The article contains the knowledge of feature engineering…
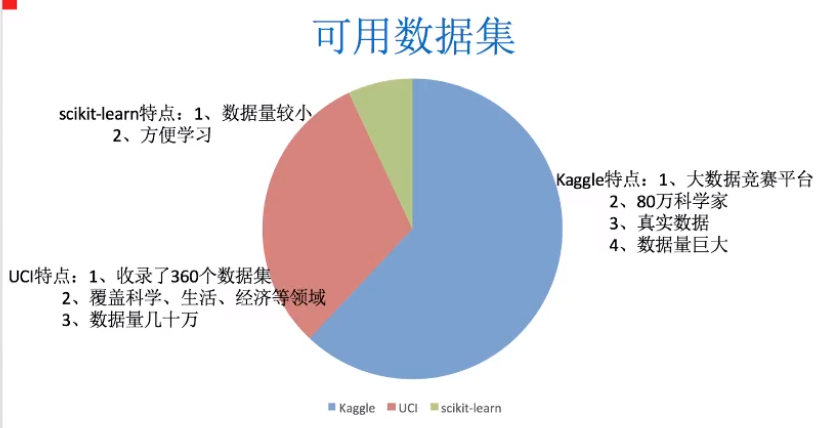
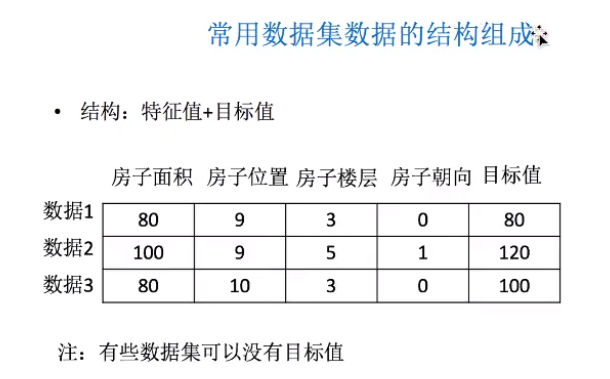
数据集



What、Why、How


sklearn.feature_extraction

DictVectorizer







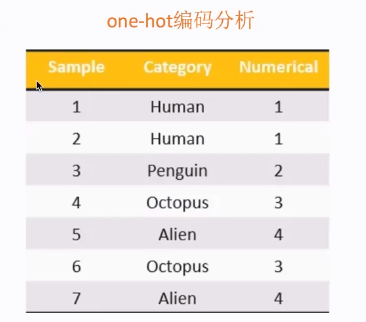
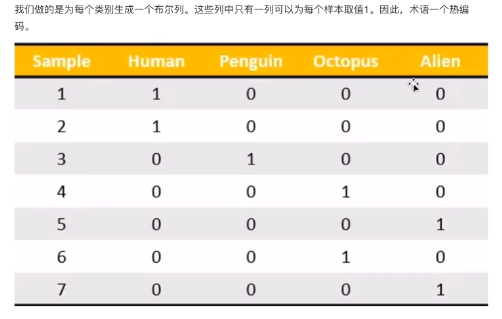
one-hot

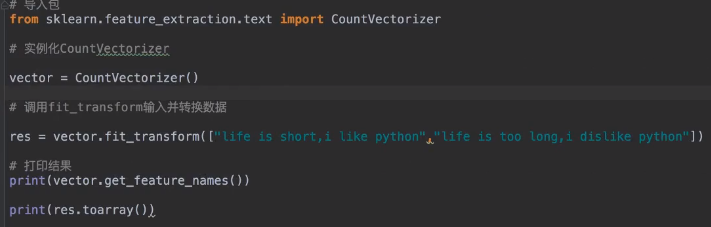
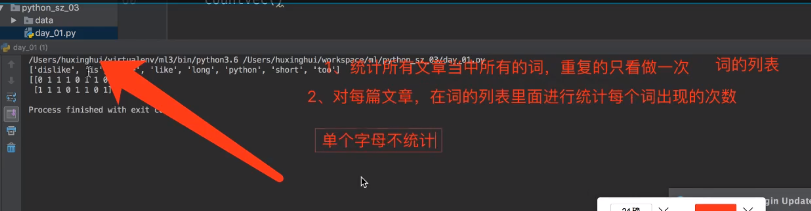
CountVectorizer





