k8s 1.15版本学习笔记,总结了尚硅古2019年k8s教程视频的内容,该教程相较于尚硅谷2020年k8s教程视频内容更为详尽
kubernetes组件介绍
MESOS APACHE 分布式资源管理框架 2019-5 Twitter 》 Kubernetes
Docker Swarm 2019-07 阿里云宣布 Docker Swarm 剔除
Kubernetes Google 10年容器化基础架构 borg GO 语言 Borg
特点:
轻量级:消耗资源小
开源
弹性伸缩
负载均衡:IPVS
基础概念: 什么是 Pod 控制器类型 K8S 网络通讯模式
资源清单:资源 掌握资源清单的语法 编写 Pod 掌握 Pod 的生命周期
Pod 控制器:掌握各种控制器的特点以及使用定义方式
服务发现:掌握 SVC 原理及其构建方式
存储:掌握多种存储类型的特点 并且能够在不同环境中选择合适的存储方案(有自己的简介)
调度器:掌握调度器原理 能够根据要求把Pod 定义到想要的节点运行
安全:集群的认证 鉴权 访问控制 原理及其流程
HELM:Linux yum 掌握 HELM 原理 HELM 模板自定义 HELM 部署一些常用插件
运维:修改Kubeadm 达到证书可用期限为 10年 能够构建高可用的 Kubernetes 集群
服务分类
有状态服务:DBMS
无状态服务:LVS APACHE
高可用集群副本数据最好是 >= 3 奇数个
APISERVER:所有服务访问统一入口
CrontrollerManager:维持副本期望数目
Scheduler::负责介绍任务,选择合适的节点进行分配任务
ETCD:键值对数据库 储存K8S集群所有重要信息(持久化) 默认情况下(比较常见的方案)ETCD是放在K8S集群内部被托管的,还有一种方案是在集群外部或者其他节点服务器去构建ETCD集群,然后k8s连接过去
Kubelet:直接跟容器引擎(容器运行时CRI)交互实现容器的生命周期管理
Kube-proxy:负责写入规则至 IPTABLES、IPVS 实现服务映射访问的
COREDNS:可以为集群中的SVC创建一个域名IP的对应关系解析
DASHBOARD:给 K8S 集群提供一个 B/S 结构访问体系
INGRESS CONTROLLER:官方只能实现四层代理,INGRESS 可以实现七层代理
FEDERATION:提供一个可以跨集群中心多K8S统一管理功能
PROMETHEUS:提供K8S集群的监控能力
ELK:提供 K8S 集群日志统一分析介入平台

pod与pod之间的访问,包括svc的负载均衡都需要借助kube proxy,kube proxy默认操作防火墙,去进行pod映射
etcd 的官方将它定位成一个可信赖的分布式键值存储服务,它能够为整个分布式集群存储一些关键数据,协助分布式集群的正常运转
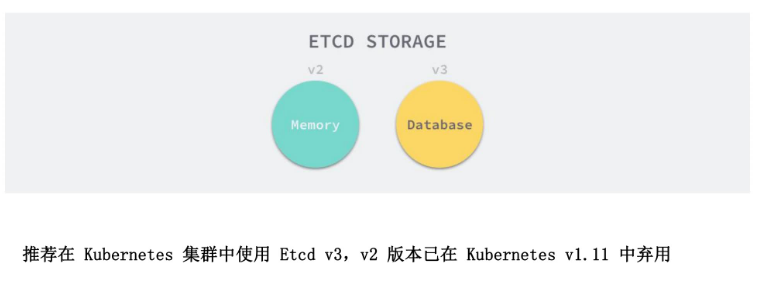
etcd,v2版本将数据存到内存,v3版本将数据存到数据卷
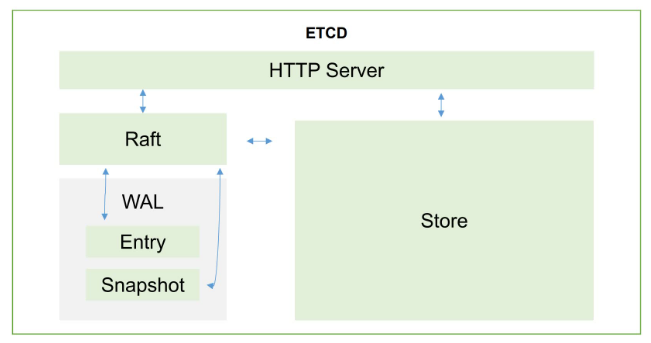
etcd通过http协议进行通讯(k8s也是采取http协议进行C/S结构的开发)
读写信息会存到Raft,WAL是一个预写日志,也就是说如果想对里面的数据进行更改的话,先生成一个日志存一下,并且会定时对日志进行一个完整的备份(完整 + 临时),具体怎么备份的呢?先备份一个大版本x,然后会有一些新的修改,比方说过了一段时间有一个新的子版本x1,又过了一段时间又有一个新的子版本x2,x3…,到达时间以后会将x、x1、x2、…合成一个新的大版本X,以此类推。为啥要这样呢?就是为了防止x1、x2这些小版本太多,可能导致最后还原的时候太费事费时。并且Raft还会实时将日志包括数据写入到本地磁盘中进行持久化。
kube-proxy中的ipvs以及LVS
参考:https://www.cnblogs.com/hongdada/p/9758939.html(IPVS负载均衡)、https://www.jianshu.com/p/4a3496b8006a(ipvsadm命令详解)、http://zh.linuxvirtualserver.org/node/5(LVS中文站点、ipvsadm命令参考)
kubernetes基本概念

在docker中,容器之间是隔离的,ip地址都不一样, 一个应用想通过localhost访问另一个应用是不可能的,除非两个应用合到一个容器中去,变成两个进程
而k8s的pod解决了这个问题:
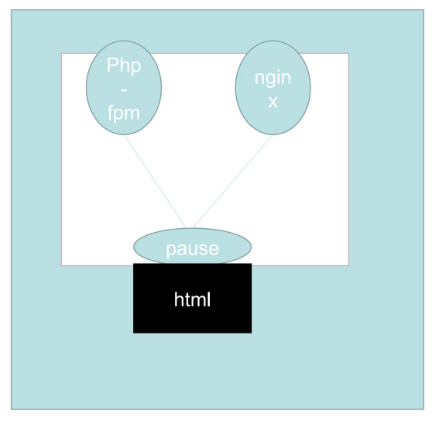
k8s的pod中可以有一个或多个容器,pod中所有容器的ip地址是共享的,因为pod启起来的时候会先启一个叫“pause”的容器,那么其他容器,比如nginx、php使用的网络栈其实都是pause的网络栈,既然是共享了pause的网络栈,那么nginx直接用localhost就可以访问到php,当然同一个pod中容器的端口不能冲突。
并且,同一个pod不仅共享网络栈,还共享数据卷,也就是说上图nginx和php访问的是同一个数据卷。
Pod
pod分为:
-
自主式 Pod
Pod退出了,此类型的Pod不会被创建
-
控制器管理的 Pod
在控制器的生命周期里,始终要维持Pod的副本数目
控制器
什么是控制器
Kubernetes中内建了很多controller(控制器),这些相当于一个状态机,用来控制Pod的具体状态和行为
控制器类型
-
ReplicationController 和 ReplicaSet
-
Deployment
-
HPA(
ReplicationController & ReplicaSet & Deployment > HPA(Horizontal Pod AutoScaling)) -
StatefullSet
-
DaemonSet
-
Job,Cronjob
ReplicationController、ReplicaSet
ReplicationController 用来确保容器应用的副本数始终保持在用户定义的副本数,即如果有容器异常退出,会自动创建新的 Pod 来替代;而如果异常多出来的容器也会自动回收。在新版本的 Kubernetes 中建议使用 ReplicaSet 来取代 ReplicationController。
ReplicaSet 跟 ReplicationController 没有本质的不同,只是名字不一样,并且ReplicaSet 支持集合式的 selector;这里的selector是通过标签,通过labels去进行选择集控制,对于RS来说他支持大量的算法来进行标签的匹配,RC是没有的
虽然 ReplicaSet 可以独立使用,但一般还是建议使用 Deployment 来自动管理ReplicaSet ,这样就无需担心跟其他机制的不兼容问题(比如 ReplicaSet 不支持rolling-update 但 Deployment 支持)。
案例:
apiVersion: extensions/v1beta1
kind: ReplicaSet
metadata:
name: frontend
spec:
replicas: 3
selector:
matchLabels:
# key为tier,value为frontend
tier: frontend
template:
# template下写了一个类似之前我们创建pod的yaml,很好理解,因为rs管理着pod,所以pod的yaml可以嵌套在rs中。之后这种嵌套的思想要有,因为后面经常会用到嵌套
metadata:
labels:
tier: frontend
spec:
containers:
- name: php-redis
image: gcr.io/google_samples/gb-frontend:v3
env:
- name: GET_HOSTS_FROM
value: dns
ports:
- containerPort: 80
由于是RS,因此可以使用kubectl create xxx -f xxx.yaml来创建
创建之后可以使用kubectl get pod --show-labels来查看labels标签
如果我们想通过命令行给pod添加标签(按上面yaml来看这里原来的标签是tier=frontend,我们给他加一个tier1=frontend1),可以使用kubectl label pod xxx tier1=frontend1来做添加;
如果我们想修改pod的标签(比方说把原标签tier=frontend改成tier=frontend1),可以使用kubectl label pod xxx tier=frontend1 --overwrite=True来做修改,注意这里的--overwrite=True,因为原标签中tier这个key已经存在了,所以必须加--overwrite=True才能做出修改
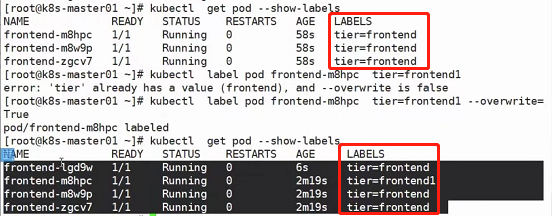
可以看到,修改了标签之后,副本数居然多了一个,以下做出解释:
看到上方yaml文件,我们的RS控制器,通过template模板,把pod创建出来,那么他怎么知道哪些pod属于自己呢?这里有一个匹配标签matchLabels,如果pod的labels中有和matchLabels中一样的标签,那就说明这个pod是属于这个RS的。所以上图为什么我们定义了副本数为3个,他会创建出4个pod呢?是因为原本确实是3个pod副本,直到我们修改了其中一个pod的labels标签,那么RS认为这个pod已经不属于我了,那么就会再创建一个新的pod出来,也就造成了上图出现4个pod的现象。所以也延伸出来一个知识点:RS的副本数监控是以标签为基础的
并且此时我们执行删除RS:
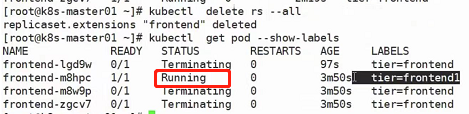
会发现有一个pod没有被删除,原因就是由于标签不同,RS认为这个pod不是我的,所以我不管
当然如果执行kubectl delete pod --all,所有pod都会被删除
RS与Deployment的关联
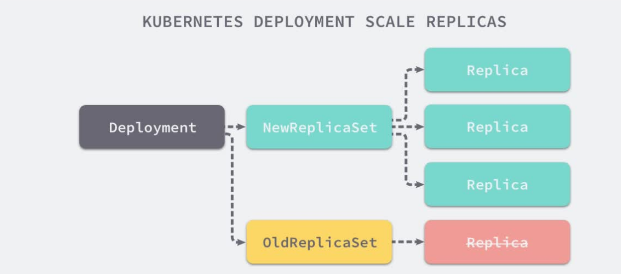
Deployment(ReplicaSet)
Deployment 为 Pod 和 ReplicaSet 提供了一个声明式定义 (declarative) 方法,用来替代以前的 ReplicationController 来方便的管理应用。
这里的声明式定义 (declarative)方法我们来解释一下:
-
命令式编程:它侧重于如何实现程序,就像我们刚接触编程的时候那样,我们需要把程序的实现过程按照逻辑结果一步步写下来
-
声明式编程:它侧重于定义想要什么,然后告诉计算机/引擎,让他帮你去实现
sql语句就是一个典型的声明式编程的思想,我们不需要知道创建表的细节,只需要告诉数据库我们要创建表,他就能给我们进行创建
声明式编程有一个特点就是:可以重复执行(幂等,幂等就是函数的幂次方就是函数本体),举例来讲就是我可以重复的告诉引擎我要干什么,但引擎不会因此一遍又一遍的从头开始重复执行我的命令,他只会朝着目标一直前进,最终达到的目标都是那一个;但是命令式编程就不一样了,如果重复告诉引擎我要干什么,引擎就会因此从头开始重新执行一次命令
显然,声明式编程对用户友好,但对程序员不友好;命令式编程则反过来
那么对于deployment和rs来讲:
-
deployment就是典型的声明式编程
使用
kubectl apply xxx会更好,虽然也能使用kubectl create xxx,但是不推荐,会有提示信息 -
rs就是命令式编程
使用
kubectl create xxx会更好,虽然也能使用kubectl apply xxx,但是不推荐,会有提示信息
Deployment典型的应用场景包括:
-
定义 Deployment 来创建 Pod 和 ReplicaSet
-
滚动升级和回滚应用
-
扩容和缩容
-
暂停和继续 Deployment
把Deployment下的RS挂起就暂停了(补充知识点:不光是RS可以挂起,pod自带挂起操作);同理继续
Deployment 和 ReplicaSet 的关系:
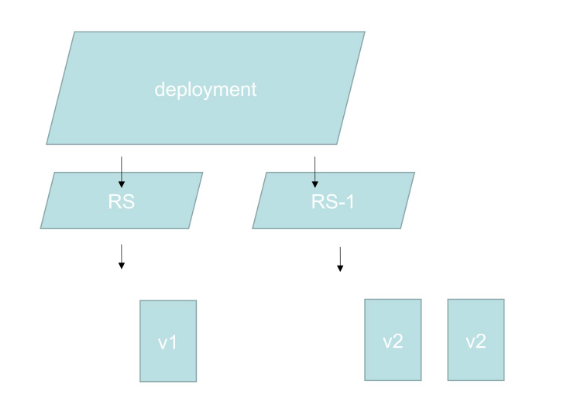
首先RS是由Deployment创建出来的,那么怎么做滚动扩容呢?
首先比方说deployment有一个RS,RS下有一个或多个pod,那么比方说这些个pod中应用的版本是v1,现在我要滚动更新,deployment会新创建一个RS-1,RS-1下会有一个或多个新创建的pod,这些个pod中应用版本为v2,那么随着v2版本的pod一个一个被创建,那边v1版本的pod也会一个一个的删除,直到删干净,当然此时v2版本的pod数也会为用户指定的副本数。
注意,RS本身是不删的,原因是如果做滚动回滚,RS就又会被用到,所以不删。
滚动回滚同理滚动更新。
部署一个简单的deployment案例
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
使用kubectl create -f xxx.yaml --record创建deployment,--record参数可以记录命令,我们可以很方便的查看每次revision的变化
查看历史RS
kubectl get rs
扩容
kubectl scale deployment nginx-deployment --replicas 10
如果集群支持HPA(horizontal pod autoscaling)的话,还可以为deployment设置自动扩展
kubectl autoscale deployment nginx-deployment --min=10 --max=15 --cpu-percent=80
更新镜像也比较简单
假如我们现在想要让nginx pod使用nginx:1.9.1的镜像来代替原来的nginx:1.7.9的镜像
# 注意这里的deployment/nginx-deployment,意思是deployment下名为nginx-deployment的deployment
kubectl set image deployment/nginx-deployment nginx=nginx:1.9.1
回滚
# 注意这里的deployment/nginx-deployment,意思是deployment下名为nginx-deployment的deployment
kubectl rollout undo deployment/nginx-deployment
查看rollout的状态
# 注意这里的deployment/nginx-deployment,意思是deployment下名为nginx-deployment的deployment
kubectl rollout status deployment/nginx-deployment
编辑
可以使用edit命令来编辑Deployment
# 注意这里的deployment/nginx-deployment,意思是deployment下名为nginx-deployment的deployment
kubectl edit deployment/nginx-deployment
Deployment更新策略
Deployment可以保证在升级时只有一定数量的Pod是down的。默认的,它会确保至少有比期望的Pod数量少一个是up状态(最多1个不可用)
Deployment同时也可以确保只创建出超过期望数量的一定数量的Pod。默认的,它会确保最多比期望的Pod数量多一个的Pod是up的(最多1个surge)
未来的Kuberentes版本中,将从1-1变成25%-25%(当然这个阈值也可以通过资源清单里面的描述去修改)
kubectl describe deployments
Rollover(多个rollout并行)
假如创建了一个有5个niginx:1.7.9 replica的Deployment,但是当还只有3个nginx:1.7.9的replica创建出来的时候就开始更新含有5个nginx:1.9.1 replica的Deployment。在这种情况下,Deployment会立即杀掉已创建的3个nginx:1.7.9的Pod,并开始创建nginx:1.9.1的Pod。它不会等到所有的5个nginx:1.7.9的Pod都创建完成后才开始改变航道
回退Deployment
kubectl set image deployment/nginx-deployment nginx=nginx:1.91
## 可以用kubectl rollout status命令查看Deployment是否完成。如果rollout成功完成,kubectl rollout status将返回一个0值的 Exit Code
kubectl rollout status deployments nginx-deployment
kubectl get pods
kubectl rollout history deployment/nginx-deployment
kubectl rollout undo deployment/nginx-deployment
## 可以使用 --revision 参数指定某个历史版本
kubectl rollout undo deployment/nginx-deployment --to-revision=2
## 暂停deployment的更新
kubectl rollout pause deployment/nginx-deployment
$ kubectl rollout status deploy/nginx
Waiting for rollout to finish: 2 of 3 updated replicas are available...
deployment "nginx" successfully rolled out
$ echo $?
0

使用kubectl rollout history xxx可以看到滚动更新的历史记录,REVISION是指版本,这里的CHANGE-CAUSE为none是因为最初kubectl apply -f xxx.yaml的时候没有在末尾加上--record,如果加上了,这里就能看到信息了:

