荐)
npm config set registry https://registry.npm.taobao.org // 配置后可通过下面命令来验证是否成功 npm config ls // 此时:metrics-registry = "http://registry.npm.taobao.org/"表示设置成功 // 或 npm config get registry // 或 npm info express -
方式二(临时使用)
npm --registry https://registry.npm.taobao.org install express -
方式三
npm install -g cnpm --registry=https://registry.npm.taobao.org // 使用 cnpm install expresstall express -
方式四
安装nrm 管理,安装这个的前提是能确定链接到现在的镜像地址: npm install -g nrm 待安装完nrm 之后,通过nrm 管理镜像的地址,一条命令切换,如: nrm use taobao nrm 除了淘宝站点镜像之外还有其他的,可以使用一下命令查看: nrm ls 当然也可以在 nrm 中添加自己的镜像地址: nrm add URL 'registry_name' 或者删除用不上的镜像地址: nrm del 'registry_name' nrm 还提供测试镜像地址的响应速度: nrm test ['registry_name']
配置全局和缓存目录
npm config set prefix "C:\Program Files\nodejs\node_global"
npm config set cache "C:\Program Files\nodejs\node_cache"
新建环境变量:
NODE_HOME="D:\Program Files\nodejs"
path中添加:
%NODE_HOME%\node_global
%NODE_HOME%\node_cache
查看npm下载的内容的根目录
npm root -g
npx
安装npx
调用项目安装的模块

避免全局安装模块
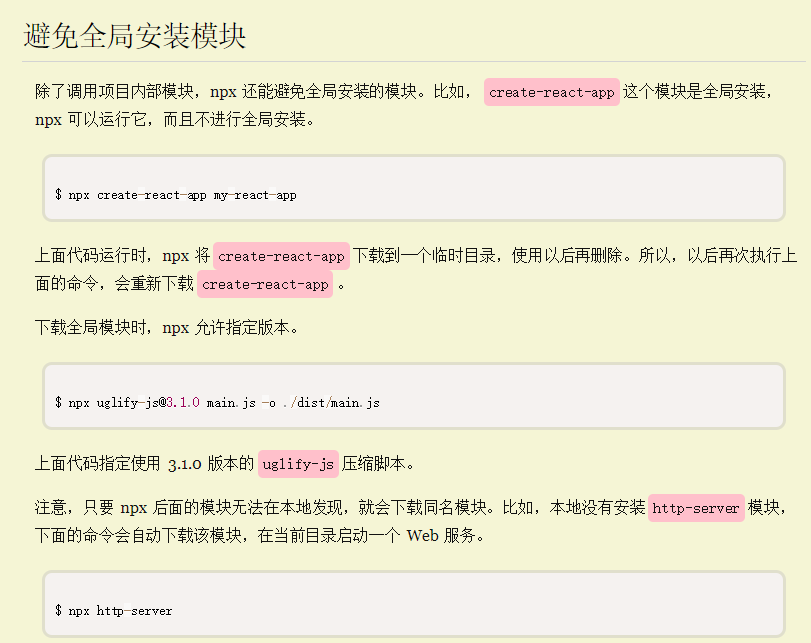
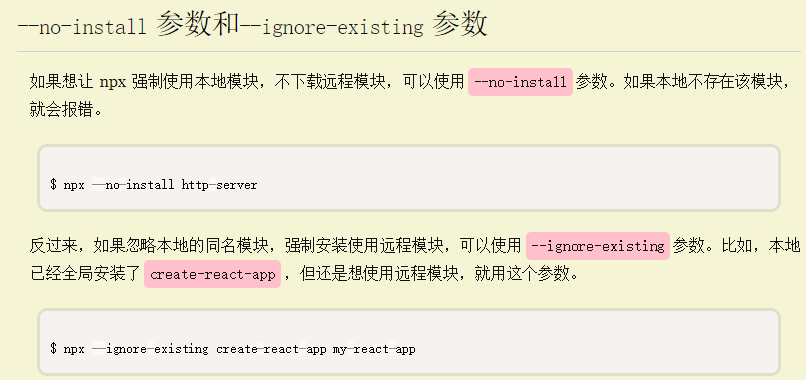
–no-install参数和—ignore-existing参数
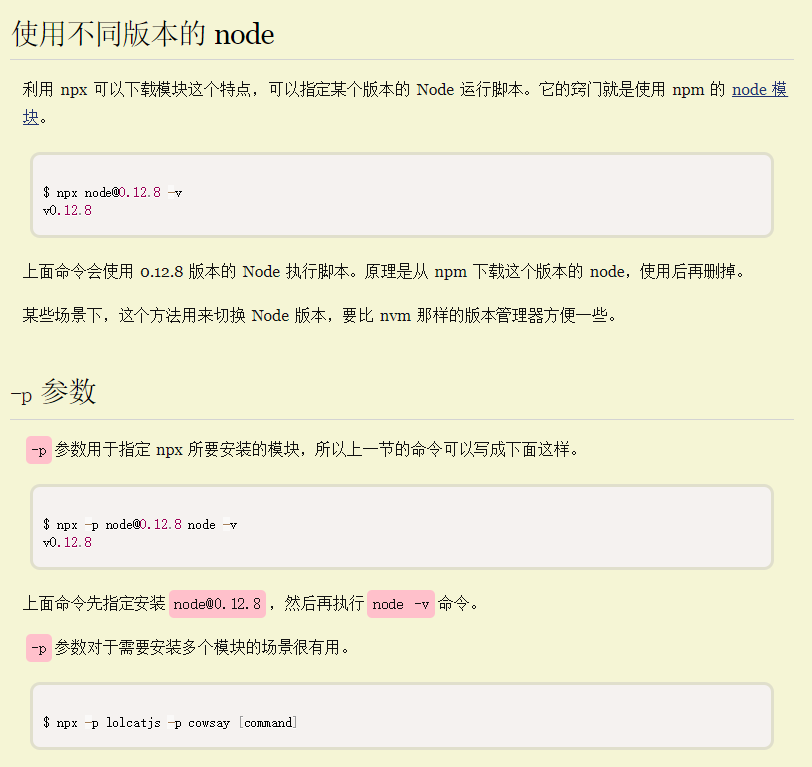
使用不同版本的node
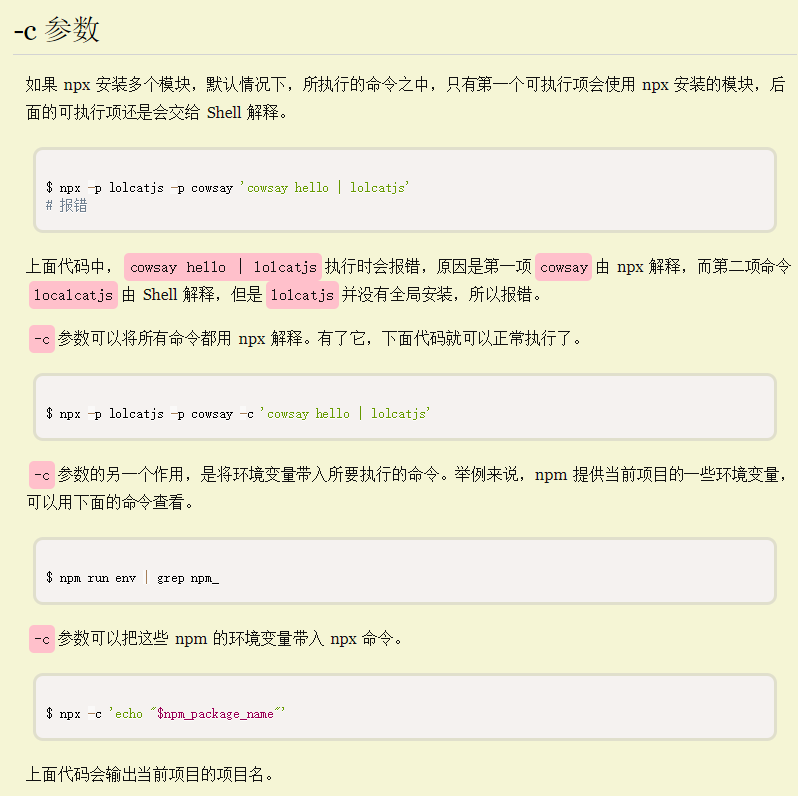
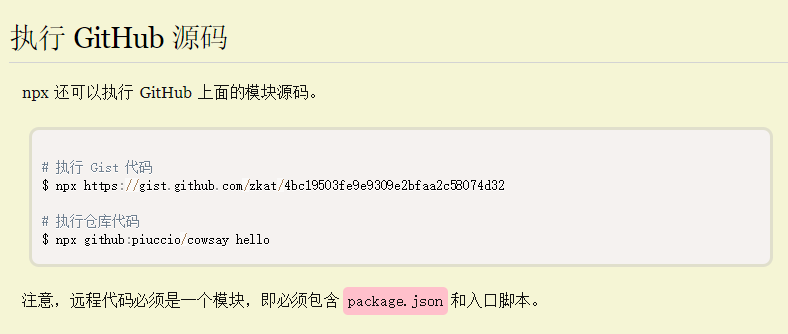
执行GitHub源码