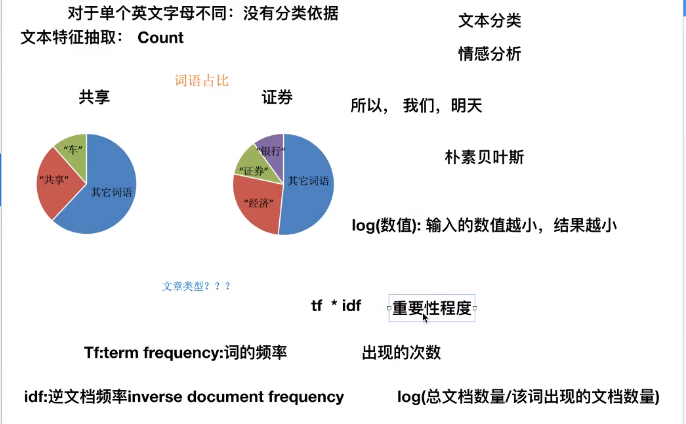
TF-IDF(TfidfVectorizer)




sklearn.preprocessing

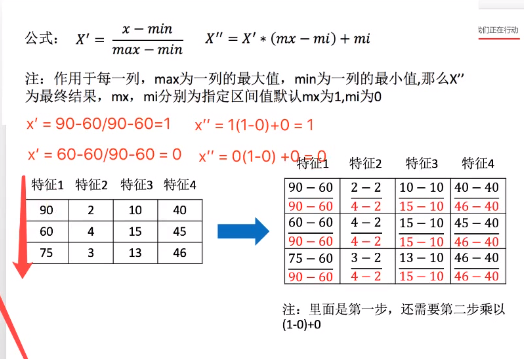
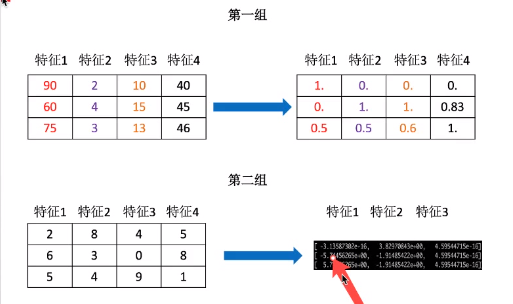
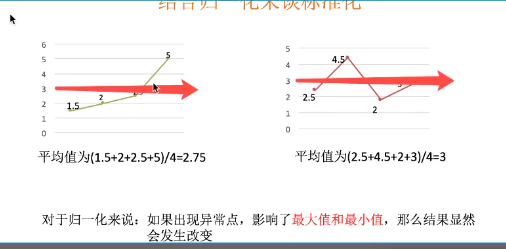
归一化(MinMaxScaler)







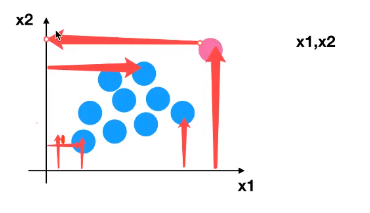


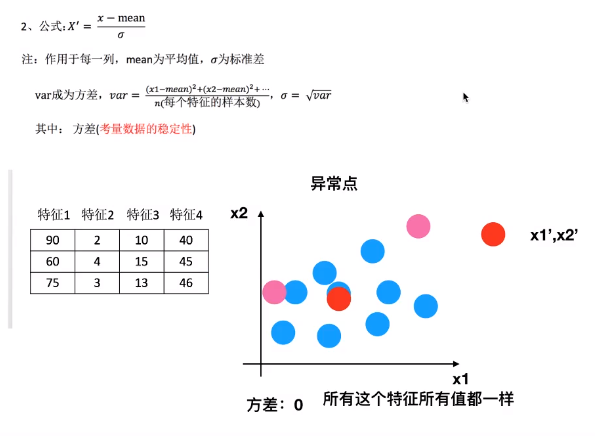
标准化(StandardScaler)