但是有一个问题,加入最开始的时候是v1版本的,更新了一次变成了v2版本,之后又更新了一次变成了v3版本,这个时候我们如果想回到v1版本怎么办?
执行两次kubectl rollout undo xxx吗?不行,因为一次回退确实能从v3版本回退到v2,但是如果再执行一次就又会变成v3,因为回退的是上一个版本。此时就需要借助--to-revision参数了,完整代码模板:kubectl rollout undo xxx --to-revision=1表示回退到REVISION为1的版本
清理Policy
您可以通过设置.spec.revisonHistoryLimit项来指定deployment最多保留多少revision历史记录。默认的会保留所有的revision;如果将该项设置为0,Deployment就不允许回退了
这个也很好理解,因为pod由RS管理,如果历史版本的RS没有了,自然也回滚不了了
HPA(HorizontalPodAutoScale)
应用的资源使用率通常都有高峰和低谷的时候,如何削峰填谷,提高集群的整体资源利用率,让service中的Pod个数自动调整呢?这就有赖于Horizontal Pod Autoscaling了,顾名思义,使Pod水平自动缩放
Horizontal Pod Autoscaling 仅适用于 Deployment 和 ReplicaSet ,在 V1 版本中仅支持根据 Pod的 CPU 利用率扩缩容,举例来讲就是:
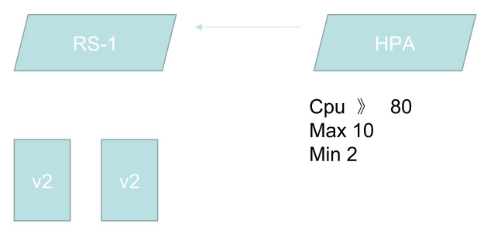
HPA会去监控资源的利用率,如果cpu利用率大于80%,那么v2的pod就会扩容,直到达到数量为MAX 10为止,反之如果cpu利用率小于80%,那么v2的pod就会被回收,直到MIN 2为止。这样就能达到水平自动扩展的功能。
在 v1alpha 版本中,还可以支持根据内存和用户自定义的 metric 进行扩缩容
StatefullSet
StatefulSet作为Controller为Pod提供唯一的标识。它可以保证部署和scale的顺序
StatefulSet 是为了解决有状态服务的问题(对应 Deployments 和 ReplicaSets 是为无状态服务而设计),其应用场景包括:
- 稳定的持久化存储,即 Pod 重新调度后还是能访问到相同的持久化数据,基于 PVC 来实现
- 稳定的网络标志,即 Pod 重新调度后其 PodName 和 HostName 不变,基于 Headless Service(即没有 Cluster IP 的 Service )来实现
- 有序部署,有序扩展,即 Pod 是有顺序的,在部署或者扩展的时候要依据定义的顺序依次依次进行(即从 0 到 N-1,在下一个 Pod 运行之前所有之前的 Pod 必须都是 Running 和 Ready 状态),基于 init containers 来实现
- 有序收缩,有序删除(即从 N-1 到 0)
DaemonSet
DaemonSet 确保全部(或者一些)Node 上运行一个 Pod 的副本。当有 Node 加入集群时,也会为他们新增一个 Pod 。当有 Node 从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod
注意是运行一个Pod副本,不是多个,如果你想在一个node上运行多个daemonset的pod副本,可以通过创建多个daemonset的方式来实现
使用 DaemonSet 的一些典型用法:
- 运行集群存储 daemon,例如在每个 Node 上运行 glusterd、ceph
- 在每个 Node 上运行日志收集 daemon,例如fluentd、logstash
- 在每个 Node 上运行监控 daemon,例如 Prometheus Node Exporter、collectd、Datadog代理、New Relic代理,或Ganglia gmond
案例:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: deamonset-example
labels:
app: daemonset
spec:
selector:
matchLabels:
name: deamonset-example
template:
metadata:
labels:
name: deamonset-example
spec:
containers:
- name: daemonset-example
image: wangyanglinux/myapp:v1
DaemonSet属于命令式,所以我们最好用kubectl create xxx -f xxx.yaml去创建
创建完之后我们发现虽然所有node节点上都有了相应的pod(且副本数定死了就是1个),但是master节点上没有,这是因为master节点上使用了污点策略
Job
Job 负责批处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个 Pod 成功结束
什么叫做一个或多个呢?比方说有一个脚本,这个脚本正常执行完毕后以0退出,这个时候job就会记录正常退出次数为1,那我们是可以定义job成功退出的次数的,比如定义为4,脚本正常执行完毕退出一次就加1,又正常退出一次再加1,直到加到4为止,之后这个job成功结束退出,意思就是该job已经执行完成了,不需要再运行。以此延伸出job的生命周期也就等于里面的pod运行多少多少次成功之后结束
特殊说明
spec.template格式同Pod- RestartPolicy仅支持Never或OnFailure
- 单个Pod时,默认Pod成功运行后Job即结束
.spec.completions标志Job结束需要成功运行的Pod个数,默认为1.spec.parallelism标志并行运行的Pod的个数,默认为1spec.activeDeadlineSeconds标志失败Pod的重试最大时间,超过这个时间不会继续重试
案例:
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
metadata:
name: pi
spec:
containers:
- name: pi
image: perl
command: ["perl","-Mbignum=bpi","-wle","print bpi(2000)"]
restartPolicy: Never
注意,由于重启策略是Never,因此如果任务执行失败了,需要将pod删除,此时他会自动再起一个pod,就会再次执行了
使用kubectl get job可以查看到任务是否执行完成
使用kubectl log xxx查看pod日志
Cronjob
Cron Job 管理基于时间的 Job,即:
- 给定时间点只运行一次
- 周期性地在给定时间点运行
deployment通过创建RS来对pod进行管理,cronjob通过创建pod进行管理
使用前提条件:当前使用的Kubernetes集群,版本 >= 1.8(对CronJob)。对于先前版本的集群,版本 < 1.8,启动API Server时,通过传递选项--runtime-config=batch/v2alpha1=true可以开启batch/v2alpha1API
典型的用法如下所示:
- 在给定的时间点调度Job运行
- 创建周期性运行的Job,例如:数据库备份、发送邮件
CronJob Spec
-
spec.template格式同Pod -
RestartPolicy仅支持Never或OnFailure
-
单个Pod时,默认Pod成功运行后Job即结束
-
.spec.completions标志Job结束需要成功运行的Pod个数,默认为1 -
.spec.parallelism标志并行运行的Pod的个数,默认为1 -
spec.activeDeadlineSeconds标志失败Pod的重试最大时间,超过这个时间不会继续重试 -
.spec.schedule:调度,必需字段,指定任务运行周期,格式同Cron -
.spec.jobTemplate:Job模板,必需字段,指定需要运行的任务,格式同Job -
.spec.startingDeadlineSeconds:启动Job的期限(秒级别),该字段是可选的。如果因为任何原因而错过了被调度的时间,那么错过执行时间的Job将被认为是失败的。如果没有指定,则没有期限 -
.spec.concurrencyPolicy:并发策略,该字段也是可选的。它指定了如何处理被Cron Job创建的Job的并发执行。只允许指定下面策略中的一种:- Allow(默认):允许并发运行Job
- Forbid:禁止并发运行,如果前一个还没有完成,则直接跳过下一个
- Replace:取消当前正在运行的Job,用一个新的来替换
注意,当前策略只能应用于同一个Cron Job创建的Job。如果存在多个Cron Job,它们创建的Job之间总是允许并发运行。
-
.spec.suspend:挂起,该字段也是可选的。如果设置为true,后续所有执行都会被挂起。它对已经开始执行的Job不起作用。默认值为false。 -
.spec.successfulJobsHistoryLimit和.spec.failedJobsHistoryLimit:历史限制,是可选的字段。它们指定了可以保留多少完成和失败的Job。默认情况下,它们分别设置为3和1。设置限制的值为0,相关类型的Job完成后将不会被保留。
部署案例:
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
使用kubectl apply -f xxx.yaml创建
使用kubectl get cronjob查看
注意,此时如果使用kubectl get job也可以看到通过cronjob创建出来的job,这是因为Cron Job 其实就是管理基于时间的 Job
注意,删除 cronjob 的时候不会自动删除job,这些job可以用kubectl delete job来删除
使用kubectl log xxx可以查看具体执行信息
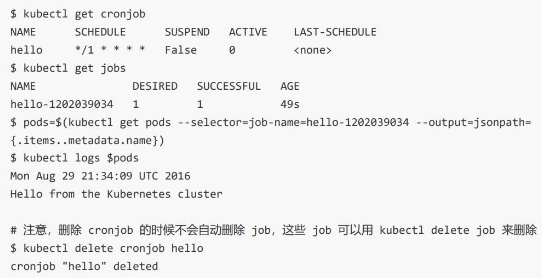
cronjob本身的一些限制
创建Job操作应该是幂等的
因为cronjob中可以重复的去循环一些任务,如果操作不是幂等的,此时比如并发策略选择了Allow或Forbid或Replace,就可能第二个会影响第一个运行的结果,那这样的话如果再去重复运行得到的结果可能就不是我们想要的结果。
还有一点,cronjob他运行成功并不太好去做判断,原因是cronjob他运行的是job,job的成功可以被判断,但是cronjob无法去链接到job的成功状态,cronjob只会定期的去创建job,仅此而已。
Service
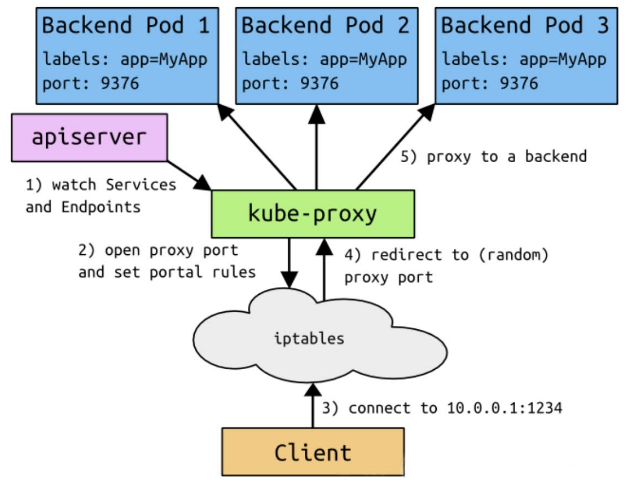
上图的解释比较复杂,其实图中的说明已经可以见名知意了,想要更详细的解释可以直接看尚硅谷Kubenetes教程(k8s从入门到精通)6-1_尚硅谷_Service - 定义第17分35秒到第19分钟
注意,一组pod是可以对应到多个svc的(多对多的关系),只要标签匹配就行。
概念
Kubernetes Service定义了这样一种抽象:一个Pod的逻辑分组,一种可以访问它们的策略 —— 通常称为微服务。这一组Pod能够被Service访问到,通常是通过Label Selector
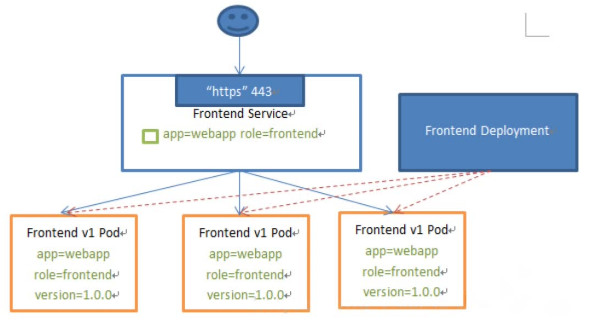
Service能够提供负载均衡的能力,但是在使用上有以下限制:
只提供4层负载均衡能力,而没有7层功能(可通过ingress实现),但有时我们可能需要更多的匹配规则来转发请求,这点上4层负载均衡是不支持的
服务发现与负载均衡
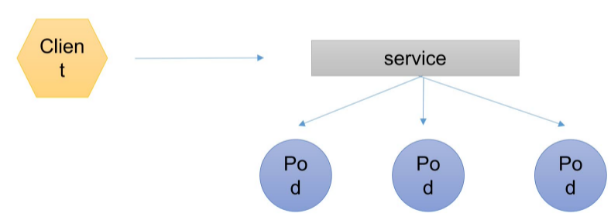
比方说我们的客户端需要去访问一组pod,如果这些pod不相关的话是无法使用service进行统一代理的,pod必须要有相关性,比方说是同一个RS、RC或Deployment创建的,或者拥有同一组标签,被service所收集到(换句话说,service去收集pod是通过标签来收集的,pod标签相对于service的标签多了可以少了不行),收集到之后service会有自己的ip和port,那么客户端通过service的ip和port即可间接访问到相应的pod,并且service会有自己的负载均衡算法(roundrobin),来将请求均匀地分摊到各个pod。
部署示例
试想一下我们要部署这样的一套东西:
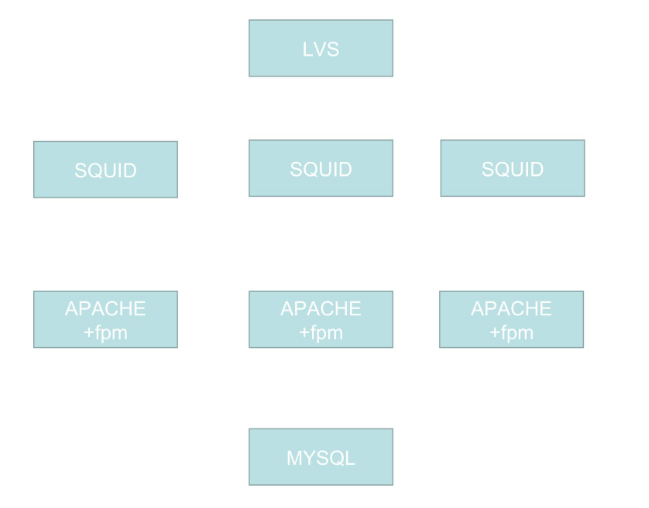
一个LVS做负载均衡(换用haproxy或nginx也可),三个SQUID作为前端,三个APACHE+fpm作为后端,一个MYSQL作为数据存储
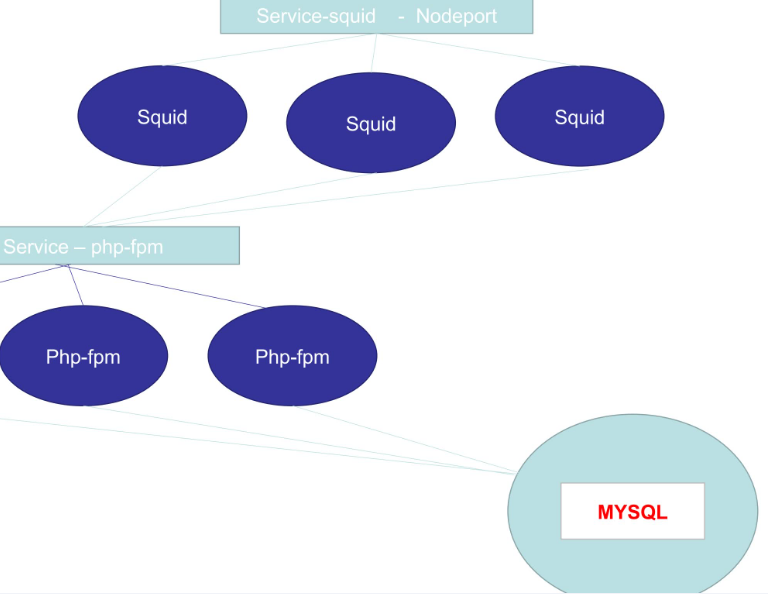
mysql作为有状态应用,可以在statefullset中进行部署,但是部署集群化的mysql对于k8s来说还是有一点困难的,因此这里我们部署一个单节点mysql。而由于mysql部署在statefullset中,ip地址是不变的,且k8s内部是一个扁平化网络,pod之间是可以直接访问到的,因此php-fpm的一组pod直接访问mysql是没有问题的。
现在重点来了,squid想要配置反向代理到php-fpm怎么办呢?php-fpm有三个,需要写三台机器,更麻烦的是,php-fpm这些pod会发生退出然后重新创建的情况,在新建pod的过程中,ip地址会发生变化,那么这个时候要么手动修改ip地址绑定,要么写脚本去修改ip地址绑定,这些都是很麻烦的,而且虽然我们可以通过将php-fpm部署到statefullset中来变相解决这个问题,但是对于一个无状态应用来讲,没什么意义。
那么怎么办呢?可以使用service,如上图,使用一个php-fpm的service,然后squid直接访问php-fpm的service即可。
同理squid的一组pod也可以有一个自己的service,并且由于squid是需要对外暴露访问的,因此可以将type设置为nodeport,或者使用ingress来做也可以。
Service的类型
Service在K8s中有以下四种类型:
-
ClusterIp:默认类型,自动分配一个仅Cluster内部可以访问的虚拟IP
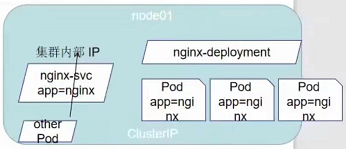
只能被集群内部的应用或者node节点本身所访问
-
NodePort:在ClusterIP基础上为Service在每台机器上绑定一个端口,这样就可以通过: NodePort来访问该服务
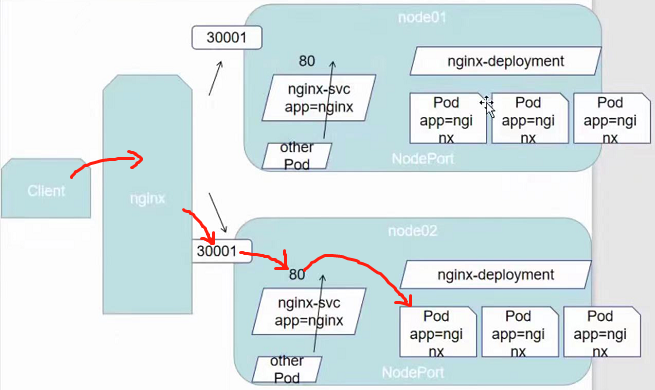
上图是一种高可用的架构,首先他第一层使用了nginx做负载均衡,保证了node节点的高可用(如果不加这一层直接访问node的话万一node节点挂掉了服务也就全部中断了);然后第二层又用了service做到了pod的高可用。
nodeport使得node节点向外暴露了一个端口30001,而30001映射到了node节点内部的svc的80端口,svc再做负载均衡最终访问到pod,也就是上图红色箭头的访问路径。
-
LoadBalancer:在NodePort的基础上,借助cloud provider创建一个外部负载均衡器,并将请求转发到: NodePort
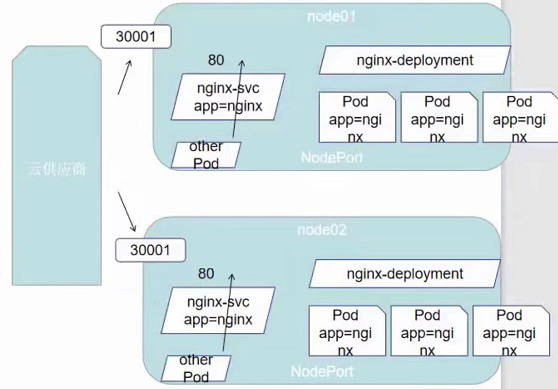
该模式与上面nodeport配合负载均衡器实现的高可用架构只有一个区别,那就是nginx负载均衡器不需要我们自己实现了,我们要做的就只需要引入云供应商,让他给我们去暴露服务接口即可。也就是说只要采用loadbalancer,他就会自动去云服务器那边去注册,并且把对应暴露端口填写进去,实现一个自动化的流程,但是既然用到了云供应商的调度方案,那显然是要收费的
-
ExternalName:把集群外部的服务引入到集群内部来,在集群内部直接使用。没有任何类型代理被创建,这只有kubernetes 1.7或更高版本的kube-dns才支持
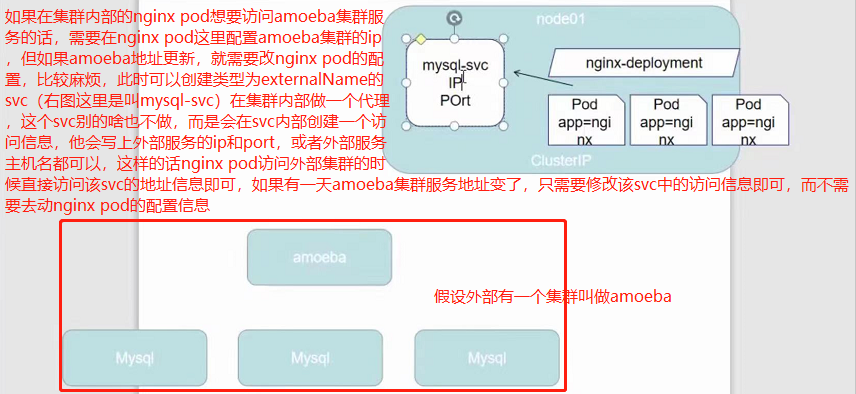
VIP和Service代理
在Kubernetes集群中,每个Node运行一个kube-proxy进程。kube-proxy负责为Service实现了一种VIP(虚拟IP)的形式,而不是ExternalName的形式。在Kubernetes v1.0版本,代理完全在userspace。在Kubernetes v1.1版本,新增了iptables代理,但并不是默认的运行模式。从Kubernetes v1.2起,默认就是iptables代理。在Kubernetes v1.8.0-beta.0中,添加了ipvs代理在Kubernetes 1.14版本开始默认使用ipvs代理在Kubernetes v1.0版本,Service是“4层”(TCP/UDP over IP)概念。在Kubernetes v1.1版本,新增了IngressAPI(beta版),用来表示“7层”(HTTP)服务
为何不使用round-robin DNS?
因为DNS会在很多客户端中进行缓存,当服务去访问,DNS进行域名解析的时候,解析完成之后得到地址访问了之后很多服务不会对DNS的解析进行清除缓存,也就是说一旦有了DNS解析的地址信息之后,不管之后怎么访问,一直都将会是这个地址信息,那这里的负载均衡也就失效了,因此肯定不能通过设置DNS去做负载均衡的,只能将他作为一种辅助手段
代理模式的分类
Ⅰ、userspace代理模式
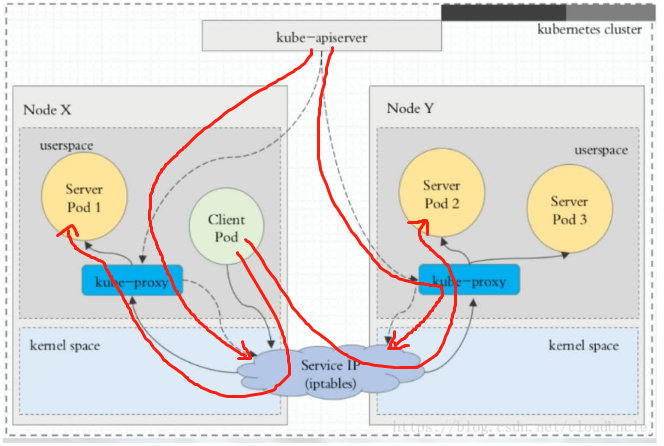
客户端访问pod,不管是访问Node X中的pod还是Node Y中的pod都需要经过iptables和kube-proxy,包括kube-apiserver也需要监控kube-proxy去做服务的更新和端点维护,可见kube-proxy压力是很大的
Ⅱ、iptables代理模式
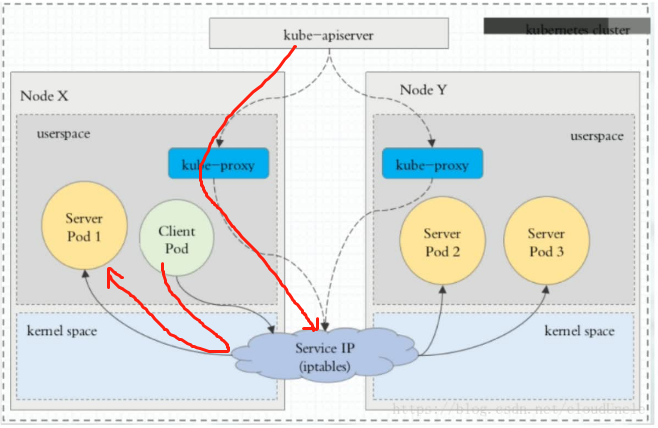
iptables代理模式下kube-proxy压力大大减少,client访问pod只需要经过iptables就行,不需要再经过kube-proxy了,效率也大大提升
Ⅲ、ipvs代理模式(★)
这种模式,kube-proxy会监视KubernetesService对象和Endpoints,调用netlink接口以相应地创建ipvs规则并定期与KubernetesService对象和Endpoints对象同步ipvs规则,以确保ipvs状态与期望一致。访问服务时,流量将被重定向到其中一个后端Pod
与iptables类似,ipvs于netfilter的hook功能,但使用哈希表作为底层数据结构并在内核空间中工作。这意味着ipvs可以更快地重定向流量,并且在同步代理规则时具有更好的性能。此外,ipvs为负载均衡算法提供了更多选项,例如:
- rr:轮询调度
- lc:最小连接数
- dh:目标哈希
- sh:源哈希
- sed:最短期望延迟
- nq:不排队调度
注意:ipvs模式假定在运行kube-proxy之前在节点上都已经安装了IPVS内核模块。当kube-proxy以ipvs代理模式启动时,kube-proxy将验证节点上是否安装了IPVS模块,如果未安装,则kube-proxy将回退到iptables代理模式。
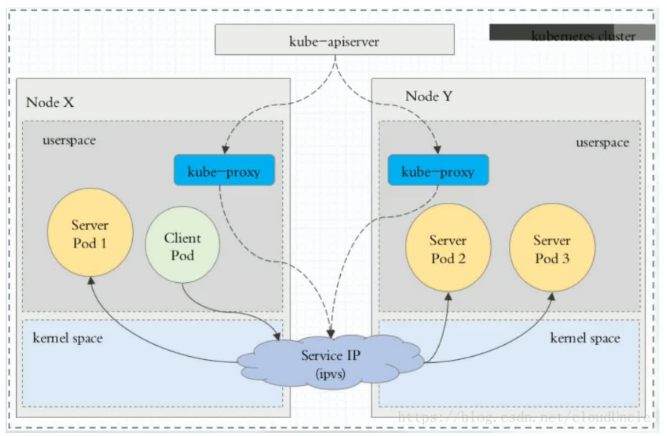
我们发现ipvs的架构跟iptables基本一样,只是将iptables换成了ipvs
使用命令ipvsadm -Ln可以查看ipvs的代理:
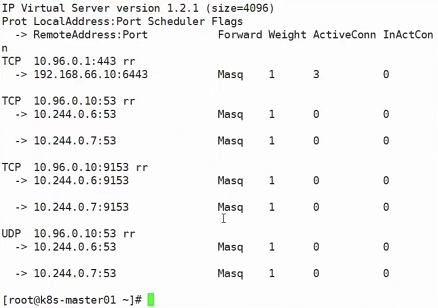
上图的rr就是负载均衡机制(round robin),说明ipvs、iptables、userspace这些模块除了做代理,还做负载均衡
上图的10.96.0.1:443 -> 192.168.66.10:6443的意思非常显而易见,也就是发往10.96.0.1:443的请求会被转发到192.168.66.10:6443
再来看看svc:

这个svc的cluster-ip就是10.96.0.1,那么他是怎么被ipvs代理的现在就非常清楚了
ClusterIP
clusterIP主要在每个node节点使用iptables(目前主流的代理都是ipvs,如果使用ipvs进行代理了,那这里的每个节点使用的也是ipvs),将发向clusterIP对应端口的数据,转发到kube-proxy中。然后kube-proxy自己内部实现有负载均衡的方法,并可以查询到这个service下对应pod的地址和端口,进而把数据转发给对应的pod的地址和端口
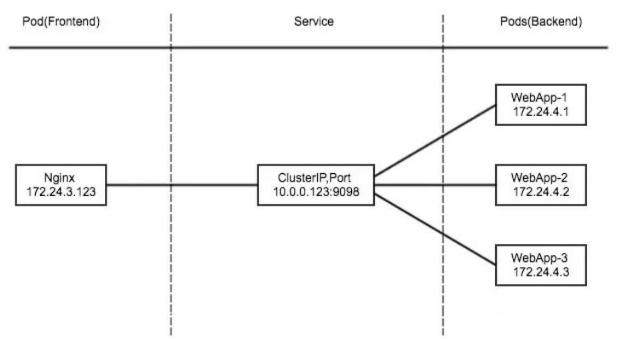
为了实现图上的功能,主要需要以下几个组件的协同工作:
-
apiserver
用户通过kubectl命令向apiserver发送创建service的命令,apiserver接收到请求后将数据存储到etcd中
-
kube-proxykubernetes的每个节点中都有一个叫做
kube-porxy的进程,这个进程负责感知service,pod的变化,并将变化的信息写入本地的iptables规则中简单来讲就是apiserver收到请求想要修改etcd中的数据,
kube-proxy监听etcd中数据的变化,一旦有变化就将数据写入本地ipvs(或iptables或userspace),为什么是本地的呢?因为每一个node节点都有自己的kube-proxy的进程存在 -
iptables(或ipvs)
使用NAT等技术将virtualIP的流量转至endpoint(后端服务的真实端点信息)中
案例:
首先创建deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deploy
namespace: default
spec:
replicas: 3
selector:
matchLabels:
app: myapp
release: stabel
template:
metadata:
labels:
app: myapp
release: stabel
env: test
spec:
containers:
- name: myapp
image: wangyanglinux/myapp:v2
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
创建svc:
apiVersion: v1
kind: Service
metadata:
name: myapp
namespace: default
spec:
type: ClusterIP
selector:
app: myapp
release: stabel
ports:
- name: http
port: 80
targetPort: 80
注意,svc也是通过标签匹配pod,如果svc定义了一个与目标pod集群标签不一致的标签,那么这个svc的后端是对应不到目标pod集群的,此时访问该svc显然是访问不到目标pod集群的,我们还可以通过使用ipvsadm -Ln查看代理来知晓svc是否真的代理到了目标pod集群:

如果没有代理到,则会出现上图现象,那么像上图这样只出现了svc自己的ip和port的情况下,显然svc是没有代理到pod的
Headless Service
注意,无头服务也是一种ClusterIP,只不过是一种特殊的ClusterIP而已
有时不需要或不想要负载均衡,以及单独的Service IP。遇到这种情况,可以通过指定ClusterIP(spec.clusterIP)的值为“None”来创建Headless Service。这类Service并不会分配Cluster IP,kube-proxy不会处理它们,而且平台也不会为它们进行负载均衡和路由。
通过这种svc可以解决hostname和podname变化的问题
案例:
apiVersion: v1
kind: Service
metadata:
name: myapp-headless
namespace: default
spec:
selector:
app: myapp
clusterIP: "None"
ports:
- port: 80
targetPort: 80
使用kubectl get svc:
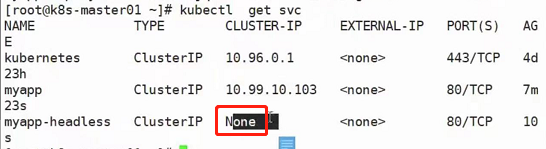
可以看到他的cluster-ip是None
对于svc,一旦svc创建成功了,他会写到COREDNS中去,使用kubectl get pod -n kube-system:
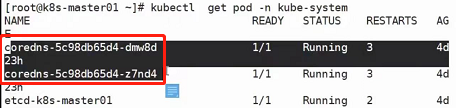
可以看到coredns的pod
svc创建成功之后会有一个主机名被写入到coredns,他的写入格式体就是:svc名称.当前名称空间名称.集群域名.。
使用dig命令利用coredns的ip地址进行解析示例:
dig -t A myapp-headless.default.svc.cluster.local. @10.96.0.10
最后的@10.96.0.10为coredns的ip地址(可通过kubectl get pod -n kube-system -o wide查看获得),该coredns的ip地址可以解析集群域名
A的意思是查询A记录,有效查询DNS有很多种方法,查询A记录就是其中一种
结果如下:
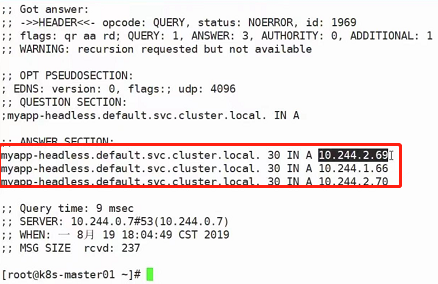
再看pod的ip地址,使用kubectl get pod -o wide:
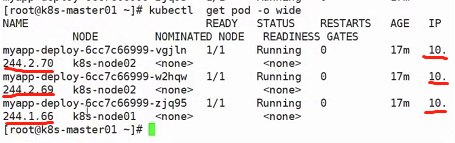
可以看到正是这三个ip地址
也就意味着在无头服务中,虽然他没有自己的svc了,但是可以通过访问域名的方案,依然可以访问到上图的几个目标pod中去
NodePort
nodePort的原理在于在node上开了一个端口,将向该端口的流量导入到kube-proxy,然后由kube-proxy进一步到对应的pod(当然这里说的其实还是iptables,如果是lvs,那就是访问到lvs的服务地址)
案例:
apiVersion: v1
kind: Service
metadata:
name: myapp
namespace: default
spec:
type: NodePort
selector:
app: myapp
release: stabel
ports:
- name: http
port: 80
targetPort: 80
创建之后使用kubectl get svc:
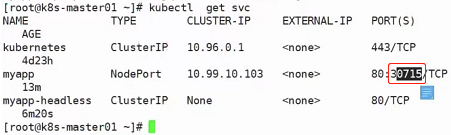
上图30715就是暴露给外部的端口,需要注意的是:每一个节点都开启了这个端口
可以使用命令:netstat -anpt | grep :30715查看:

那么每一个节点上都可以使用上述命令进行查看,会发现每一个节点都开启了30715这个端口
查询流程:
使用iptables时:
iptables -t nat -nvL
KUBE-NODEPORTS
或者
使用ipvs时:
ipvsadm -Ln
查询结果为:

192.168.66.10:30715负载均衡到三个节点:10.244.1.66:80、10.244.2.69:80、10.244.2.70:80
这就是原理,通过kube-proxy跟netlink(也就是ipvs的接口层)去进行交互,创建出来对应的规则之后进行负载均衡
LoadBalancer
loadBalancer和nodePort其实是同一种方式。区别在于loadBalancer比nodePort多了一步,就是可以调用cloud provider去创建LB(负载均衡)来向节点导流
供应商提供的服务:LAAS(loadBalance as a service)
ExternalName
这种类型的Service通过返回CNAME和它的值,可以将服务映射到externalName字段的内容(例如:hub.atguigu.com )。ExternalName Service是Service的特例,它没有selector,也没有定义任何的端口和Endpoint。相反的,对于运行在集群外部的服务,它通过返回该外部服务的别名这种方式来提供服务
kind: Service
apiVersion: v1
metadata:
name: my-service-1
namespace: default
spec:
type: ExternalName
externalName: hub.atguigu.com
当查询主机my-service.default.svc.cluster.local ( SVC_NAME.NAMESPACE.svc.cluster.local )时,集群的DNS服务将返回一个值hub.atguigu.com的CNAME记录。访问这个服务的工作方式和其他的相同,唯一不同的是重定向发生在DNS层,而且不会进行代理或转发
案例:
-
首先根据上面的模板创建
.yaml文件 -
使用命令
kubectl create -f xxx.yaml创建该svc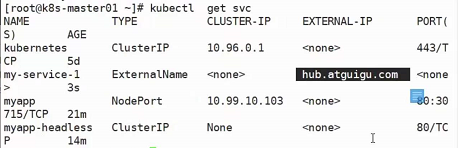
-
使用命令
dig -t A my-service-1.default.svc.cluster.local. @10.244.0.7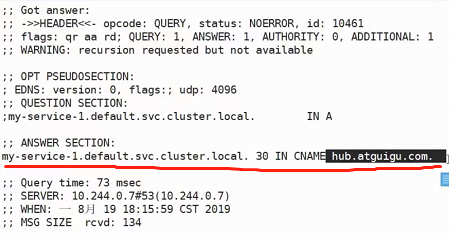
可以看到这个东西其实就是做了一个dns别名的操作,具体的意义就是想把外部的服务引入集群内部
网络通讯方式
Kubernetes 的网络模型假定了所有 Pod 都在一个可以直接连通的扁平的网络空间中,这在GCE(Google Compute Engine)里面是现成的网络模型,Kubernetes 假定这个网络已经存在。而在私有云里搭建 Kubernetes 集群,就不能假定这个网络已经存在了。我们需要自己实现这个网络假设,将不同节点上的 Docker 容器之间的互相访问先打通,然后运行 Kubernetes
同一个 Pod 内的多个容器之间:lo(也就是我们熟知的localhost)
各 Pod 之间的通讯:Overlay Network
Pod 与 Service 之间的通讯:各节点的 Iptables 规则(现在不用iptables了,用LVS,效率更高上限也更高)
Flannel 是 CoreOS 团队针对 Kubernetes 设计的一个网络规划服务,简单来说,它的功能是让集群中的不同节点主机创建的 Docker 容器都具有全集群唯一的虚拟IP地址。而且它还能在这些 IP 地址之间建立一个覆盖网络(Overlay Network),通过这个覆盖网络,将数据包原封不动地传递到目标容器内
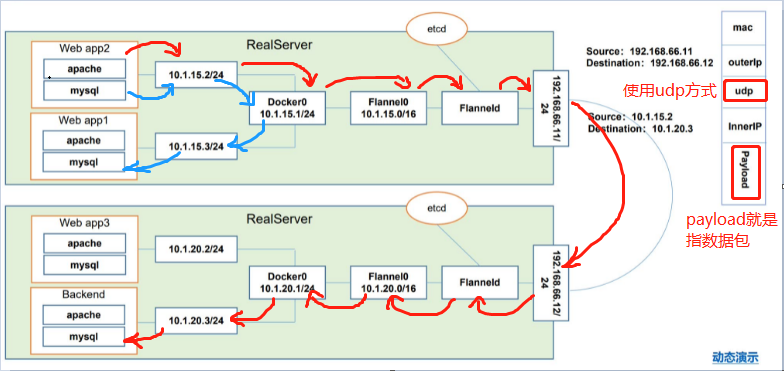
上图红色线为跨主机访问,蓝色线为同主机应用之间的访问
使用udp方式,比较快
数据包到Flanneld的时候还会进行封装,封装成这个样子:

由于数据进行了二次封装,因此Docker0是看不到这个的:

Docker0看的是这个:

ETCD 之 Flannel 提供说明:
-
存储管理 Flannel 可分配的 IP 地址段资源
Flannel在启动之后会往etcd插入可分配网段,并且哪些网段被分配到哪台机器上他会进行记录,防止已分配的网段再次被Flannel利用被分配给其他node节点,这样的话迟早会出现ip冲突
-
监控 ETCD 中每个 Pod 的实际地址,并在内存中建立维护 Pod 节点路由表
怎么知道“web app2”的pod网段
10.1.15.2/24是对应192.168.66.11/24呢?就是通过维护 Pod 节点的路由表知道的
上述两点足以凸显etcd的重要性!
同一个 Pod 内部通讯:同一个 Pod 共享同一个网络命名空间,共享同一个 Linux 协议栈
Pod1 至 Pod2
- Pod1 与 Pod2 不在同一台主机,Pod的地址是与docker0在同一个网段的,但docker0网段与宿主机网卡是两个完全不同的IP网段,并且不同Node之间的通信只能通过宿主机的物理网卡进行。将Pod的IP和所在Node的IP关联起来,通过这个关联让Pod可以互相访问
- Pod1 与 Pod2 在同一台机器,由 Docker0 网桥直接转发请求至 Pod2,不需要经过 Flannel
Pod 至 Service 的网络:目前基于性能考虑,全部为 iptables(现在是LVS) 维护和转发
Pod 到外网:Pod 向外网发送请求,查找路由表, 转发数据包到宿主机的网卡,宿主网卡完成路由选择后,iptables执行Masquerade,把源 IP 更改为宿主网卡的 IP,然后向外网服务器发送请求
外网访问 Pod:Service
组件通讯示意图:
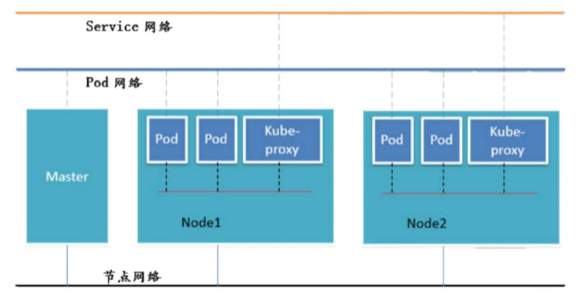
kubernetes集群安装(这一块很复杂,建议直接看尚硅谷Kubenetes教程(k8s从入门到精通)第3-1到第3-5集)
前期准备
使用centos7及以上,使用内核4.4版本及以上
集群安装
这里为什么需要Router(Router使用虚拟机搭配koolshare来搭建),是因为安装kubeadm需要科学上网,所以还有一种替代方法就是直接在本机上开ssr,用于搭建Router的虚拟机网卡使用桥接。
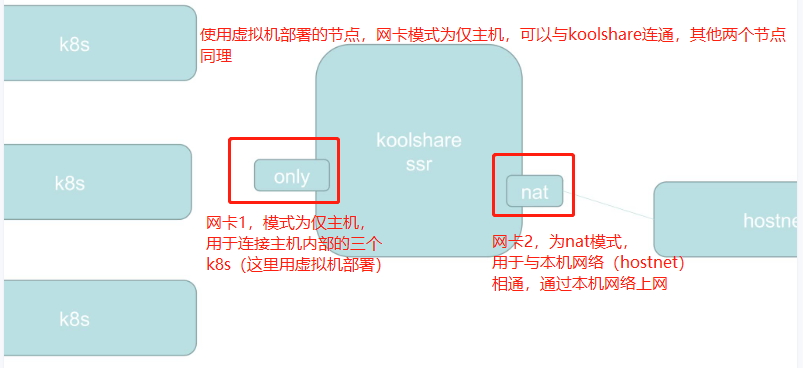
由于过程过于复杂,请直接参考尚硅谷Kubenetes教程(k8s从入门到精通)第3-2_尚硅谷_集群安装准备 -安装软路由集
值得注意的是:
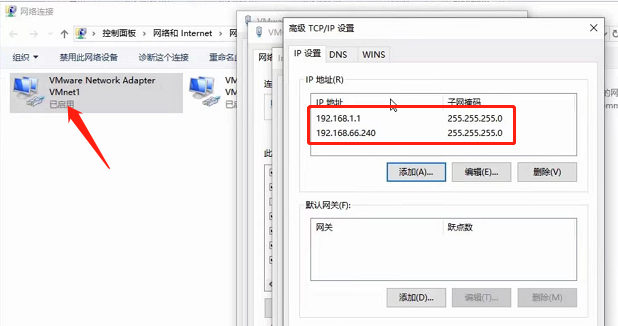
本机配置虚拟机网卡的ip地址等价于虚拟机里面配置网卡的子接口,也就是ifconfig eth0:0配置子接口,使得一块网卡具有多个ip地址
注意:
1、安装 k8s 的节点必须是大于 1 核心的 CPU
2、安装节点的网络信息:
网段:192.168.66.0/24
master节点:192.168.66.10/24
node1节点:192.168.66.20/24
node2节点:192.168.66.21/24
harbor节点:192.168.66.100/24 (该节点dns为:hub.auguigu.com,harbor节点域名解析不仅要在虚拟机/etc/hosts中加,还要在本机/etc/hosts中加)
3、koolshare 软路由的默认密码是 koolshare
可以在节点中使用命令vi /etc/sysconf/network-scripts/ifcfg-ens33来查看ip地址的配置,这是网卡的最新命名规范,他会从BIOS pcie通道获取网卡的文件名,如果都没有的话会再降级到eth0或eth1的命名方式。要想关闭的话,ifnames=0就可以把他关闭(这个地方有点没懂)。打开后是这样的:
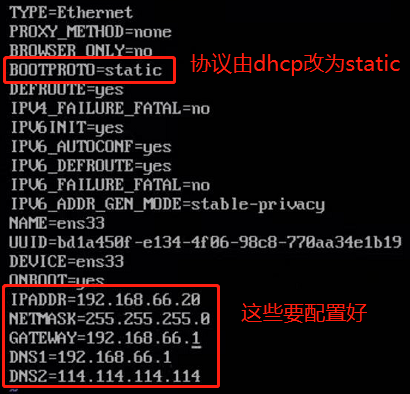
注意,这里的GATEWAY(网关)需要指向koolshare的软路由,让koolshare起作用
Harbor安装
一、安装底层需求
- Python应该是2.7或更高版本
- Docker引擎应为1.10或更高版本
- DockerCompose需要为1.6.0或更高版本
docker-compose:
curl -L https://github.com/docker/compose/releases/download/1.9.0/docker-compose-`uname-s`-`uname-m` > /usr/local/bin/docker-compose
二、Harbor官方地址:https://github.com/vmware/harbor/releases
1、解压软件包
tar xvf harbor-offline-installer-<version>.tgz https://github.com/vmware/harbor/releases/download/v1.2.0/harbor-offline-installer-v1.2.0.tgz
2、配置harbor.cfg
必选参数:
hostname:目标的主机名或者完全限定域名
ui_url_protocol:http或https。默认为http
db_password:用于db_auth的MySQL数据库的根密码。更改此密码进行任何生产用途
max_job_workers:(默认值为3)作业服务中的复制工作人员的最大数量。对于每个映像复制作业,工作人员将存储库的所有标签同步到远程目标。增加此数字允许系统中更多的并发复制作业。但是,由于每个工作人员都会消耗一定数量的网络/CPU/IO资源,请根据主机的硬件资源,仔细选择该属性的值
customize_crt:(on或off。默认为on)当此属性打开时,prepare脚本将为注册表的令牌的生成/验证创建私钥和根证书
ssl_cert:SSL证书的路径,仅当协议设置为https时才应用
ssl_cert_key:SSL密钥的路径,仅当协议设置为https时才应用
secretkey_path:用于在复制策略中加密或解密远程注册表的密码的密钥路径
3、创建https证书以及配置相关目录权限
openssl genrsa-des3-outserver.key2048
openssl req-new-keyserver.key-outserver.csr
cp server.keyserver.key.org
openssl rsa-inserver.key.org-outserver.key
openssl x509-req-days365-inserver.csr-signkeyserver.key-outserver.crt
mkdir /data/cert
chmod -R 777 /data/cert
4、运行脚本进行安装
./install.sh
5、访问测试
https://reg.yourdomain.com的管理员门户(将reg.yourdomain.com更改为您的主机名harbor.cfg)。请注意,默认管理员用户名/密码为admin/Harbor12345
6、上传镜像进行上传测试
a、指定镜像仓库地址
vim /etc/docker/daemon.json
{
"insecure-registries":["serverip"]
}
b、下载测试镜像
docker pull hello-world
c、给镜像重新打标签
docker tag hello-world serverip/hello-world:latest
d、登录进行上传
docker login serverip
7、其它Docker客户端下载测试
a、指定镜像仓库地址
vim /etc/docker/daemon.json
{
"insecure-registries":["serverip"]
}
b、下载测试镜像
docker pull serverip/hello-world:latest
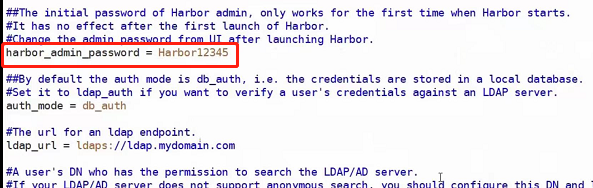
harbor登录密码在harbor.cfg中配置:
三、Harbor原理说明
1、软件资源介绍
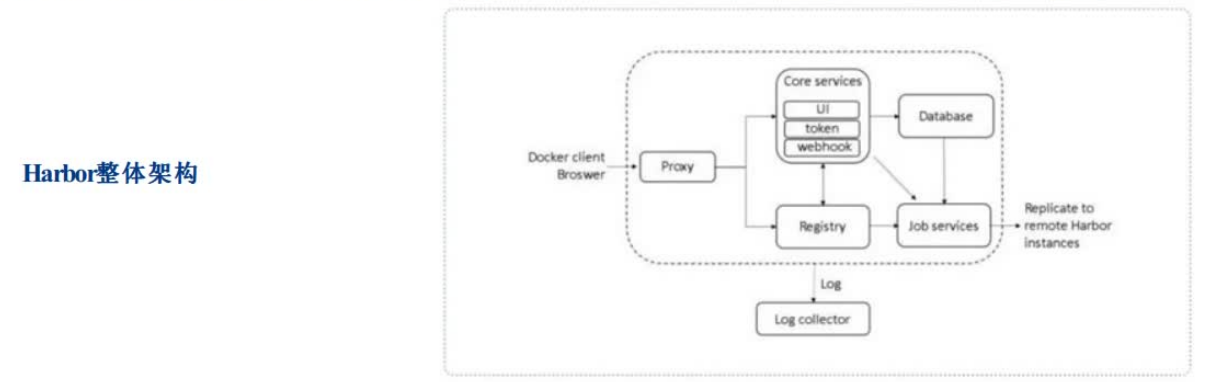
Harbor是VMware公司开源的企业级DockerRegistry项目,项目地址为https://github.com/vmware/harbor。其目标是帮助用户迅速搭建一个企业级的Dockerregistry服务。它以Docker公司开源的registry为基础,提供了管理UI,基于角色的访问控制(RoleBasedAccessControl),AD/LDAP集成、以及审计日志(Auditlogging)等企业用户需求的功能,同时还原生支持中文。Harbor的每个组件都是以Docker容器的形式构建的,使用DockerCompose来对它进行部署。用于部署Harbor的DockerCompose模板位于/Deployer/docker-compose.yml,由5个容器组成,这几个容器通过Dockerlink的形式连接在一起,在容器之间通过容器名字互相访问。对终端用户而言,只需要暴露proxy(即Nginx)的服务端口
- Proxy:由Nginx服务器构成的反向代理。
- Registry:由Docker官方的开源registry镜像构成的容器实例。
- UI:即架构中的coreservices,构成此容器的代码是Harbor项目的主体。
- MySQL:由官方MySQL镜像构成的数据库容器。
- Log:运行着rsyslogd的容器,通过log-driver的形式收集其他容器的日志
2、Harbor特性
a、基于角色控制:用户和仓库都是基于项目进行组织的,而用户基于项目可以拥有不同的权限
b、基于镜像的复制策略:镜像可以在多个Harbor实例之间进行复制
c、支持LDAP:Harbor的用户授权可以使用已经存在LDAP用户
d、镜像删除&垃圾回收:Image可以被删除并且回收Image占用的空间,绝大部分的用户操作API,方便用户对系统进行扩展
e、用户UI:用户可以轻松的浏览、搜索镜像仓库以及对项目进行管理
f、轻松的部署功能:Harbor提供了online、offline安装,除此之外还提供了virtualappliance安装
g、Harbor和docker registry关系:Harbor实质上是对docker registry做了封装,扩展了自己的业务模块
3、Harbor认证过程
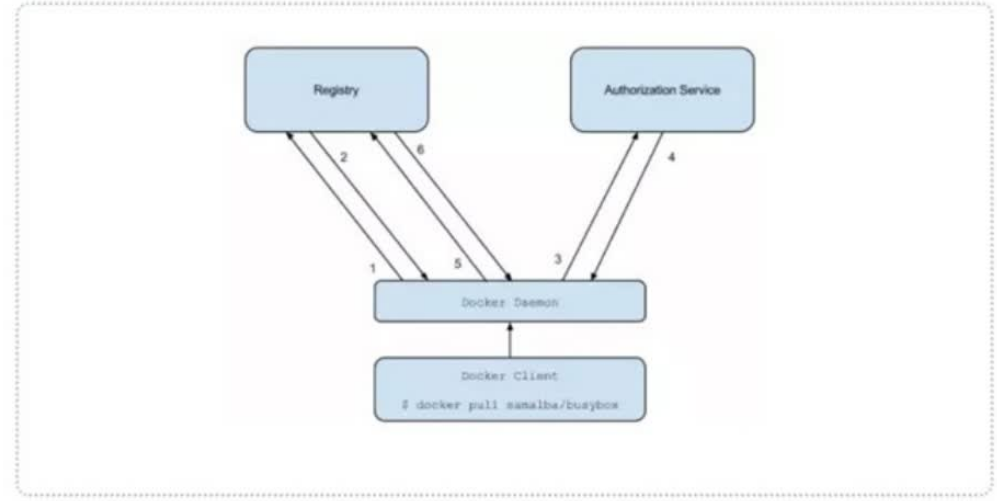
a、dockerdaemon从docker registry拉取镜像。
b、如果docker registry需要进行授权时,registry将会返回401Unauthorized响应,同时在响应中包含了dockerclient如何进行认证的信息。
c、dockerclient根据registry返回的信息,向auth server发送请求获取认证token。
d、auth server则根据自己的业务实现去验证提交的用户信息是否存符合业务要求。
e、用户数据仓库返回用户的相关信息。
f、auth server将会根据查询的用户信息,生成token令牌,以及当前用户所具有的相关权限信息.上述就是完整的授权过程.当用户完成上述过程以后便可以执行相关的pull/push操作。认证信息会每次都带在请求头中
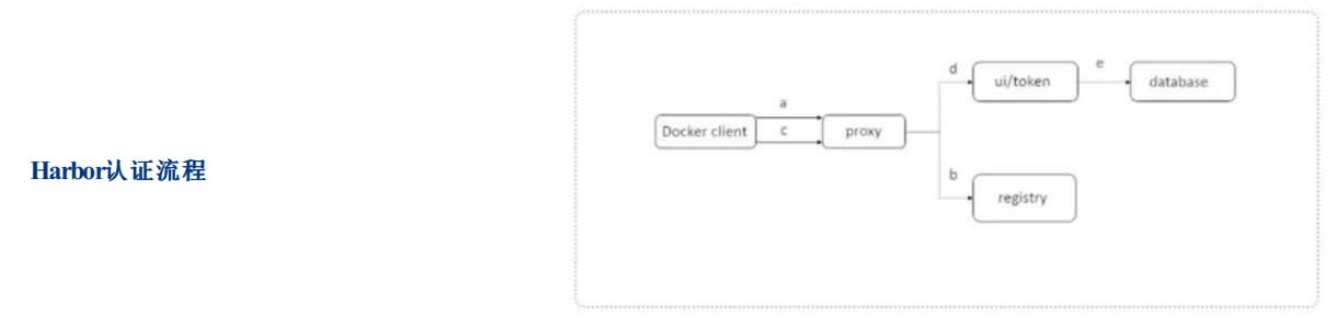
4、Harbor认证流程
a、首先,请求被代理容器监听拦截,并跳转到指定的认证服务器。
b、如果认证服务器配置了权限认证,则会返回401。通知docker client在特定的请求中需要带上一个合法的token。而认证的逻辑地址则指向架构图中的core services。
c、当docker client接受到错误code。client就会发送认证请求(带有用户名和密码)到core services进行basic auth认证。
d、当C的请求发送给ngnix以后,ngnix会根据配置的认证地址将带有用户名和密码的请求发送到core serivces。
e、core services获取用户名和密码以后对用户信息进行认证(自己的数据库或者介入LDAP都可以)。成功以后,返回认证成功的信息
系统初始化
设置系统主机名以及Host文件的相互解析
hostnamectl set-hostname k8s-master01
安装依赖包
yum install -y conntrack ntpdate ntp ipvsadm ipset jq iptables curl sysstat libseccomp wget vim net-tools git
设置防火墙为Iptables并设置空规则
systemctl stop firewalld && systemctl disable firewalld
yum -y install iptables-services && systemctl start iptables && systemctl enable iptables && iptables-F && service iptables save
关闭SELINUX
swapoff -a && sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
setenforce 0 && sed-i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config
调整内核参数,对于K8S
cat > kubernetes.conf<<EOF
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
net.ipv4.ip_forward=1
net.ipv4.tcp_tw_recycle=0
vm.swappiness=0 # 禁止使用swap空间,只有当系统OOM时才允许使用它
vm.overcommit_memory=1 # 不检查物理内存是否够用
vm.panic_on_oom=0 # 开启OOM
fs.inotify.max_user_instances=8192
fs.inotify.max_user_watches=1048576
fs.file-max=52706963
fs.nr_open=52706963
net.ipv6.conf.all.disable_ipv6=1
net.netfilter.nf_conntrack_max=2310720
EOF
cp kubernetes.conf /etc/sysctl.d/kubernetes.conf
sysctl -p /etc/sysctl.d/kubernetes.conf
调整系统时区
# 设置系统时区为中国/上海
timedatectl set-timezone Asia/Shanghai
# 将当前的UTC时间写入硬件时钟
timedatectl set-local-rtc 0
#重启依赖于系统时间的服务
systemctl restart rsyslog
systemctl restart crond
关闭系统不需要服务
systemctl stop postfix && systemctl disable postfix
设置rsyslogd和systemd journald
mkdir /var/log/journal # 持久化保存日志的目录
mkdir /etc/systemd/journald.conf.d
cat > /etc/systemd/journald.conf.d/99-prophet.conf << EOF
[Journal]
# 持久化保存到磁盘
Storage=persistent
#压缩历史日志
Compress=yes
SyncIntervalSec=5m
RateLimitInterval=30s
RateLimitBurst=1000
# 最大占用空间 10G
SystemMaxUse=10G
# 单日志文件最大 200M
SystemMaxFileSize=200M
# 日志保存时间 2周
MaxRetentionSec=2week
#不将日志转发到syslog
ForwardToSyslog=no
EOF
systemctl restart systemd-journald
升级系统内核为4.44
CentOS 7.x系统自带的3.10.x内核存在一些Bugs,导致运行的Docker、Kubernetes不稳定,例如:rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-3.el7.elrepo.noarch.rpm
rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-3.el7.elrepo.noarch.rpm
# 安装完成后检查 /boot/grub2/grub.cfg 中对应内核 menuentry 中是否包含 initrd16 配置,如果没有,再安装一次!
yum --enablerepo=elrepo-kernel install -y kernel-lt
# 设置开机从新内核启动
grub2-set-default 'CentOSLinux(4.4.189-1.el7.elrepo.x86_64)7(Core)'
kubeadm部署安装
kube-proxy开启ipvs的前置条件
modprobe br_netfilter
cat > /etc/sysconfig/modules/ipvs.modules << EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack_ipv4
安装Docker软件
yum install -y yum-utils device-mapper-persistent-data lvm2
yum-config-manager \
--add-repo \
http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum update -y && yum install -y docker-ce
## 创建 /etc/docker 目录
mkdir /etc/docker
# 配置 daemon.
cat > /etc/docker/daemon.json << EOF
{
"exec-opts":["native.cgroupdriver=systemd"],
"log-driver":"json-file",
"log-opts":{
"max-size":"100m"
}
}
EOF
mkdir -p /etc/systemd/system/docker.service.d
# 重启docker服务
systemctl daemon-reload && systemctl restart docker && systemctl enable docker
安装Kubeadm(主从配置)
cat << EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
yum -y install kubeadm-1.15.1 kubectl-1.15.1 kubelet-1.15.1
systemctl enable kubelet.service
初始化主节点
kubeadm config print init-defaults > kubeadm-config.yaml
localAPIEndpoint:
advertiseAddress: 192.168.66.10
kubernetesVersion: v1.15.1
networking:
podSubnet: "10.244.0.0/16"
serviceSubnet: 10.96.0.0/12
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
featureGates:
SupportIPVSProxyMode: true
# 将默认的调度方式改为ipvs
mode: ipvs
kubeadm init --config=kubeadm-config.yaml --experimental-upload-certs | tee kubeadm-init.log
上述podSubnet: "10.244.0.0/16"的设置是因为默认情况下会安装flannel网络插件去实现覆盖性网络,他的默认的podnet就是这个网段(10.244.0.0/16,如果这个网段不一致的话后期还需要去进入配置文件修改,所以我们提前把podSubnet声明为10.244.0.0/16)
加入主节点以及其余工作节点
执行安装日志中的加入命令即可
部署网络
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
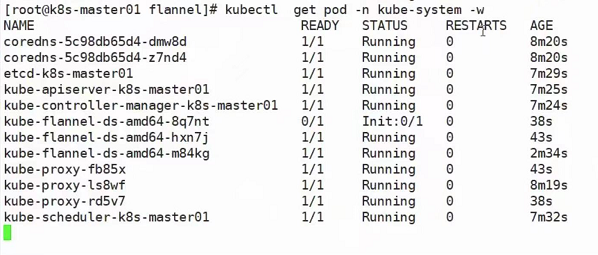
部署完成之后可以通过kubectl get pod -n kube-system来查看pod是否准备完毕,更方便的方法是使用-w(watch,监视):kubectl get pod -n kube-system -w,这样的话就不需要手动执行命令去看了,当前对话会一直夯着,一有更新就会推上来:
测试
上面的步骤全部完成之后,进行测试:
先使用docker按照harbor的规则往harbor推一个镜像,然后直接kubectl run ...创建deployment,当然,镜像的地址要写对,会发现,k8s会从harbor拉取镜像
之后使用docker ps -a | grep nginx还可以看到一个“/pause”,应证了之前所说的启动一个pod会先自动启动一个pause容器
然后访问:
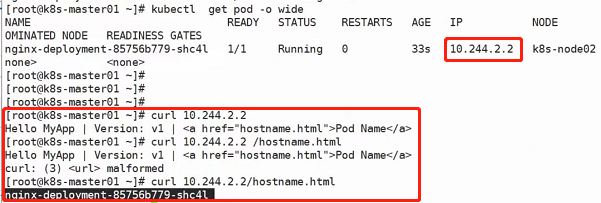
为什么能获取hostname呢?是因为采用了pod里面的容器的hostname,hostname设置的就是pod的名称
然后我们尝试删除pod,会发现又会新重启一个pod,那是因为我们设置了副本数为1,那么k8s会努力将容器副本数维持在1
接下来使用scale扩容为3份(为了验证deployment会生成rs,可以使用kubectl get deployment以及kubectl get rs,会发现有三个dp与三个rs互相对应),使用expose生成svc暴露端口,之前可以使用nginx做负载均衡,现在svc就可以做到,此时如果一直访问这个svc,我们会发现请求以一种轮询的机制分发到了3个dp中
然后我们使用ipvsadm -Ln命令可以查看服务映射规则:
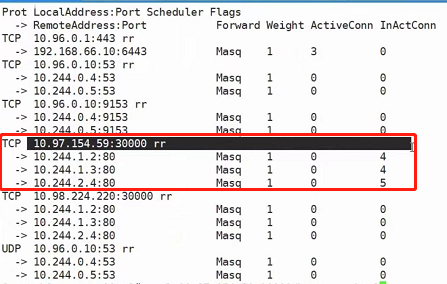