mean值在中间







处理缺失值

sklearn.preprocessing.Imputer



pandas


降维






VarianceThreshold

把方差小的特征删除






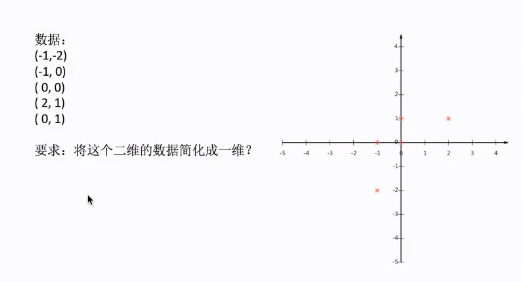
PCA









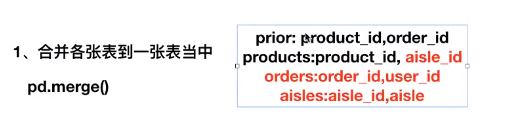

sklearn的数据集


转换器和估计器
转换器fit_transform()

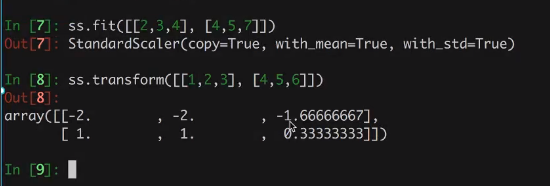
可以先fit,存入一些方差标准差之类的信息,然后用到其他的数据集上
估计器(随机森林、逻辑回归、贝叶斯、支持向量机…)


监督学习


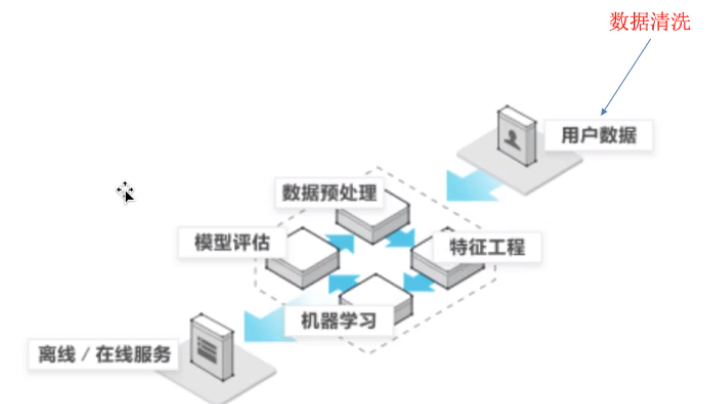
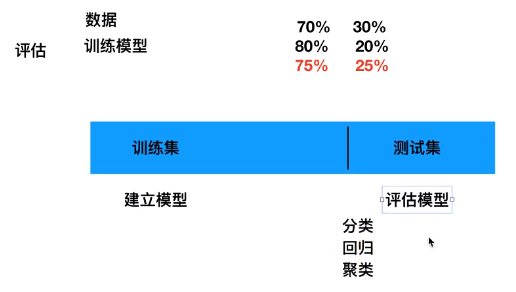
开发流程

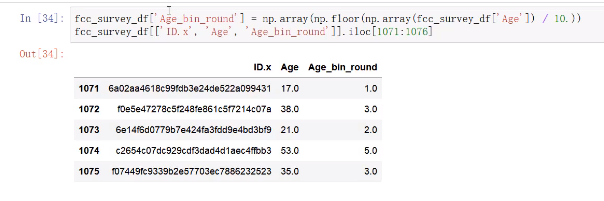
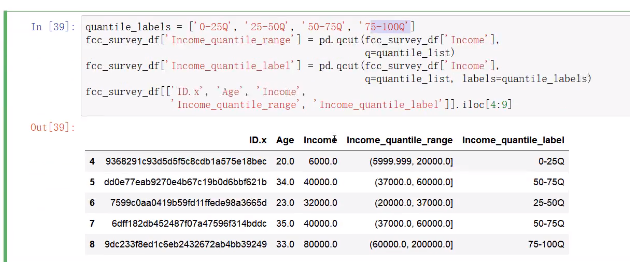
binning特征

pd.qcut()
nltk
英文句子预处理:
Similarity特征
cosine_similarity()

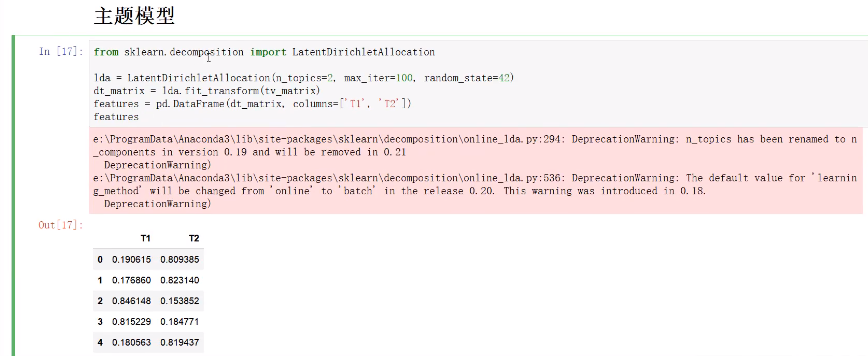
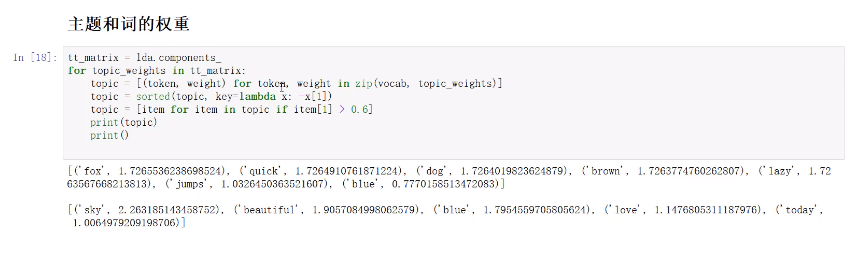
主题模型(LatentDirichletAllocation)
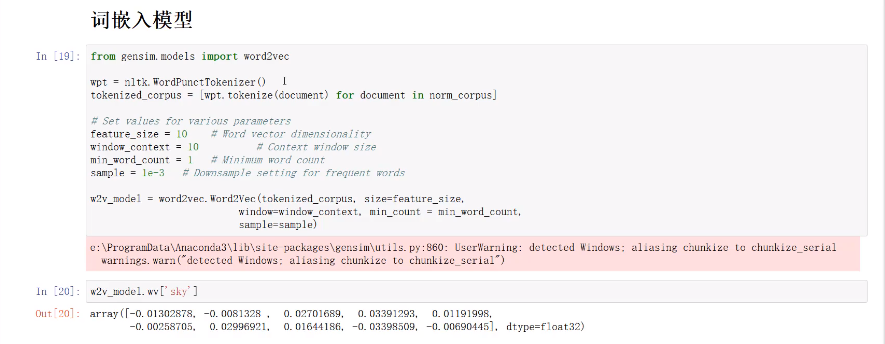
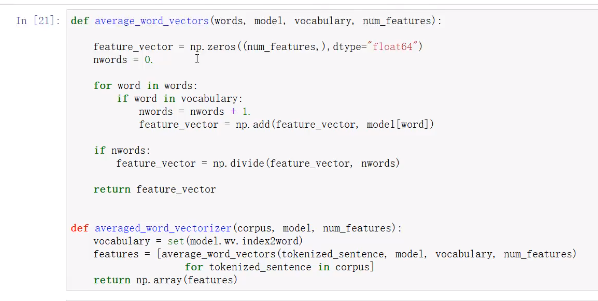
词嵌入模型(word2vec)

菜菜的sklearn

预处理(无量纲化,对应上面的sklearn.preprocessing)