因此svc的机制就是调度LVS模块实现的负载均衡或者叫暴露服务
资源清单
k8s中的资源
什么是资源?
K8s 中所有的内容都抽象为资源,资源实例化之后,叫做对象
K8S中存在哪些资源?
名称空间级别:
工作负载型资源( workload ):Pod、ReplicaSet、Deployment、StatefulSet、DaemonSet、Job、CronJob ( ReplicationController 在 v1.11 版本被废弃 )
服务发现及负载均衡型资源( ServiceDiscovery LoadBalance ):Service、Ingress、…
配置与存储型资源:Volume( 存储卷 )、CSI( 容器存储接口,可以扩展各种各样的第三方存储卷 )
特殊类型的存储卷:ConfigMap( 当配置中心来使用的资源类型 )、Secret(保存敏感数据)、DownwardAPI(把外部环境中的信息输出给容器)
集群级资源:Namespace、Node、Role、ClusterRole、RoleBinding、ClusterRoleBinding
元数据型资源:HPA、PodTemplate、LimitRange
kubernetes 资源清单
在 k8s 中,一般使用 yaml 格式的文件来创建符合我们预期期望的 pod ,这样的 yaml 文件我们一般称为资源清单
资源清单格式
apiVersion: group/apiversion # 如果没有给定 group 名称,那么默认为 core,可以使用 kubectl api-
versions: # 获取当前k8s版本上所有的apiVersion版本信息(每个版本可能不同)
kind: # 资源类别
metadata: # 资源元数据
name:
namespace:
lables:
annotations: # 主要目的是方便用户阅读查找
spec: # 期望的状态(disired state)
status: # 当前状态,本字段有Kubernetes自身维护,用户不能去定义
资源清单的常用命令
获取 apiversion 版本信息
[root@k8s-master01~]# kubectl api-versions
admissionregistration.k8s.io/v1beta1
apiextensions.k8s.io/v1beta1
apiregistration.k8s.io/v1
apiregistration.k8s.io/v1beta1
apps/v1
......(以下省略)
获取资源的 apiVersion 版本信息
[root@k8s-master01~]# kubectl explain pod
KIND: Pod
VERSION: v1
.....(以下省略)
[root@k8s-master01~]# kubectl explain Ingress
KIND: Ingress
VERSION: extensions/v1beta1
获取字段设置帮助文档
[root@k8s-master01~]# kubectl explain pod
KIND: Pod
VERSION: v1
DESCRIPTION:
Pod is a collection of containers that can run on a host. This resource is created by clients and scheduled onto hosts.
FIELDS:
apiVersion <string>
........
........
字段配置格式
apiVersion <string> #表示字符串类型
metadata <Object> #表示需要嵌套多层字段
labels <map[string]string> #表示由k:v组成的映射
finalizers <[]string> #表示字串列表
ownerReferences <[]Object> #表示对象列表
hostPID <boolean> #布尔类型
priority <integer> #整型
name<string>-required- #如果类型后面接-required-,表示为必填字段
通过定义清单文件创建Pod
apiVersion: v1
kind: Pod
metadata:
name: pod-demo
namespace: default
labels:
app: myapp
spec:
containers:
- name: myapp-1
image: hub.atguigu.com/library/myapp:v1
- name: busybox-1
image: busybox:latest
command:
- "/bin/sh"
- "-c"
- "sleep3600"
kubectl get pod xx.xx.xx -o yaml
<!-- 使用 -o 参数加 yaml ,可以将资源的配置以 yaml 的格式输出出来,也可以使用 json ,输出为 json 格式 -->
资源清单中常用字段的解释
| 参数名 | 字段类型 | 说明 |
|---|---|---|
| version | String | 这里是指K8S API的版本,目前基本上是v1,可以用kubectl api-version命令查询 |
| king | String | 这里指的是yaml文件定义的资源类型和角色,比如:Pod |
| metadata | Object | 元数据对象,固定值就写metadata |
| metadata.name | String | 元数据对象的名字,这里由我们编写,比如命名Pod的名字 |
| metadata.namespace | String | 元数据对象的命名空间,由我们自身定义 |
| Spec | Object | 详细定义对象,固定值就写Spec |
| spec.containers[] | list | 这里是Spec对象的容器列表定义,是个列表 |
| spec.containers[].name | String | 这里定义容器的名字 |
| spec.containers[].image | String | 这里定义要用到的镜像名称 |
| spec.containers[].imagePullPolicy | String | 定义镜像拉取策略,有Always、Never、IfNotPresent三个值可选(1)Always:意思是每次都尝试重新拉取镜像(2)Never:表示仅使用本地镜像(3)IfNotPresent:如果本地有镜像就是用本地镜像,没有就拉取在线镜像。上面三个值都没设置的话,默认是Always |
| spec.contaienrs[].command[] | List | 指定容器启动命令,因为是数组可以指定多个,不指定则使用镜像打包时使用的启动命令 |
| spec.containers[].args[] | List | 指定容器启动命令参数,因为是数组可以指定多个 |
| spec.containers[].workingDir | String | 指定容器的工作目录 |
| spec.containers[].volumeMounts[] | List | 指定容器内部的存储卷配置 |
| spec.containers[].volumeMounts[].name | String | 指定可以被容器挂载的存储卷名称 |
| spec.containers[].volumeMounts[].mountPath | String | 指定可以被容器挂载的存储卷的路径 |
| spec.containers[].volumeMounts[].readOnly | String | 设置存储卷路径的读写模式,true或false,默认为读写模式 |
| spec.containers[].ports[] | List | 指定容器需要用到的端口列表 |
| spec.containers[].ports[].name | String | 指定端口名称 |
| spec.containers[].ports[].containerPort | String | 指定容器需要监听的端口号 |
| spec.containers[].ports[].hostPort | String | 指定容器所在主机需要监听的端口号,默认跟上面ContainerPort相同,注意设置了hostPort同一台主机无法启动该容器的相同副本(因为主机的端口号不能相同,这样会冲突) |
| spec.containers[].ports[].protocol | String | 指定端口协议,支持TCP和UDP,默认是TCP |
| spec.containers[].env[] | List | 指定容器运行前需设置的环境变量列表 |
| spec.containers[].env[].name | String | 指定环境变量名称 |
| spec.containers[].env[].value | String | 指定环境变量值 |
| spec.containers[].resources | Object | 指定资源限制和资源请求的值(这里开始就是设置容器的资源上限) |
| spec.containers[].resources.limits | Object | 指定设置容器运行时资源的运行上限 |
| spec.containers[].resources.limits.cpu | String | 指定CPU的限制,单位为core数,将用于docker run --cpu-shares参数(这里前面文章Pod资源限制有讲过) |
| spec.containers[].resources.limits.memory | String | 指定MEM内存的限制,单位为MIB、GIB |
| spec.containers[].resources.requests | Object | 指定容器启动和调度时的限制设置 |
| spec.containers[].resources.requests.cpu | String | CPU请求,单位为core数,容器启动时初始化可用数量 |
| spec.containers[].resources.requests.memory | String | 内存请求,单位为MIB、GIB,容器启动的初始化可用数量 |
| spec.restartPolicy | String | 定义Pod的重启策略,可选值为Always、OnFailure,默认值为Always。1、Always:Pod一旦终止运行,则无论容器是如何终止的,kubelet服务都将重启他;2、OnFailure:只有Pod以非零退出码终止时,kubelet才会重启该容器。如果容器正常结束(退出码为0),则kubelet将不会重启他;3、Never:Pod终止后,kubelet将退出码报告给master,不会重启该Pod |
| spec.nodeSelector | Object | 定义Node的Label过滤标签,以key:value格式指定 |
| spec.imagePullSecrets | Object | 定义pull镜像时使用secret名称,以name:secretkey格式指定 |
| spec.hostNetwork | Boolean | 定义是否使用主机网络模式,默认值false。设置true表示使用宿主机网络,不使用docker网桥,同时设置了true将无法在同一台宿主机上启动第二个副本 |
使用kubectl explain可以查看具体字段的解释以及模板
例如我想看pod的:
kubectl explain pod
pod下有spec字段,同样我们也可以进行查看:
kubectl explain pod.spec
pod下的spec下的containers字段:
kubectl explain pod.spec.containers
依次类推
容器生命周期
当发生问题时,该如何应对呢?
可以使用kubectl describe pod xxx来查看pod的状态;
可以使用kubectl log xxx -c my_container_name来查看pod中某一个容器中的日志(-c用于指定容器名,当然如果pod中只有一个容器,也可以不指定-c参数)
可以使用kubectl exec xxx -c my_container_name -it -- /bin/sh进入pod中的某一个容器(-c用于指定容器名,当然如果pod中只有一个容器,也可以不指定-c参数,-it表示交互模式和打开一个tty,-- /bin/sh是固定格式,指的是运行一个命令,运行bin下的sh(--的意思是需要运行命令,他的后面写的命令就是需要去运行的命令))
也可以直接使用kubectl exec xxx -c my_container_name -it -- 具体命令,等价于直接进入pod中的某一个容器然后执行具体命令,举例:kubectl exec xxx -c my_container_name -it -- rm -rf /usr/share/nginx/html/index.html,相当于进入了pod中某一个容器,然后删掉了/usr/share/nginx/html/index.html这个文件
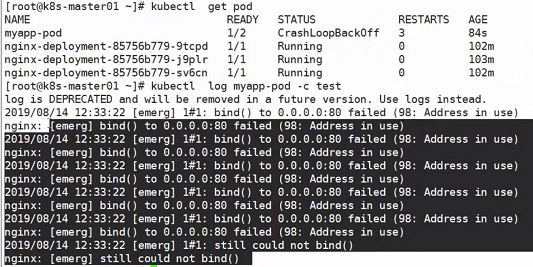
为什么要了解容器生命周期?
有时候pod中的容器中的进程意外死亡了,但是容器还是正常存在,pod还是running状态,这个时候其实服务已经不可用了,但是对于整个pod来讲,服务还是可用的,这个时候就会出现问题了,那么怎么去做纠察,这个时候如果使用者了解容器的生命周期那就比较好办了。
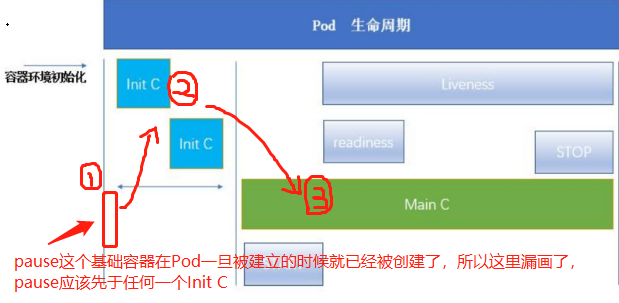
上图为pod生命周期图,注意,pause最先起来(pod被建立的时候他就已经起来了),然后是Init C初始化构建,最后才是真正的容器的内部(也就是上图的“Main C”),当然,一个pod里会有多个容器,也就是说上图的“Main C”可能有多个,只是为了防止懵逼,才画了一个,而如果有两个Main C,那么每个Main C都会有属于自己的Init C、readiness、liveness、start、stop
“Main C”容器在开始运行的时候有一个START指令,在退出的时候又有一个STOP指令,执行完STOP指令之后,才允许他退出
以下的讲解将围绕上图进行
Init 容器
Pod 能够具有多个容器,应用运行在容器里面,但是它也可能有一个或多个先于应用容器启动的 Init容器
Init 容器与普通的容器非常像,除了如下两点:
-
Init 容器总是运行到成功完成为止
对于Init C,他不像Main C,Main C退出的话pod就退出了,Init C退出不会跟pod的生命周期有关,pod并不会因为Init C结束而结束;
Init C如果不正常退出的话,是不会到Main C这一步的;
并且,Init C如果不正常退出的话,pod是要启动对应的流程处理的,比如重启;
-
每个 Init 容器都必须在下一个 Init 容器启动之前成功完成
如果 Pod 的 Init 容器失败,Kubernetes 会不断地重启该 Pod,直到 Init 容器成功为止。然而,如果 Pod 对应的 restartPolicy 为 Never,它不会重新启动
Init C初始化容器,比如我有一个pod,pod里面有若干容器,这些容器要启动的前提条件是需要在本机的xxx存储下面有xxx文件存在才可以,这个时候就可以利用Init C去生成这些文件,注意,Init C只是用于初始化的,并不会一直跟随Pod生命周期存在,也就是说Init C做完初始化操作之后就会死亡(Init C初始化完成之后如果正常退出了,退出码一定是0,如果不是0那就是异常退出,异常退出可能要重新执行,根据重启策略去判断),Init C可以没有,也可以有1个及以上,并且每一个Init C只有在结束本次构建之后才可以进入下一个Init C的构建(Init C的构建是线性执行的,并非异步)
Init 容器的作用
因为 Init 容器具有与应用程序容器分离的单独镜像,所以它们的启动相关代码具有如下优势:
-
它们可以包含并运行实用工具,但是出于安全考虑,是不建议在应用程序容器镜像中包含这些实用工具的
在主容器Main C启动之前,我可能会需要一些文件被创建,需要一些数据被梳理,但是这些创建文件和梳理数据的工具如果加载到Main C又会导致Main C的冗余,这些工具不会一直都被用,随着工具越来越多Main C稳定性也会得不到保障,所以这个时候就可以通过将这些工具写到Init C,让他在初始化过程中将后续Main C会用到的东西提前创建出来,这样的话Main C就不需要包含这些文件或数据,但又能正常使用这些文件或数据
-
它们可以包含使用工具和定制化代码来安装,但是不能出现在应用程序镜像中。例如,创建镜像没必要 FROM 另一个镜像,只需要在安装过程中使用类似 sed、awk、python 或 dig这样的工具。
-
应用程序镜像可以分离出创建和部署的角色,而没有必要联合它们构建一个单独的镜像。
主容器运行的时候,大体分为两个流程,一个是构建代码(比如从仓库拉取代码等), 一个是运行代码,那么完全可以把构建代码的部分剥离成Init C去运行
-
Init 容器使用 Linux Namespace,所以相对应用程序容器来说具有不同的文件系统视图。因此,它们能够具有访问 Secret 的权限,而应用程序容器则不能。
举个例子,Main C可能只需要使用某目录下的某些文件,但是该目录为了安全性不能直接赋予Main C权限去访问,不然后续Main C就能访问该目录下其他文件了,这是非常不安全的,那么可以将权限赋予Init C,Init C读取Main C所需的文件并写入Main C,后续Init C执行完毕就会退出,这样就比较安全了
-
它们必须在应用程序容器启动之前运行完成,而应用程序容器是并行运行的,所以 Init 容器能够提供了一种简单的阻塞或延迟应用容器的启动的方法,直到满足了一组先决条件。
举个例子:
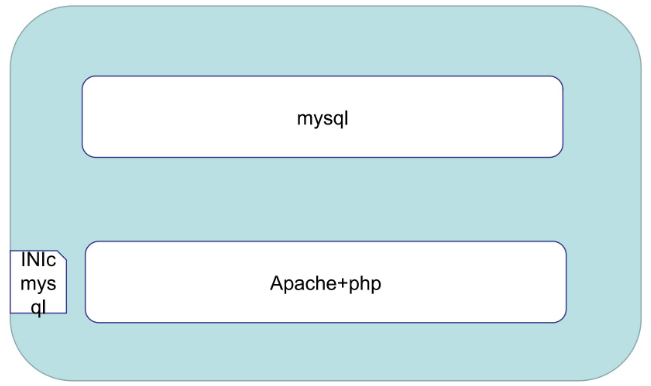
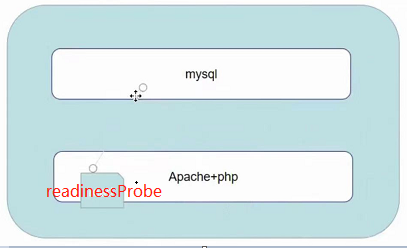
一个pod中有两个Main C,一个是mysql,一个是apache+php,后者依赖前者,如果前者没启动完毕时后者就启动完毕了,后者连不上mysql就会报错,检测机制会发现居然报错了,是不是哪里出问题了,那么整个pod就会一直重启、重启、…,这个时候可以给后者加一个Init C去检测mysql是否正常,如果正常了就退出检测循环,结束该Init C,之后apache+php这个Main C就可以启动了
关注"kubernetes pod 探测"小节,该小节针对Init C做了一些实验
特殊说明
-
在 Pod 启动过程中,Init 容器会按顺序在网络和数据卷初始化之后启动。每个容器必须在下一个容器启动之前成功退出
网络和数据卷初始化是在pause中去完成的,也就意味着pod启动第一个容器不是Init C而是pause,pause这个容器是很小的,只负责网络和数据卷初始化,别的啥也不干,所以我们对pause的操作为无,知道有他存在就行了
Init C退出码为0表示正常,非0为异常,只要有一个Init C退出码为非0,则后续的Init C就不会再执行了
-
如果由于运行时或失败退出,将导致容器启动失败,它会根据 Pod 的 restartPolicy 指定的策略进行重试。然而,如果 Pod 的 restartPolicy 设置为 Always,Init 容器失败时会使用RestartPolicy 策略
-
在所有的 Init 容器没有成功之前,Pod 将不会变成 Ready 状态。Init 容器的端口将不会在Service 中进行聚集。正在初始化中的 Pod 处于 Pending 状态,但应该会将 Initializing 状态设置为 true
“Init 容器的端口将不会在Service 中进行聚集”意思是:如果Main C或者Init C没有正常启动完毕,则他的ip地址和port不会在service的nodeport他的调度队列里面出现,防止服务没有正常启动就被外网访问
-
如果 Pod 重启,所有 Init 容器必须重新执行
-
# 对 Init 容器 spec 的修改被限制在容器 image 字段,修改其他字段都不会生效。更改 Init容器的 image 字段,等价于重启该 Pod
使用
kubectl edit pod xxx可以看到该pod的yaml文件,里面有些参数不可修改,有些可以修改,可修改的参数除了image以外都不会使该pod重启,但是一旦修改了image字段,Init容器就会重新执行,而Init容器重新执行就等价于重启pod -
Init 容器具有应用容器的所有字段。除了 readinessProbe和livenessProbe,因为 Init 容器无法定义不同于完成(completion)的就绪(readiness)之外的其他状态。这会在验证过程中强制执行
Init能用的字段与spec里面containers下面的字段基本一致,除了readinessProbe(就绪检测)和livenessProbe(生存检测),因为Init就是去帮别人做就绪之前的一些操作的,按理来讲他就不可能去做就绪检测,而且Init运行完就退出了,所以他也不能做后续的生存检测
并且如果真的配置了readinessProbe和livenessProbe,是不生效的
-
在 Pod 中的每个 app 和 Init 容器的名称必须唯一;与任何其它容器共享同一个名称,会在验证时抛出错误
Init C也有name字段,这个字段一定不能重复
值得注意的是,同一组Init C的port可以重复,因为当一个Init执行完毕退出之后,就会释放该Init所占用的port,那么别的Init就可以正常使用了
容器探针
上面说了可以用Init C去做简单的就绪检测,但是细想一下这部分功能在Init C中完成其实不太好,首先Init C并不是主程序里面的,如果在Init C做对容器x的就绪检测的话,万一Init C检测的时候x正常,那么Init C就会退出了,而后续另一个容器y去连接x的时候,x又不正常了,这个时候就不太好了。我们想在Main C中去做容器探测,这样的话如果探测正常那肯定就是正常了
探针是由 kubelet 对容器执行的定期诊断(kubelet 执行的,也就是说对于探针来说,他并不是由主服务器master去发起的,而是由每一个node所在的kubelet去对他进行一个检测,这样的话能减轻master的压力)。要执行诊断,kubelet 调用由容器实现的 Handler。有三种类型的处理程序:
- ExecAction:在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功。
- TCPSocketAction:对指定端口上的容器的 IP 地址进行 TCP 检查。如果端口打开,则诊断被认为是成功的。
- HTTPGetAction:对指定的端口和路径上的容器的 IP 地址执行 HTTP Get 请求。如果响应的状态码大于等于200 且小于 400,则诊断被认为是成功的
每次探测都将获得以下三种结果之一:
- 成功:容器通过了诊断。
- 失败:容器未通过诊断。
- 未知:诊断失败,因此不会采取任何行动(容器被挂死,因为一直在等待探测成功之后才能被就绪)
探测方式
livenessProbe:指示容器是否正在运行。如果存活探测失败,则 kubelet 会杀死容器,并且容器将受到其 重启策略 的影响。如果容器不提供存活探针,则默认状态为 Success
readinessProbe:指示容器是否准备好服务请求。如果就绪探测失败,端点控制器将从与 Pod 匹配的所有 Service 的端点中删除该 Pod 的 IP 地址。初始延迟之前的就绪状态默认为 Failure。如果容器不提供就绪探针,则默认状态为 Success
下面来看看探针到底如何实现,请查看下方的“检测探针-就绪检测”小节和"检测探针-存活检测"小节
再看到最上面的那张图。readiness是就绪检测;liveness是生存检测
readiness和liveness在上图中没有跟Main C画在同一起跑线,是有原因的,因为可以设置在Main C启动之后多少多少秒开始进行readiness,比方说Main C启动5秒之后再启动readiness,同理liveness。在readiness检测之前,pod状态不会显示为running, 只有当readiness检测完毕之后,才会显示running。如果liveness检测出Main C已经不行了,出现损坏了,那就会执行对应的重启命令,或者删除命令等等,根据重启策略来确定
readiness和liveness举例:
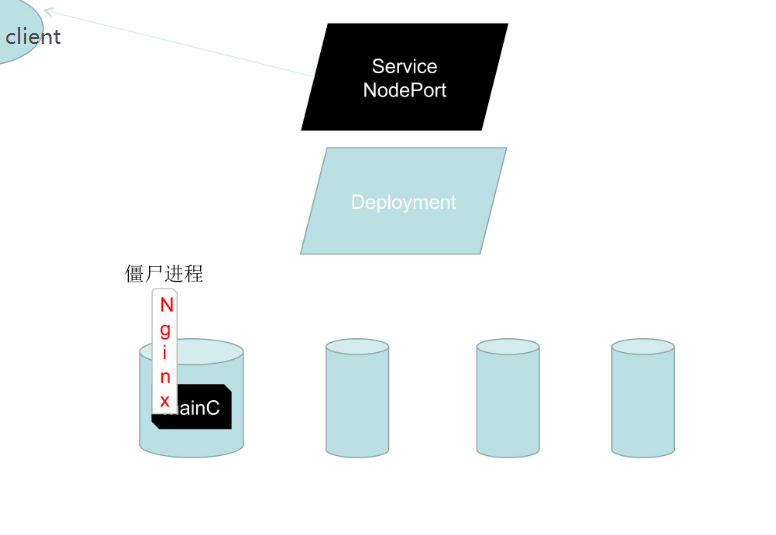
首先有四个pod,上层是rs(这里没画),再上层是deployment,再上层是svc,svc对外提供访问。
假设第一个pod启动的是tomcat,在第一次启动的时候他的初始化过程还是比较长的,他需要把项目给展开,如果一旦这个pod创建成功(kubectl get pod发现这个pod的状态已经是running了),running的含义是这个时候svc已经把他拿到对外的访问队列里面去了,但是如果这个tomcat部署程序还没有完成,还不能对外提供访问,但是现在pod的状态又是running,running的意思又是可以对外访问(换句话说,pod显示的是running,但是运行的主要的进程还没有加载成功),这个时候如果外部访问了,必然会失败,所以这个时候就需要有一个readiness就绪检测,什么叫就绪检测呢?我们可以根据命令,根据tcp连接,根据ipv协议获取状态,判断服务是否已经可用了,如果可用了,再把状态改为running
还有一个liveness,假设pod里面运行了一个主容器(Main C),那这个主容器里面有可能运行了一个比如nginx,而这个nginx假死了(僵尸进程,名存实亡),但是nginx进程仍然在运行,进程在运行主容器就要运行,主容器运行pod的状态就是running,running就意味着能够继续对外部提供访问,这个时候就需要liveness了,当nginx无法继续对外提供正常访问或者说容器内部已经不能对外提供正常访问的时候,可以执行重启或者重建pod的操作
总结:
首先kubectl向kubeapi发送指令,kubeapi会调度到kubelet,这个调度过程由etcd在中间参与完成的,kubelet去操作cri,cri去完成容器的初始化(pause容器的启动、Init C、…)
kubernetes pod 探测
Init容器
init模板
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app: myapp
spec:
# Init C没启动完毕之前Main C是不会启动的
containers:
- name: myapp-container
# 这里镜像最好指定版本或者标签,不然的话默认下载latest,而10年前的latest跟现在的latest肯定不是一个版本,可能会导致镜像重复拉取最终导致拉取失败,导致报错,导致容器启动失败
image: busybox
command: ['sh', '-c', 'echo The app is running! && sleep 3600']
# initContainers表示以下容器是需要被先初始化的(就是上面说的Init C)
# 注意,不管是readinessProbe还是livenessProbe还是Init C还是start还是stop都是可以绑在一个容器下配合使用的,这里是为了演示方便,才单独分开写
initContainers:
- name: init-myservice
image: busybox
# 这里的myservice就是下方Service的metadata中的name,k8s内部的dns服务会将pod、svc、deployment等的metadata: name: 的值自动解析成ip地址
command: ['sh', '-c', 'until nslookup myservice; do echo waiting for myservice; sleep 2; done;']
- name: init-mydb
image: busybox
command: ['sh', '-c', 'until nslookup mydb; do echo waiting for mydb; sleep 2; done;']
kind: Service
apiVersion: v1
metadata:
# k8s内部的dns服务会将pod、svc、deployment等的metadata: name: 的值自动解析成ip地址,因此这里的myservice会被自动解析,所以上方command中就可以直接“nslookup myservice”
name: myservice
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9376
---
kind: Service
apiVersion: v1
metadata:
name: mydb
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9377
k8s中的dns服务(使用kubectl get pod -n kube-system查看):
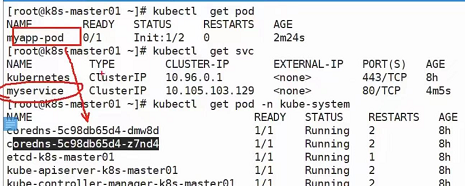
如果创建了svc,比方说上图的myservice,那么myservice就会被写入k8s内部的dns服务,这时候myapp-pod去请求dns是否有myservice域名的解析数据,如果有则dns会返回这些数据
检测探针-就绪检测
readinessProbe-httpget
就绪检测就是如果不就绪的话不把他的状态改成Ready
存活检测就是如果不存活的话就直接把他干掉了
apiVersion: v1
kind: Pod
metadata:
name: readiness-httpget-pod
namespace: default
spec:
containers:
- name: readiness-httpget-container
image: wangyanglinux/myapp:v1
imagePullPolicy: IfNotPresent
# 注意,不管是readinessProbe还是livenessProbe还是Init C还是start还是stop都是可以绑在一个容器下配合使用的,这里是为了演示方便,才单独分开写
readinessProbe:
# 使用get方式去请求80端口下的/index1.html,如果成功了说明探测成功,反之失败
httpGet:
port: 80
path: /index1.html
# 设定延时,这个容器在启动1秒以后才开启延时
initialDelaySeconds: 1
# 重试的周期时间,这里是3秒重试一下
periodSeconds: 3
那这种方式显然比Init C去做探测要好
检测探针-存活检测
livenessProbe-exec
就绪检测就是如果不就绪的话不把他的状态改成Ready
存活检测就是如果不存活的话就直接把他干掉了
apiVersion: v1
kind: Pod
metadata:
name: liveness-exec-pod
namespace: default
spec:
containers:
- name: liveness-exec-container
# 之前说不加标签默认下载latest,这里有个前提,就是imagePullPolicy必须是always,也就是说每次都会去下载latest版本,如果是IfNotPresent,他是不会每次都去下载latest版本的
image: hub.atguigu.com/library/busybox
imagePullPolicy: IfNotPresent
# 这里的shell命令很显然会在60秒之后导致下方livenessProbe中的命令执行返回false导致容器被干掉,主容器被干掉就会导致pod重启
command: ["/bin/sh", "-c", "touch /tmp/live ; sleep 60 ; rm -rf /tmp/live ; sleep 3600"]
# 注意,不管是readinessProbe还是livenessProbe还是Init C还是start还是stop都是可以绑在一个容器下配合使用的,这里是为了演示方便,才单独分开写
livenessProbe:
exec:
command: ["test", "-e", "/tmp/live"]
initialDelaySeconds: 1
periodSeconds: 3
livenessProbe-httpget
apiVersion: v1
kind: Pod
metadata:
name: liveness-httpget-pod
namespace: default
spec:
containers:
- name: liveness-httpget-container
image: hub.atguigu.com/library/myapp:v1
imagePullPolicy: IfNotPresent
ports:
# 这里定义的http目的是为了复用
- name: http
containerPort: 80
# 注意,不管是readinessProbe还是livenessProbe还是Init C还是start还是stop都是可以绑在一个容器下配合使用的,这里是为了演示方便,才单独分开写
livenessProbe:
httpGet:
# 这里的http是复用了上面定义的http
port: http
path: /index.html
initialDelaySeconds: 1
periodSeconds: 3
timeoutSeconds: 10
livenessProbe-tcp
apiVersion: v1
kind: Pod
metadata:
name: probe-tcp
spec:
containers:
- name: nginx
image: hub.atguigu.com/library/myapp:v1
# 注意,不管是readinessProbe还是livenessProbe还是Init C还是start还是stop都是可以绑在一个容器下配合使用的,这里是为了演示方便,才单独分开写
livenessProbe:
initialDelaySeconds: 5
timeoutSeconds: 1
tcpSocket:
port: 80
# 下面这行如果不加,就会使用默认的周期时间
periodSeconds: 3
启动、退出动作
apiVersion: v1
kind: Pod
metadata:
name: lifecycle-demo
spec:
containers:
- name: lifecycle-demo-container
image: nginx
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", "echo Hello from the postStart handler > /usr/share/message"]
preStop:
exec:
# 当然这里可以执行任何你想要的代码,比方说数据库备份等等
command: ["/bin/sh", "-c", "echo Hello from the poststop handler > /usr/share/message"]
kubernetes 状态示例
Pod中只有一个容器并且正在运行,容器成功退出
- 记录事件完成
- 如果restartPolicy为:
- Always:重启容器;Pod phase 仍为 Running
- OnFailure:Pod phase 变成 Succeeded
- Never:Pod phase 变成 Succeeded
Pod中只有一个容器并且正在运行。容器退出失败
- 记录失败事件
- 如果restartPolicy为:
- Always:重启容器;Pod phase 仍为 Running
- OnFailure:重启容器;Pod phase 仍为 Running
- Never:Pod phase 变成 Failed
Pod中有两个容器并且正在运行。容器1退出失败
- 记录失败事件
- 如果restartPolicy为:
- Always:重启容器;Pod phase 仍为 Running
- OnFailure:重启容器;Pod phase 仍为 Running
- Never:不重启容器;Pod phase 仍为 Running
- 如果有容器1没有处于运行状态,并且容器2退出:
- 记录失败事件
- 如果restartPolicy为:
- Always:重启容器;Pod phase 仍为 Running
- OnFailure:重启容器;Pod phase 仍为 Running
- Never:Pod phase 变成 Failed
Pod中只有一个容器并处于运行状态。容器运行时内存超出限制
- 容器以失败状态终止
- 记录OOM事件
- 如果restartPolicy为:
- Always:重启容器;Pod phase 仍为 Running
- OnFailure:重启容器;Pod phase 仍为 Running
- Never:记录失败事件;Pod phase 仍为 Failed
Pod正在运行,磁盘故障
- 杀掉所有容器。记录适当事件
- Pod phase 变成 Failed
- 如果使用控制器来运行,Pod 将在别处重建
Pod正在运行,其节点被分段
- 节点控制器等待直到超时
- 节点控制器将 Pod phase 设置为 Failed
- 如果是用控制器来运行,Pod 将在别处重建
Pod hook
Pod hook(钩子)是由 Kubernetes 管理的 kubelet 发起的,当容器中的进程启动前或者容器中的进程终止之前运行,这是包含在容器的生命周期之中。可以同时为 Pod 中的所有容器都配置 hook
Hook 的类型包括两种:
- exec:执行一段命令
- HTTP:发送HTTP请求
Pod phase
Pod 的 status 字段是一个 PodStatus 对象,PodStatus中有一个 phase 字段。
Pod 的相位(phase)是 Pod 在其生命周期中的简单宏观概述。该阶段并不是对容器或 Pod 的综合汇总,也不是为了做为综合状态机
Pod 相位的数量和含义是严格指定的。除了本文档中列举的状态外,不应该再假定 Pod 有其他的phase 值
Pod phase 可能存在的值
-
挂起(Pending):Pod 已被 Kubernetes 系统接受,但有一个或者多个容器镜像尚未创建。等待时间包括调度 Pod 的时间和通过网络下载镜像的时间,这可能需要花点时间
-
运行中(Running):该 Pod 已经绑定到了一个节点上,Pod 中所有的容器都已被创建。至少有一个容器正在运行,或者正处于启动或重启状态
-
成功(Succeeded):Pod 中的所有容器都被成功终止,并且不会再重启
-
失败(Failed):Pod 中的所有容器都已终止了,并且至少有一个容器是因为失败终止。也就是说,容器以非 0 状态退出或者被系统终止
-
未知(Unknown):因为某些原因无法取得 Pod 的状态,通常是因为与 Pod 所在主机通信失败
重启策略
PodSpec 中有一个 restartPolicy 字段,可能的值为 Always、OnFailure 和 Never。默认为Always。restartPolicy 适用于 Pod 中的所有容器。restartPolicy 仅指通过同一节点上的kubelet 重新启动容器。失败的容器由 kubelet 以五分钟为上限的指数退避延迟(10秒,20秒,40秒…)重新启动,并在成功执行十分钟后重置。如 Pod 文档 中所述,一旦绑定到一个节点,Pod 将永远不会重新绑定到另一个节点。
yaml语法
简单说明
是一个可读性高,用来表达数据序列的格式。YAML 的意思其实是:仍是一种标记语言,但为了强调这种语言以数据做为中心,而不是以标记语言为重点
基本语法
- 缩进时不允许使用Tab键,只允许使用空格
- 缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
- # 标识注释,从这个字符一直到行尾,都会被解释器忽略
YAML支持的数据结构
- 对象:键值对的集合,又称为映射(mapping)/哈希(hashes)/字典(dictionary)
- 数组:一组按次序排列的值,又称为序列(sequence)/列表(list)
- 纯量(scalars):单个的、不可再分的值
对象类型:对象的一组键值对,使用冒号结构表示
name: Steve
age: 18
Yaml也允许另一种写法,将所有键值对写成一个行内对象
hash: { name: Steve, age: 18 }
数组类型:一组连词线开头的行,构成一个数组
animal:
- Cat
- Dog
animal: [Cat, Dog]
复合结构:对象和数组可以结合使用,形成复合结构
languages:
- Ruby
- Perl
- Python
websites:
YAML: yaml.org
Ruby: ruby-lang.org
Python: python.org
Perl: use.perl.org
纯量:纯量是最基本的、不可再分的值。以下数据类型都属于纯量
1 字符串 布尔值 整数 浮点数 Null
2 时间 日期
数值直接以字面量的形式表示
number: 12.30
布尔值用true和false表示
isSet: true
null用 ~ 表示
parent: ~
时间采用 ISO8601 格式
iso8601: 2001-12-14t21:59:43.10-05:00
日期采用复合 iso8601 格式的年、月、日表示
date: 1976-07-31
YAML 允许使用两个感叹号,强制转换数据类型
e: !!str 123
f: !!str true
字符串
字符串默认不使用引号表示
str: 这是一行字符串
如果字符串之中包含空格或特殊字符,需要放在引号之中
str: '内容:字符串'
单引号和双引号都可以使用,双引号不会对特殊字符转义
s1: '内容\n字符串'
s2: "内容\n字符串"
单引号之中如果还有单引号,必须连续使用两个单引号转义
# 原先使用的转义符是 \ ,在yaml中转义符是 '
str: 'labor''sday'
字符串可以写成多行,从第二行开始,必须有一个单空格缩进。换行符会被转为空格
str: 这是一段
多行
字符串
多行字符串可以使用|保留换行符,也可以使用>折叠换行
this: |
Foo
Bar
that: >
Foo
Bar
+表示保留文字块末尾的换行,-表示删除字符串末尾的换行
s1: |
Foo
s2: |+
Foo
s3: |-
Foo
Ingress
如果要使用nginx四层https加密协议代理,可以采用这种架构:
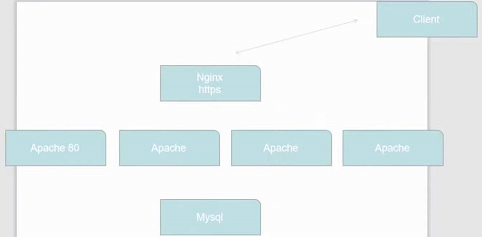
他使用nginx作为反向代理,只需nginx中配置https协议,apache跟nginx由于处于同一个内部服务,他们之间的通讯没有必要采用耗费资源的https协议,只需采用http协议就行,之后客户端通过访问nginx来访问服务,那么他们之间走的必然是https加密协议。
但如果在k8s环境中(不使用nginx而是使用service)呢?那就必须给每一个apache都安装上https加密协议,然后service再做负载均衡,才能达到效果。这显然是不合理的。
为了解决这种需求,Ingress就诞生了。
资料信息
Ingress-Nginx github地址:https://github.com/kubernetes/ingress-nginx
Ingress-Nginx官方网站:https://kubernetes.github.io/ingress-nginx/
注意:
- Ingress可以跟nginx搭配,当然也可以跟haproxy等等的搭配,这里我们就用最常用最熟悉的nginx即可
- Ingress是七层代理
看下图,客户端需要先访问域名,也就是说对于Ingress来讲必须要绑定域名(可以有多个域名,这几个域名最终访问的都是Nginx软件),毕竟他是七层代理。Nginx会反向代理负载均衡到后端的svc。
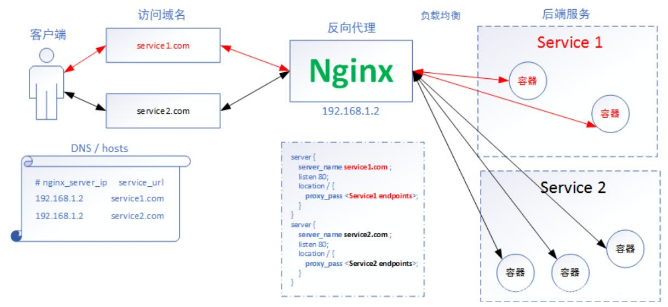
Nginx通过NodePort模式暴露给外部
在这种情况下他会帮我们配置Nginx,可以看到Nginx内部有这样一个配置文件:

在这种访问方式下,我们不需要进入Nginx内部去写配置文件,配置文件会自动添加
看一下被Ingress修改之后的Nginx进程以及协程之间的沟通机制:
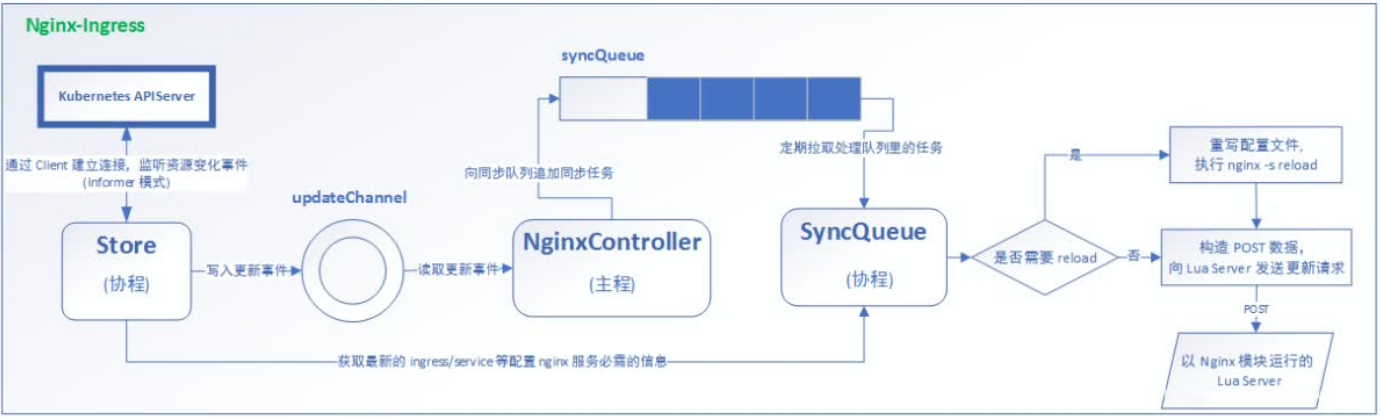
部署Ingress-Nginx
首先进入Ingress官网,进入Deployment部署页面,找到Installation Guide安装向导
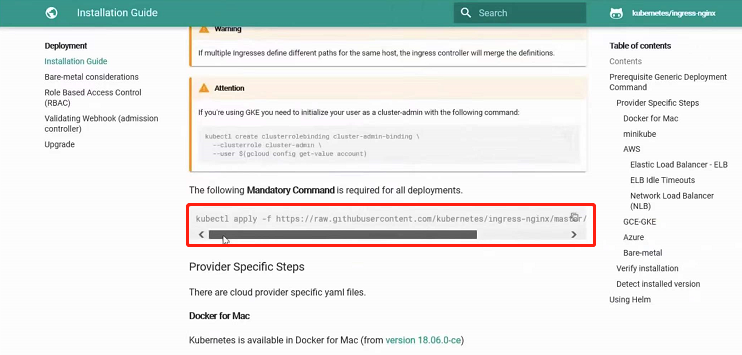
可以看到kubectl apply -f xxx后面一串其实是一个yaml文件地址,可以先创建相应的文件夹,并用wget命令把他下载下来
然后可以查看这个yaml文件中用到什么镜像,可以使用docker先把他下载下来,防止后续kubectl apply的时候很慢,通过命令cat xxx.yaml | grep image可以看到:

此时我们就知道要下载什么镜像了,使用命令docker pull xxx即可
由于是演示,我们现在要做这样的操作:首先将下载的镜像传至本地主机(Windows),再从本地主机将该镜像传至服务器,再在服务器之间传递并使用该镜像文件。可以使用命令docker save -o xxx(压缩包名) xxx(镜像id)将该镜像打包保存,使用命令tar -zcvf xxx.gz xxx.tar将文件xxx.tar打包成xxx.gz,再使用sz命令将该xxx.gz发送到本地主机(Windows),然后使用rz命令将本地主机中的xxx.gz发送到服务器上,使用命令scp xxx.gz root@k8s-node02:/root/将xxx.gz文件传至其他服务器上,之后在每个服务器上使用命令tar -zxvf xxx.gz即可做解压(解压之后其实就是xxx.tar的一个镜像文件),然后使用docker load -i xxx.tar即可加载镜像。
做完上面的步骤之后,使用kubectl apply -f xxx.yaml执行刚刚下载的yaml文件
然后再回到官网找对应的暴露模式,这里我们演示的时候使用的是裸金属架构,可以看到他说"Using NodePort"使用NodePort模式
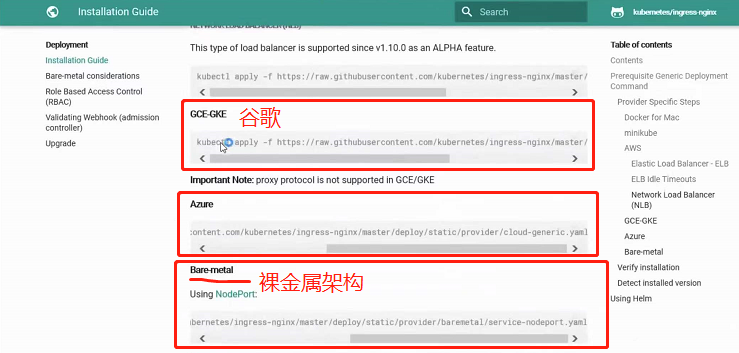
还是使用wget复制链接下载该yaml文件,然后直接kubectl apply -f xxx.yaml运行即可