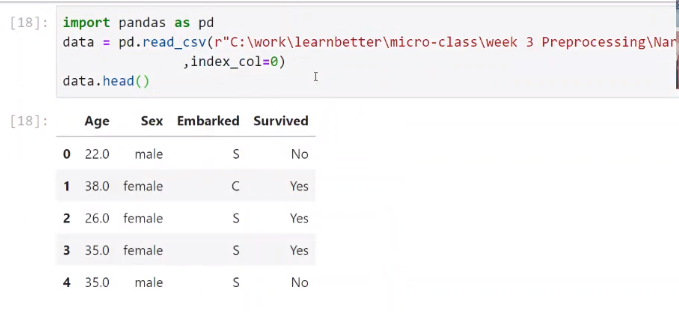
在原本就有索引的情况下read_csv里的参数index_col要设置为0
随机森林可以用于填补缺失值
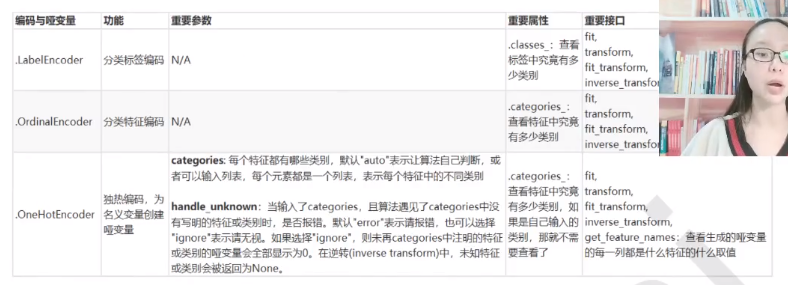
LabelEncoder(标签专用,能将分类转换为分类数值)

OrdinalEncoder(特征专用,能够将分类特征转换为分类数值)

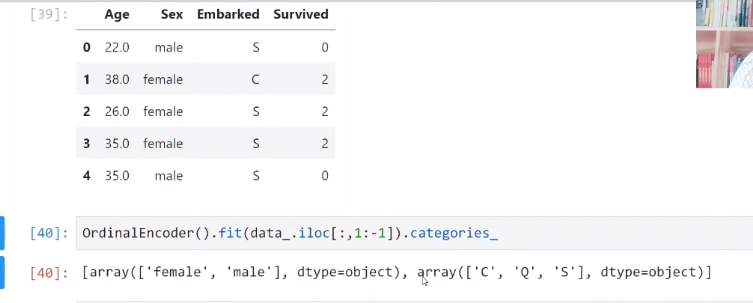
除上述两种Encoder之外,还有OneHotEncoder
数据类型以及常用的统计量

pandas的DataFrame参数的单独操作:

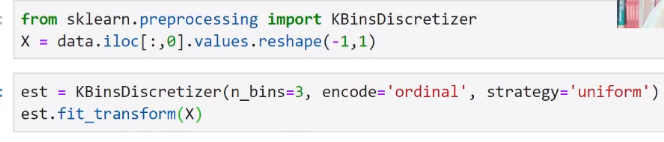
KBinsDiscretizer

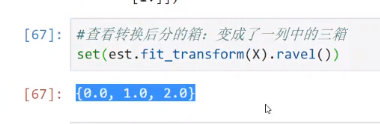
ravel()是指降维的意思
SelectKBest与卡方、F检验、互信息
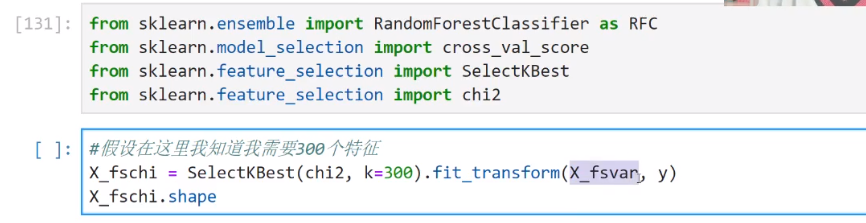
SelectKBest表示选择K个最佳特征
Chi2表示卡方过滤特征(数据必须非负)