这个时候已经暴露完Nginx了
要注意的是假设此时有6台服务器三主三从,此时Ingress通过NodePort暴露给外部,是指6台服务器每台服务器各自都通过NodePort将Ingress暴露给外部,那么如果要高可用的话最好在这6台服务器之上再来一个LVS或Haproxy或Nginx作为转发,原因显而易见,如果只绑定了某一台服务器,一旦这台服务器挂了,那Ingress就失效了,当然如果服务器可用性高,那么只绑定某一台服务器也是可以的
Ingress HTTP代理访问
deployment、Service、Ingress Yaml文件:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: nginx-dm
spec:
replicas: 2
template:
metadata:
labels:
name: nginx
spec:
containers:
- name: nginx
image: wangyanglinux/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
spec:
ports:
- port: 80
targetPort: 80
protocol: TCP
selector:
name: nginx
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: nginx-test
spec:
rules:
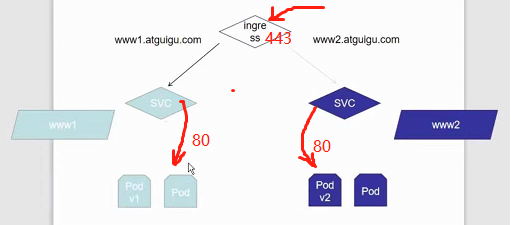
- host: www1.atguigu.com
http:
paths:
# / 表示根,意思是访问域名www1.atguigu.com的根路径
- path: /
backend:
# svc的名称
serviceName: nginx-svc
servicePort: 80
使用kubectl apply -f执行上述yaml
之后再做一下域名映射:

使用命令kubectl get svc -n ingress-nginx查看ingress-nginx暴露给外部的端口,然后通过域名加端口的方式即可访问
现在我们来搭建一个架构:
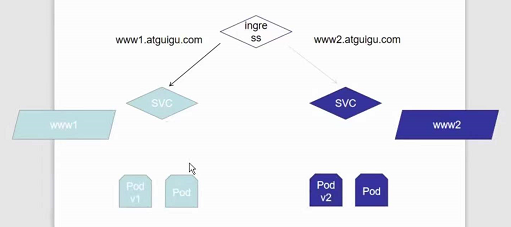
首先创建一个文件夹ingress-vh,我们在该文件夹目录下创建整个架构
创建上图左半边的deployment和svc的yaml文件并执行:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: deployment1
spec:
replicas: 2
template:
metadata:
labels:
name: nginx1
spec:
containers:
- name: nginx1
image: wangyanglinux/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: svc1
spec:
ports:
- port: 80
targetPort: 80
protocol: TCP
selector:
name: nginx1
创建上图右半边的deployment和svc的yaml文件并执行:
把上述yaml中的标签选择器和容器名称中的1改成2,然后把镜像版本由v1改成v2就是右半边的yaml文件。
创建Ingress规则:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress1
spec:
rules:
- host: www1.atguigu.com
http:
paths:
# / 表示根,意思是访问域名www1.atguigu.com的根路径
- path: /
backend:
# svc的名称
serviceName: svc1
servicePort: 80
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress2
spec:
rules:
- host: www2.atguigu.com
http:
paths:
# / 表示根,意思是访问域名www1.atguigu.com的根路径
- path: /
backend:
# svc的名称
serviceName: svc2
servicePort: 80
使用kubectl apply -f进行创建
创建完毕之后使用kubectl get pod -n ingress-nginx可以看到相关pod
使用kubectl exec xxx(pod的id) -n ingress-nginx -it -- /bin/bash
进入之后可以看到nginx.conf文件,文件中写着www1.atguigu.com和 www2.atguigu.com的代理规则
由此可见,我们刚才写的ingress规则,他会把这些规则转化成nginx配置文件注入到nginx配置文件之中,达到访问的目的
然后还是去写一下域名映射:
使用命令kubectl get svc -n ingress-nginx查看ingress-nginx暴露给外部的端口,然后通过域名加端口的方式即可访问
使用命令kubectl get ingress即可看到ingress的规则:

IngressHTTPS代理访问
创建一个新的工作目录,创建证书,以及cert存储方式
openssl req -x509 -sha256 -nodes -days 365 -newkey rsa:2048 -keyout tls.key -out tls.crt -subj "/CN=nginxsvc/O=nginxsvc"
# 以secret方式进行保存,类型为tls,创建的文件是tls-secret 使用的key(私钥)是tls.key,使用的cert(证书)是tls.crt
kubectl create secret tls tls-secret --key tls.key --cert tls.crt
deployment、Service、Ingress Yaml文件:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: deployment3
spec:
replicas: 2
template:
metadata:
labels:
name: nginx3
spec:
containers:
- name: nginx3
image: wangyanglinux/myapp:v3
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: svc3
spec:
ports:
- port: 80
targetPort: 80
protocol: TCP
selector:
name: nginx3
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: https
spec:
tls:
- hosts:
- www3.atguigu.com
# 密钥文件名要与上面创建的密钥文件名对应起来
secretName: tls-secret
rules:
- host: www3.atguigu.com
http:
paths:
# / 表示根,意思是访问域名www1.atguigu.com的根路径
- path: /
backend:
# svc的名称
serviceName: svc3
servicePort: 80
创建之后再去修改一下域名映射:
打开浏览器,使用https://www3.atguigu.com访问即可
Nginx进行BasicAuth(身份认证)
在这里我们用的ingress实现方案采用的是nginx软件,因此nginx支持的特性他都支持
yum -y install httpd
# 创建的文件名为auth,用户名为foo
htpasswd -c auth foo
# 以secret方式进行保存,类型是generic,创建的文件名是basic-auth,通过文件“auth”进行创建的
kubectl create secret generic basic-auth --from-file=auth
ingress的yaml:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-with-auth
# 如果要给ingress加密的话,只需要添加下面这几行annotations即可(具体查看官网https://kubernetes.github.io/ingress-nginx/)
annotations:
nginx.ingress.kubernetes.io/auth-type: basic
nginx.ingress.kubernetes.io/auth-secret: basic-auth
nginx.ingress.kubernetes.io/auth-realm: 'AuthenticationRequired-foo'
spec:
rules:
- host: auth.atguigu.com
http:
paths:
- path: /
backend:
serviceName: svc1
servicePort: 80
总的来讲,如果要给ingress加密的话,只需要添加上图那几行annotations即可(具体查看官网https://kubernetes.github.io/ingress-nginx/)
当然,还有一些别的知识,比如gRPC代理等都可以通过官网学习:
最后添加域名映射:
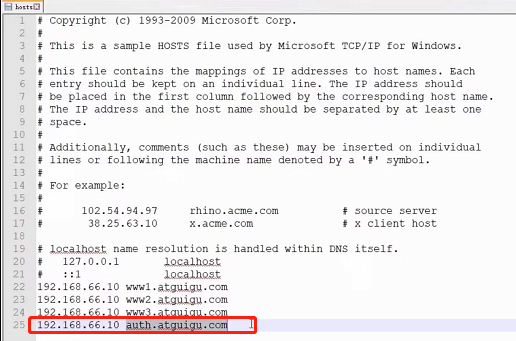
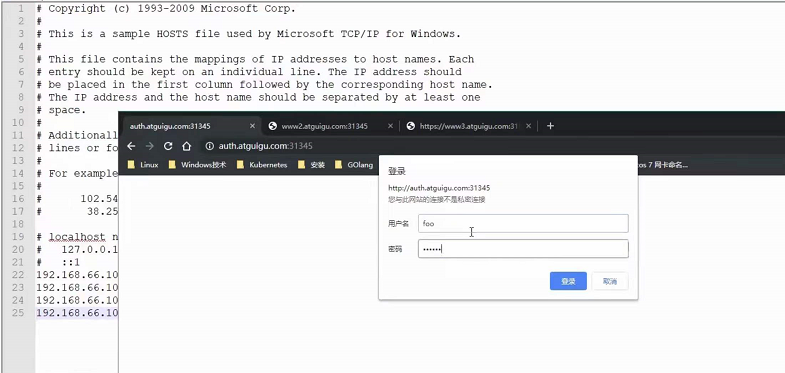
此时访问就需要输入密码了:
Nginx进行重写
| 名称 | 描述 | 类型 |
|---|---|---|
nginx.ingress.kubernetes.io/rewrite-target |
必须重定向流量的目标URI | 字符串 |
nginx.ingress.kubernetes.io/ssl-redirect |
指示位置部分是否仅可访问SSL(当Ingress包含证书时默认为True) | 布尔值 |
nginx.ingress.kubernetes.io/force-ssl-redirect |
即使Ingress未启用TLS,也强制重定向到HTTPS | 布尔值 |
nginx.ingress.kubernetes.io/app-root |
定义Controller必须重定向的应用程序根,如果它在'/‘上下文中 | 字符串 |
nginx.ingress.kubernetes.io/use-regex |
指示Ingress上定义的路径是否使用正则表达式 | 布尔值 |
案例:
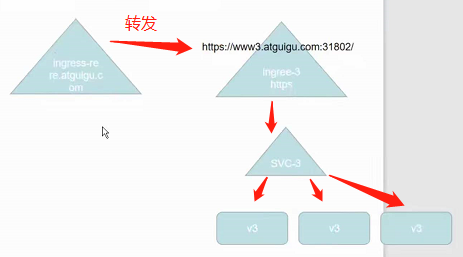
我们想实现客户端访问一个ingress的流量全部转发到另一个ingress
yaml文件:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: nginx-test
annotations:
nginx.ingress.kubernetes.io/rewrite-target: https://www3.atguigu.com:31802
spec:
rules:
- host: re.atguigu.com
http:
paths:
- path: /
backend:
serviceName: svc1
servicePort: 80
添加域名映射:
此时访问re.atguigu.com就能跳转到https://www3.atguigu.com:31802
如果要了解更多,直接去官网:https://kubernetes.github.io/ingress-nginx/
存储
ConfigMap
ConfigMap介绍
ConfigMap功能在Kubernetes1.2版本中引入,许多应用程序会从配置文件、命令行参数或环境变量中读取配置信息。ConfigMap API给我们提供了向容器中注入配置信息的机制,ConfigMap可以被用来保存单个属性,也可以用来保存整个配置文件或者JSON二进制大对象。
首先来看看配置文件注册中心,如果有多个集群,每个集群有多个nginx,那么一旦集群需要修改nginx配置文件的时候,会去配置文件注册中心索要自己集群的配置文件,配置中心会根据一些信息匹配对应的集群,比如主机名、ip地址等,匹配到之后会分配对应的配置文件,不同的集群会索要到不同的配置文件。这样配置文件变动只需要在配置中心变动即可了,一旦配置中心变动就能触发对应集群的进程去修改集群内的配置文件,非常方便。
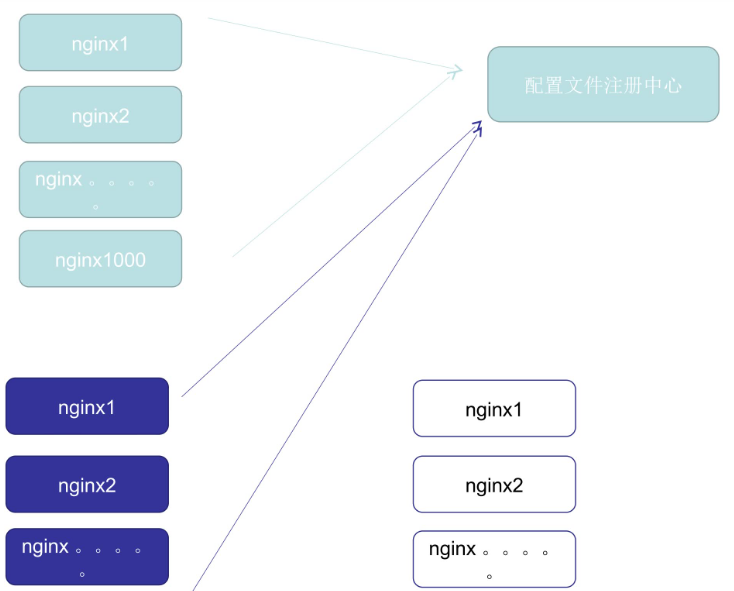
k8s中也是类似配置文件注册中心向下分发的模式:
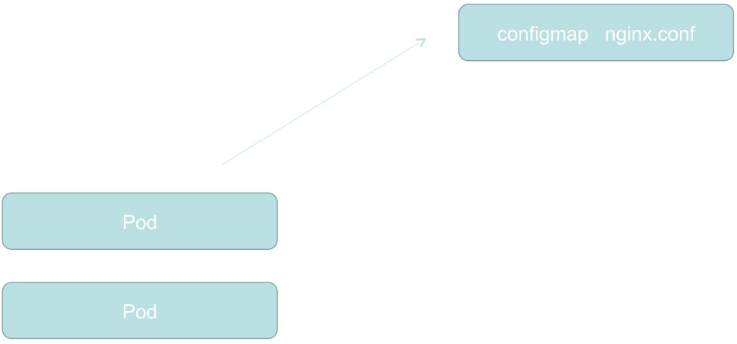
pod用到相关配置时会去configMap中寻找相关配置文件,一旦configMap发生变动,pod中的配置也会变,当然nginx不支持热更新(traefik就支持,traefik是用go写的类似nginx的工具),需要重新加载pod配置才能生效
ConfigMap的创建
Ⅰ、使用目录创建
$ ls docs/user-guide/configmap/kubectl/
game.properties
ui.properties
$ cat docs/user-guide/configmap/kubectl/game.properties
enemies=aliens
lives=3
enemies.cheat=true
enemies.cheat.level=noGoodRotten
secret.code.passphrase=UUDDLRLRBABAS
secret.code.allowed=true
secret.code.lives=30
$ cat docs/user-guide/configmap/kubectl/ui.properties
color.good=purple
color.bad=yellow
allow.textmode=true
how.nice.to.look=fairlyNice
$ kubectl create configmap game-config --from-file=docs/user-guide/configmap/kubectl
--from-file指定在目录下的所有文件都会被用在ConfigMap里面创建一个键值对,键的名字就是文件名,值就是文件的内容
使用kubectl get configmap或kubectl get cm查看ConfigMap
使用kubectl get cm game-config(具体某个ConfigMap) -o yaml可以看到该ConfigMap的具体yaml信息(配置信息、键名键值等)
也可以使用kubectl describe cm game-config(具体某个ConfigMap)来查看该ConfigMap的具体信息(配置信息、键名键值等)
Ⅱ、使用文件创建
只要指定为一个文件就可以从单个文件中创建ConfigMap
$ kubectl create configmap game-config-2 --from-file=docs/user-guide/configmap/kubectl/game.properties
$ kubectl get configmaps game-config-2 -o yaml
--from-file这个参数可以使用多次,你可以使用两次分别指定上个实例中的那两个配置文件,效果就跟指定整个目录是一样的
Ⅲ、使用字面值创建
使用文字值创建,利用--from-literal参数传递配置信息,该参数可以使用多次,格式如下
$ kubectl create configmap special-config --from-literal=special.how=very --from-literal=special.type=charm
$ kubectl get configmaps special-config -o yaml
Pod中使用ConfigMap
Ⅰ、使用ConfigMap来替代环境变量
apiVersion: v1
kind: ConfigMap
metadata:
name: special-config
namespace: default
data:
special.how: very
special.type: charm
apiVersion: v1
kind: ConfigMap
metadata:
name: env-config
namespace: default
data:
log_level: INFO
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-pod
spec:
containers:
- name: test-container
image: hub.atguigu.com/library/myapp:v1
command: ["/bin/sh","-c","env"]
# 第一种注入方式(两种方式可以共用)
env:
- name: SPECIAL_LEVEL_KEY
valueFrom:
configMapKeyRef:
name: special-config
key: special.how
- name: SPECIAL_TYPE_KEY
valueFrom:
configMapKeyRef:
name: special-config
key: special.type
# 第二种注入方式(两种方式可以共用)
envFrom:
- configMapRef:
name: env-config
restartPolicy: Never
通过kubectl create -f命令创建该pod之后,由于执行了命令/bin/sh -c env,因此pod中会输出环境变量,可以使用kubectl log dapi-test-pod(pod名称)打印pod日志,就可以看到通过ConfigMap注入pod的环境变量被输出
Ⅱ、用ConfigMap设置命令行参数
apiVersion: v1
kind: ConfigMap
metadata:
name: special-config
namespace: default
data:
special.how: very
special.type: charm
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-pod
spec:
containers:
- name: test-container
image: hub.atguigu.com/library/myapp:v1
command: ["/bin/sh","-c","echo $(SPECIAL_LEVEL_KEY)$(SPECIAL_TYPE_KEY)"]
env:
- name: SPECIAL_LEVEL_KEY
valueFrom:
configMapKeyRef:
name: special-config
key: special.how
- name: SPECIAL_TYPE_KEY
valueFrom:
configMapKeyRef:
name: special-config
key: special.type
restartPolicy: Never
通过kubectl create -f命令创建该pod,使用kubectl log命令查看pod日志,可以看到通过ConfigMap注入pod的环境变量被输出
Ⅲ、通过数据卷插件使用ConfigMap
apiVersion: v1
kind: ConfigMap
metadata:
name: special-config
namespace: default
data:
special.how: very
special.type: charm
在数据卷里面使用这个ConfigMap,有不同的选项。最基本的就是将文件填入数据卷,在这个文件中,键就是文件名,键值就是文件内容
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-pod
spec:
containers:
- name: test-container
image: hub.atguigu.com/library/myapp:v1
command: ["/bin/sh","-c","cat /etc/config/special.how"]
volumeMounts:
- name: config-volume
mountPath: /etc/config
volumes:
- name: config-volume
configMap:
name: special-config
restartPolicy: Never
创建了pod之后,可以用kubectl log查看输出日志来判断ConfigMap是否被注入,也可以直接使用kubectl exec xxx -it -- /bin/bash或kubectl exec xxx -it -- /bin/sh进入pod中然后使用cat命令来做判断,当然也可以直接使用kubectl exec xxx -it -- cat /etc/config/special.how来做判断
ConfigMap的热更新
apiVersion: v1
kind: ConfigMap
metadata:
name: log-config
namespace: default
data:
log_level: INFO
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: my-nginx
spec:
replicas: 1
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- name: my-nginx
image: hub.atguigu.com/library/myapp:v1
ports:
- containerPort: 80
volumeMounts:
- name: config-volume
mountPath: /etc/config
volumes:
- name: config-volume
configMap:
name: log-config
$ kubectl exec `kubectl get pods -l run=my-nginx -o=name|cut -d "/" -f2` cat/etc/config/log_level
INFO
修改ConfigMap
$ kubectl edit configmap log-config
修改log_level的值为DEBUG等待大概10秒钟时间,再次查看环境变量的值
$ kubectl exec `kubectl get pods -l run=my-nginx -o=name|cut -d "/" -f2` cat /tmp/log_level
DEBUG
当然,如果把这个思想应用到修改nginx配置文件时,由于nginx只在启动时会去看一次配置文件,之后就不会再去看了,所以配置文件改了对于已经启动的nginx来说没有什么影响,除非把pod重启,被修改的配置才会生效
ConfigMap更新后滚动更新Pod
更新ConfigMap目前并不会触发相关Pod的滚动更新,可以通过修改pod annotations的方式强制触发滚动更新
$ kubectl patch deployment my-nginx --patch '{"spec": {"template": {"metadata": {"annotations": {"version/config": "20190411"}}}}}'
这个例子里我们在.spec.template.metadata.annotations中添加version/config,每次通过修改version/config来触发滚动更新
更新ConfigMap后:
- 使用该ConfigMap挂载的Env不会同步更新
- 使用该ConfigMap挂载的Volume中的数据需要一段时间(实测大概10秒)才能同步更新
Secret
Secret存在意义
Secret解决了密码、token、密钥等敏感数据的配置问题,而不需要把这些敏感数据暴露到镜像或者Pod Spec中。Secret可以以Volume或者环境变量的方式使用
Secret有三种类型:
-
Service Account
用来访问Kubernetes API,由Kubernetes自动创建,并且会自动挂载到Pod的
/run/secrets/kubernetes.io/serviceaccount目录中 -
Opaque
base64编码格式的Secret,用来存储密码、密钥等
-
kubernetes.io/dockerconfigjson用来存储私有docker registry的认证信息
Service Account(不常用)
像flannel、coreDNS这些组件都是需要跟Kubernetes API进行交互的,显然Kubernetes API有可能会造成一些安全问题,因此Kubernetes API不能随便对外提供访问,因为他是k8s一切交互的入口,他的加密就等于集群的加密
为了安全,pod的访问机制就是Service Account,他通过挂载Service Account来保证安全
Service Account用来访问Kubernetes API,由Kubernetes自动创建,并且会自动挂载到Pod的/run/secrets/kubernetes.io/serviceaccount目录中
简单来看一下:
使用kubectl get pod -n kube-system,然后随便找一个pod进入,cd到secrets/kubernetes.io目录下,有一个文件夹serviceaccount,进入之后有三个文件:ca.crt(密钥)、namespace(名称空间)、token(认证信息)。由这三个组成了Service Account,也正是这三个文件让kube proxy能够通过认证访问api。
$ kubectl run nginx --image nginx
deployment "nginx" created
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-3137573019-md1u2 1/1 Running 0 13s
$ kubectl exec nginx-3137573019-md1u2 ls /run/secrets/kubernetes.io/serviceaccount
ca.crt
namespace
token
Opaque Secret
Ⅰ、创建说明
Opaque类型的数据是一个map类型,要求value是base64编码格式:
$ echo -n "admin" | base64
YWRtaW4=
$ echo -n "1f2d1e2e67df" | base64
MWYyZDFlMmU2N2Rm
secrets.yml:
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
password: MWYyZDFlMmU2N2Rm
username: YWRtaW4=
使用kubectl apply -f创建,使用kubectl get secret查看,如果要看系统的secret,则可以使用kubectl get secret -n kube-system
Ⅱ、使用方式
1、将Secret挂载到Volume中
apiVersion: v1
kind: Pod
metadata:
labels:
name: seret-test
name: seret-test
spec:
volumes:
- name: secrets
secret:
secretName: mysecret
containers:
- image: hub.atguigu.com/library/myapp:v1
name:db
volumeMounts:
- name: secrets
mountPath: "
readOnly: true
2、将Secret导出到环境变量中
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: pod-deployment
spec:
replicas: 2
template:
metadata:
labels:
app: pod-deployment
spec:
containers:
- name: pod-1
image: hub.atguigu.com/library/myapp:v1
ports:
- containerPort: 80
env:
- name: TEST_USER
valueFrom:
secretKeyRef:
name: mysecret
key: username
-name: TEST_PASSWORD
valueFrom:
secretKeyRef:
name: mysecret
key: password
kubernetes.io/dockerconfigjson
进入docker harbor,创建一个私有仓库,远程客户端上登录harbor之后推送一个镜像上去
使用Kuberctl创建docker registry认证的secret
$ kubectl create secret docker-registry myregistrykey --docker-server=DOCKER_REGISTRY_SERVER --docker-username=DOCKER_USER --docker-password=DOCKER_PASSWORD --docker-email=DOCKER_EMAIL
secret "myregistrykey" created.
在创建Pod的时候,通过imagePullSecrets来引用刚创建的myregistrykey
apiVersion: v1
kind: Pod
metadata:
name: foo
spec:
containers:
- name: foo
image: roc/awangyang:v1
imagePullSecrets:
- name: myregistrykey
Volume
容器磁盘上的文件的生命周期是短暂的,这就使得在容器中运行重要应用时会出现一些问题。首先,当容器崩溃时,kubelet会重启它,但是容器中的文件将丢失——容器以干净的状态(镜像最初的状态)重新启动。其次,在Pod中同时运行多个容器时,这些容器之间通常需要共享文件。Kubernetes中的Volume抽象就很好的解决了这些问题
之前讲过,pod在启动时会先启动pause,pause的主要目的是共享网络和存储卷,一旦volume挂载到pod之后,pod中所有的容器都可以在一个固定的位置访问到卷
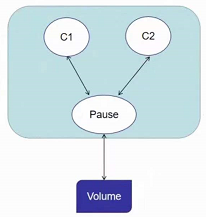
上图中c1、c2可能会销毁重建,但volume的位置不变,意味着存储卷不会消失
背景
Kubernetes中的卷有明确的寿命——与封装它的Pod相同。所f以,卷的生命比Pod中的所有容器都长,当这个容器重启时数据仍然得以保存。当然,当Pod不再存在时,卷也将不复存在。也许更重要的是,Kubernetes支持多种类型的卷,Pod可以同时使用任意数量的卷
卷的类型
Kubernetes支持以下类型的卷:
- awsElasticBlockStore
- azureDisk
- azureFile
- cephfs(分布式私有云存储,如何搭建使用自行百度)
- csi
- downwardAPI
- emptyDir
- fc
- flocker
- gcePersistentDisk
- gitRepo
- glusterfs
- hostPath
- iscsi
- local
- nfs
- persistentVolumeClaim
- projected
- portworxVolume
- quobyte
- rbd
- scaleIO
- secret
- storageos
- vsphereVolume
emptyDir
当Pod被分配给节点时,首先创建emptyDir卷,并且只要该Pod在该节点上运行,该卷就会存在。正如卷的名字所述,它最初是空的。Pod中的容器可以读取和写入emptyDir卷中的相同文件,尽管该卷可以挂载到每个容器中的相同或不同路径上。当出于任何原因从节点中删除Pod时,emptyDir中的数据将被永久删除
注意,容器崩溃不会从节点中移除pod,因此emptyDir卷中的数据在容器崩溃时是安全的