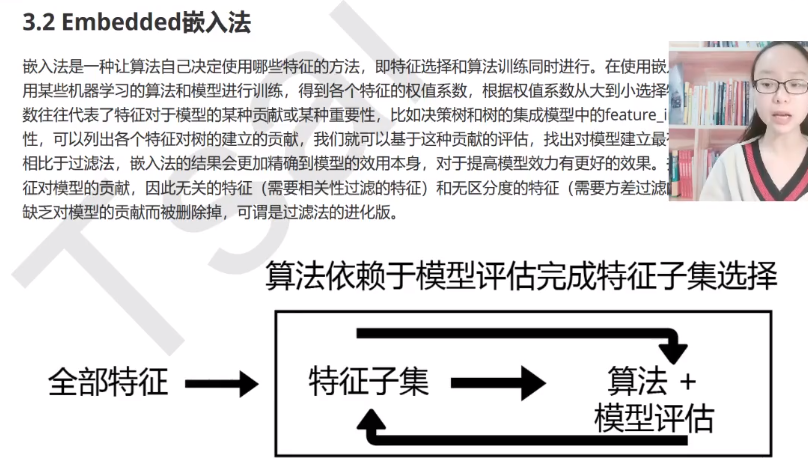
决策树和随机森林有属性feature_importances来显示特征对于模型的某种贡献或重要性
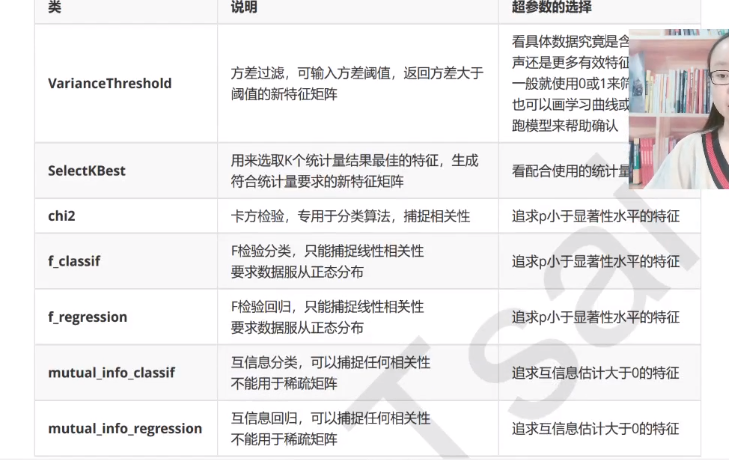
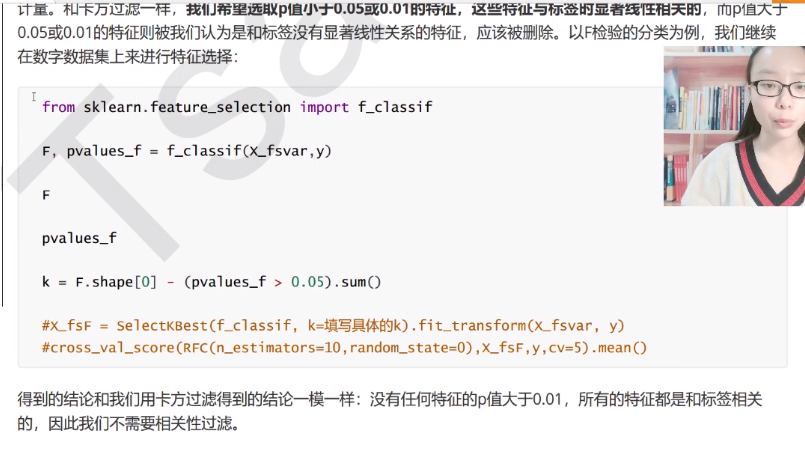
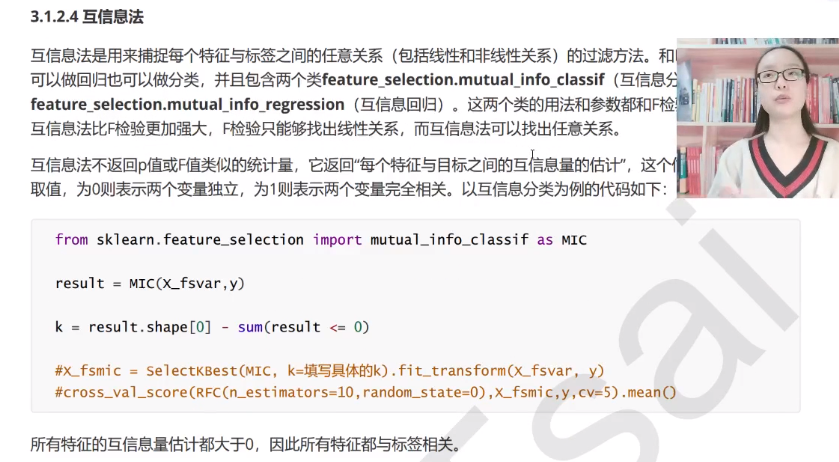
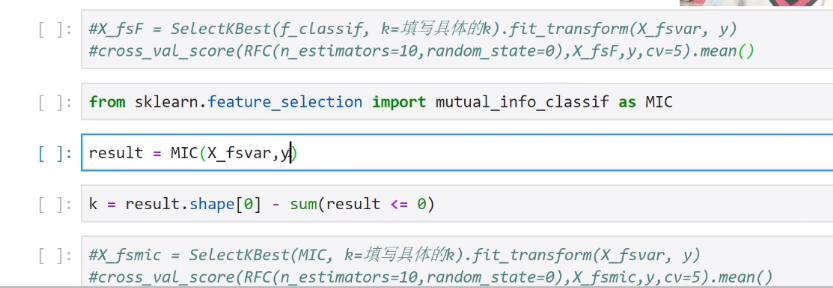
chi2、f检验、互信息本质上都是寻找相关度大的特征。
Embedded嵌入法

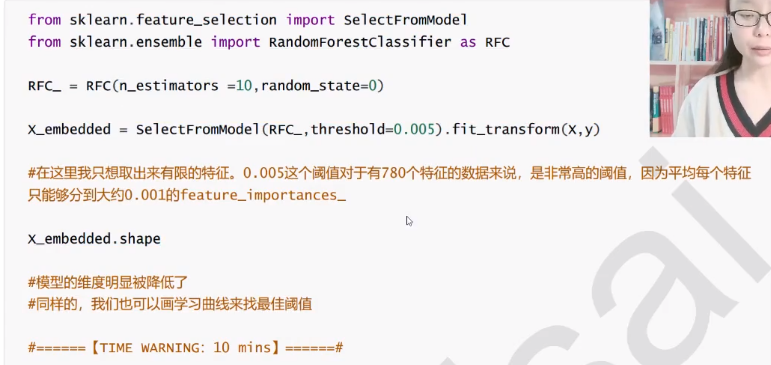
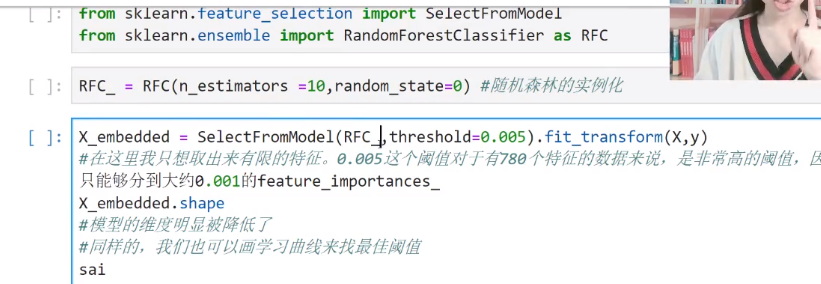
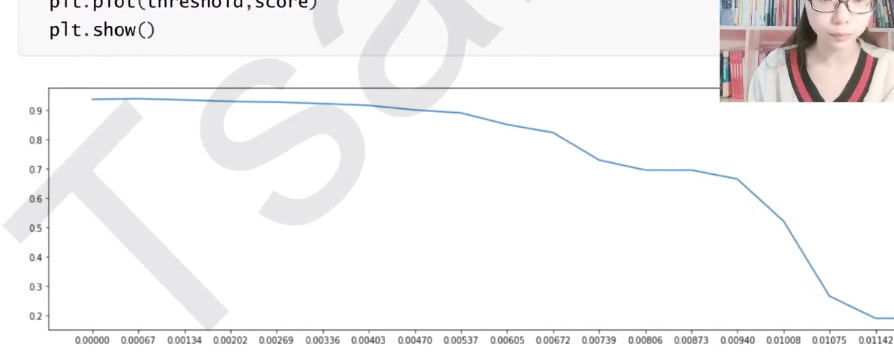
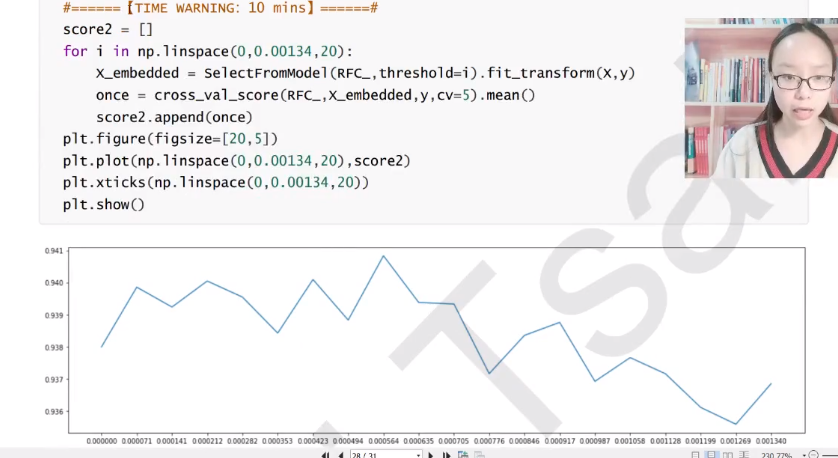
SelectFromModel







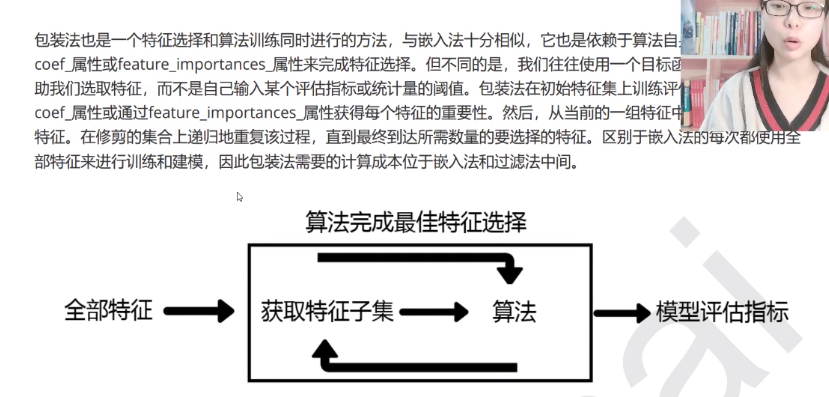
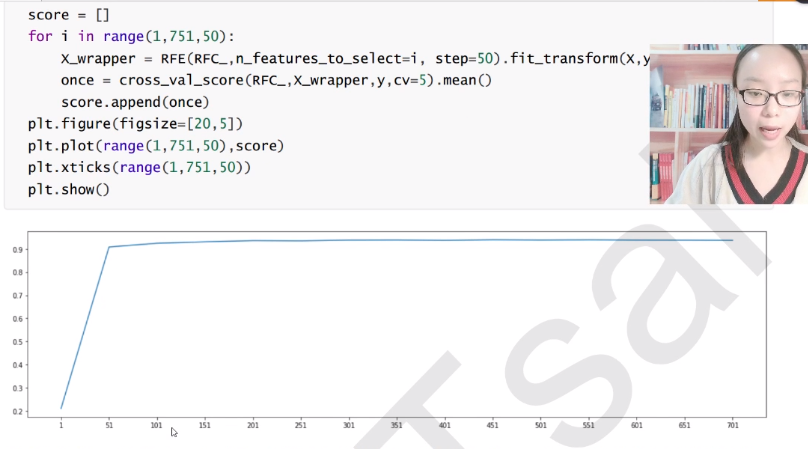
Wrapper包装法(RFE、RFECV)
在大数据量的时候我们一般还是选用过滤法,因为嵌入法计算量太大了。下面介绍包装法(结合了以上两种方法)



Step=50表示每迭代一次帮我删掉50个特征
还有一个RFECV类,类似于RFE,只是在里面要添加cv参数。
特征提取总结
当特征很多的时候先使用方差过滤和互信息法,再用其他的方法。如果使用逻辑回归,优先嵌入法,如果使用支持向量机,优先使用包装法。