emptyDir的用法有:
- 暂存空间,例如用于基于磁盘的合并排序
- 用作长时间计算崩溃恢复时的检查点,例如容器重载的时候需要某些数据去执行恢复,但这些数据又不需要持久化,那就可以将数据存放在空卷中
- Web服务器容器提供数据时,保存内容管理器容器提取的文件,例如有一个web容器,他运行的时候会需要一些文件存在,那就可以去某个地方下载这些文件并保存到空卷中去使用
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: k8s.gcr.io/test-webserver
name: test-container1
volumeMounts:
- mountPath: /cache
name: cache-volume
- image: xxx
name: test-container2
volumeMounts:
- mountPath: /test
name: cache-volume
volumes:
- name: cache-volume
emptyDir: {}
此时进入test-container1的/cache目录下写一些东西,就能在test-container2的/test目录下看到了
hostPath
hostPath卷将主机节点的文件系统中的文件或目录挂载到集群中
hostPath的用途如下:
- 运行需要访问Docker内部的容器;使用
/var/lib/docker的hostPath - 在容器中运行cAdvisor;使用
/dev/cgroups的hostPath - 允许pod指定给定的hostPath是否应该在pod运行之前存在,是否应该创建,以及它应该以什么形式存在
除了所需的path属性之外,用户还可以为hostPath卷指定type
| 值 | 行为 |
|---|---|
| 空字符串(默认)用于向后兼容,这意味着在挂载hostPath卷之前不会执行任何检查。 | |
| DirectoryOrCreate | 如果在给定的路径上没有任何东西存在,那么将根据需要在那里创建一个空目录,权限设置为0755,与Kubelet具有相同的组和所有权。 |
| Directory | 给定的路径下必须存在目录 |
| FileOrCreate | 如果在给定的路径上没有任何东西存在,那么会根据需要创建一个空文件,权限设置为0644,与Kubelet具有相同的组和所有权。 |
| File | 给定的路径下必须存在文件 |
| Socket | 给定的路径下必须存在UNIX套接字 |
| CharDevice | 给定的路径下必须存在字符设备 |
| BlockDevice | 给定的路径下必须存在块设备 |
使用这种卷类型时请注意,因为:
- 由于每个节点上的文件都不同,具有相同配置(例如从podTemplate创建的)的pod在不同节点上的行为可能会有所不同(比方说一个节点有
/test目录,但另一个没有,pod挂载的时候使用的都是/test目录,那么没有/test目录的节点必然会报错) - 当Kubernetes按照计划添加资源感知调度时,将无法考虑hostPath使用的资源(资源管控不受k8s控制,而是受本机控制)
- 在底层主机上创建的文件或目录只能由root写入。您需要在特权容器中以root身份运行进程,或修改主机上的文件权限以便写入hostPath卷(文件没有操作权限自然就会报错,解决方法很简单就是赋予文件与kubelet相同的权限)
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: k8s.gcr.io/test-webserver
name: test-container
volumeMounts:
- mountPath: /test-pd
name: test-volume
volumes:
- name: test-volume
hostPath:
# directory location on host
path: /data
# this field is optional
type: Directory
hostPath非常灵活,理论上只要存储能共享到主机,就能使用
案例:
远程文件存储服务集群配合hostPath

PersistentVolume
概念
PersistentVolume(PV)
是由管理员设置的存储,它是群集的一部分。就像节点是集群中的资源一样,PV也是集群中的资源。PV是Volume之类的卷插件,但具有独立于使用PV的Pod的生命周期。此API对象包含存储实现的细节,即NFS、iSCSI或特定于云供应商的存储系统
为什么要有PV?
有了PV之后Pod使用存储卷与存储卷本身的部署就可以解耦了
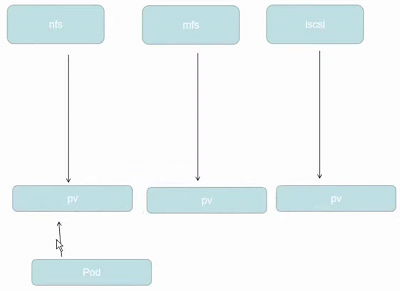
PersistentVolumeClaim(PVC)
是用户存储的请求。它与Pod相似。Pod消耗节点资源,PVC消耗PV资源。Pod可以请求特定级别的资源(CPU和内存)。声明可以请求特定的大小和访问模式(例如,可以以读/写一次或只读多次模式挂载)
静态pv
集群管理员创建一些PV。它们带有可供群集用户使用的实际存储的细节。它们存在于Kubernetes API中,可用于消费
动态
当管理员创建的静态PV都不匹配用户的PersistentVolumeClaim时,集群可能会尝试动态地为PVC创建卷。此配置基于StorageClasses(SC):PVC必须请求[存储类],并且管理员必须创建并配置该类才能进行动态创建。声明该类为"“可以有效地禁用其动态配置要启用基于存储级别的动态存储配置,集群管理员需要启用API server上的DefaultStorageClass[准入控制器]。例如,通过确保DefaultStorageClass位于API server组件的--admission-control标志,使用逗号分隔的有序值列表中,可以完成此操作
绑定
master中的控制环路监视新的PVC,寻找匹配的PV(如果可能),并将它们绑定在一起。如果为新的PVC动态调配PV,则该环路将始终将该PV绑定到PVC。否则,用户总会得到他们所请求的存储,但是容量可能超出要求的数量。一旦PV和PVC绑定后,PersistentVolumeClaim绑定是排他性的,不管它们是如何绑定的。PVC跟PV绑定是一对一的映射。绑定时,PV的空间大小基本是大于PVC的请求空间大小的,很少出现刚好等于的情况
为什么要有PVC?
因为如果只有PV的话,PV的大小、速度以及这个PV到底满不满足我Pod的要求等都需要我自己去做匹配,当有成千上万个PV的时候就很麻烦了,此时给每一个Pod配置一个PVC,让他自己去匹配合适的PV即可
比方说上图,Pod的PVC要求是:强壮、10GB的空间大小,那么就会匹配到合适的PV,注意这里为什么没有匹配到“强壮、20GB空间”的PV呢?因为已经有一个“强壮、11GB空间”的PV满足了我的要求了
持久化卷声明的保护
PVC保护的目的是确保由pod正在使用的PVC不会从系统中移除,因为如果被移除的话可能会导致数据丢失(pod被删除之后pvc依然会存在于系统之中,并且依然会与pv绑定)
注意,当pod状态为“Pending”并且pod已经分配给节点或pod为“Running”状态时,pvc处于活动状态
当启用PVC保护alpha功能时,如果用户删除了一个pod正在使用的PVC,则该PVC不会被立即删除。PVC的删除将被推迟,直到PVC不再被任何pod使用
持久化卷类型
PersistentVolume类型以插件形式实现。Kubernetes目前支持以下插件类型:
- GCEPersistentDisk
- AWSElasticBlockStore
- AzureFile
- AzureDisk
- FC (Fibre Channel)
- FlexVolume
- Flocker
- NFS
- iSCSI
- RBD (Ceph Block Device)
- CephFS
- Cinder (OpenStack block storage)
- Glusterfs
- VsphereVolume
- Quobyte
- Volumes
- HostPath
- VMware
- Photon
- Portworx
- Volumes
- ScaleIO
- Volumes
- StorageOS
持久卷演示代码:
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv0003
spec:
capacity:
storage: 5Gi
volumeMode: Filesystem
accessModes:
# ReadWriteOnce表示同一时间只允许一个人过来进行读写,超过一个人是不允许的
- ReadWriteOnce
# 回收策略
persistentVolumeReclaimPolicy: Recycle
storageClassName: slow
# mountOptions可以不用指定,让他自行判断
mountOptions:
- hard
- nfsvers=4.1
nfs:
path: /tmp
server: 172.17.0.2
解释一下上面的“storageClassName”,比方说有三类存储,分别为慢、中、快,我们可以将他们分为一类、二类、三类:
此时设置“storageClassName”为二类的话,那么就会匹配到二类的存储卷。storageClassName是用于划分存储的非常重要的指标
PV访问模式
PersistentVolume可以以资源提供者支持的任何方式挂载到主机上。如下表所示,供应商具有不同的功能,每个PV的访问模式都将被设置为该卷支持的特定模式。例如,NFS可以支持多个读/写客户端,但特定的NFS PV可能以只读方式导出到服务器上。每个PV都有一套自己的用来描述特定功能的访问模式
-
ReadWriteOnce
该卷可以被单个节点以读/写模式挂载
-
ReadOnlyMany
该卷可以被多个节点以只读模式挂载
-
ReadWriteMany
该卷可以被多个节点以读/写模式挂载
在命令行中,访问模式缩写为:
-
RWO
ReadWriteOnce
-
ROX
ReadOnlyMany
-
RWX
ReadWriteMany
注意,一个卷一次只能使用一种访问模式挂载,即使他支持很多访问模式。例如,GCEPersistentDisk可以由单个节点作为ReadWriteOnce模式挂载,或由多个节点以ReadOnlyMany模式挂载,但不能同时挂载
| Volume 插件 | ReadWriteOnce | ReadOnlyMany | ReadWriteMany |
|---|---|---|---|
| AWSElasticBlockStoreAWSElasticBlockStore | ✓ | - | - |
| AzureFile | ✓ | ✓ | ✓ |
| AzureDisk | ✓ | - | - |
| CephFS | ✓ | ✓ | ✓ |
| Cinder | ✓ | - | - |
| FC | ✓ | ✓ | - |
| FlexVolume | ✓ | ✓ | - |
| Flocker | ✓ | - | - |
| GCEPersistentDisk | ✓ | ✓ | - |
| Glusterfs | ✓ | ✓ | ✓ |
| HostPath | ✓ | - | - |
| iSCSI | ✓ | ✓ | - |
| PhotonPersistentDisk | ✓ | - | - |
| Quobyte | ✓ | ✓ | ✓ |
| NFS | ✓ | ✓ | ✓ |
| RBD | ✓ | ✓ | - |
| VsphereVolume | ✓ | - | -(当pod并列时有效) |
| PortworxVolume | ✓ | - | ✓ |
| ScaleIO | ✓ | ✓ | - |
| StorageOS | ✓ | - | - |
回收策略
-
Retain(保留)
手动回收
-
Recycle(回收)
基本擦除(
rm -rf /thevolume/*) -
Delete(删除)
关联的存储资产(例如AWS EBS、GCE PD、Azure Disk和OpenStack Cinder卷)将被删除
当前,只有NFS和HostPath支持回收策略(NFS现在可能已经废弃了回收策略)。AWS EBS、GCE PD、Azure Disk和Cinder卷支持删除策略
状态
卷可以处于以下的某种状态:
-
Available(可用)
一块空闲资源还没有被任何声明绑定
-
Bound(已绑定)
卷已经被声明绑定
注意,如果访问模式是“ReadWriteMany”,则还是可以被其他的所使用的
-
Released(已释放)
声明被删除,但是资源还未被集群重新声明
-
Failed(失败)
该卷的自动回收失败
命令行会显示绑定到PV的PVC的名称
持久化演示说明 - NFS
Ⅰ、安装NFS服务器
yum install -y nfs-common nfs-utils rpcbind
mkdir /nfsdata
chmod 666 /nfsdata
chown nfsnobody /nfsdata
cat /etc/exports
/nfsdata *(rw,no_root_squash,no_all_squash,sync)
systemctl start rpcbind
systemctl start nfs
解释一下上面的“cat /etc/exports
/nfsdata *(rw,no_root_squash,no_all_squash,sync)”:
实际演示中,老师是这么操作的:首先vim /etc/exports,打开文件之后直接写入/nfsdata *(rw,no_root_squash,no_all_squash,sync),然后wq退出。/nfsdata *(rw,no_root_squash,no_all_squash,sync)的具体意义是:对于/nfsdata下的所有文件,赋予rw(读写权限)、no_root_squash,no_all_squash(管理员权限)、sync(同步方式)
安装完NFS服务器之后去所有的k8s节点安装nfs客户端以及rpcbind:
yum install -y nfs-utils rpcbind
然后在k8s集群使用命令showmount -e NFS服务器ip地址可以看到NFS服务器文件挂载目录:

使用命令mount -t nfs NFS服务器ip地址:可以看到NFS服务器文件挂载目录 本机文件挂载目录就可以进行挂载:

然后进入本机/test目录,写一个文件进去,然后执行umount /test取消挂载,执行rm -rf /test删除test文件夹
以上操作就是测试一下nfs能不能被节点使用
Ⅱ、部署PV
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfspv1
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
# storageClassName的名字可以自定义的,比方说可以叫v1、v2等都是可以的
storageClassName: nfs
nfs:
path: /nfsdata
server: 192.168.66.100
使用kubectl create -f命令创建PV,使用kubectl get pv查看PV
Ⅲ、创建服务并使用PVC
apiVersion: v1
kind: Service
metadata:
# svc名称叫“nginx”,与下面创建StatefulSet的serviceName相对应
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
# 无头服务
clusterIP: None
selector:
app: nginx
---
# 如果要创建一个StatefulSet,必须要先创建一个无头svc
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
selector:
matchLabels:
app: nginx
# serviceName为“nginx”,与上面创建svc的name相对应
serviceName: "nginx"
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: k8s.gcr.io/nginx-slim:0.8
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "nfs"
resources:
requests:
storage: 1Gi
如果为了服务方便要多创建几个PV,可以再去NFS服务器,执行命令vim /etc/exports,追加输入:
/nfsdata1 *(rw,no_root_squash,no_all_squash,sync)
/nfsdata2 *(rw,no_root_squash,no_all_squash,sync)
/nfsdata3 *(rw,no_root_squash,no_all_squash,sync)
保存退出,执行以下命令:
# 创建文件夹
mkdir /nfs{1..3}
# 修改权限
chmod 777 nfsdata1/ nfsdata2/ nfsdata3/
# 修改组
chown nfsnobody nfs1/ nfs2/ nfs3/
systemctl restart rpcbind
systemctl restart nfs
回到k8s集群,测试nfs各个文件目录是否可用:
mount -t nfs 192.168.66.100:/nfsdata1 /test
date > /test/index.html
umount /test/
rm -rf /test/
没有报错,说明测试通过,此时可以创建PV了:
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfspv2
spec:
capacity:
storage: 5Gi
accessModes:
- ReadOnlyMany
persistentVolumeReclaimPolicy: Retain
# storageClassName的名字可以自定义的,比方说可以叫v1、v2等都是可以的
storageClassName: nfs
nfs:
path: /nfsdata1
server: 192.168.66.100
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfspv3
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
# storageClassName的名字可以自定义的,比方说可以叫v1、v2等都是可以的
storageClassName: nfs
nfs:
path: /nfsdata2
server: 192.168.66.100
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfspv4
spec:
capacity:
storage: 5Gi
accessModes:
- ReadOnlyMany
persistentVolumeReclaimPolicy: Retain
# storageClassName的名字可以自定义的,比方说可以叫v1、v2等都是可以的
storageClassName: slow
nfs:
path: /nfsdata3
server: 192.168.66.100
使用kubectl create -f创建PV,使用kubectl get pv查看PV
此时如果再去执行上方“Ⅲ、创建服务并使用PVC”的yaml文件的话,注意副本数是3,执行kubectl get pod会发现有一个pod启动失败,还有一个pod根本没有被创建(原因在于副本数为3,pod按照顺序创建,如果有一个pod创建失败,后续的pod根本就不会再被创建了),使用命令kubectl describe pod 启动失败pod的NAME可以看到如下:

原因在于,首先看到“Ⅲ、创建服务并使用PVC”的yaml文件,PVC匹配PV的时候他有两个条件:1、storageClassName为nfs;2、accessModes为“ReadWriteOnce”。我们再使用命令kubectl get pv可以看到:

同时满足这两个条件的只有上图绿圈圈起来的这个PV,可以看到这个PV已经被绑定了,因此如果副本数为3,第一个副本确实可以创建成功,但是第二个就会失败了(因为PV和PVC的绑定一一对应),第三个由于第二个失败因此根本不会被创建
此时我们将其中两个不符合条件的PV修改成符合条件的,可以使用kubectl delete pv删除其中两个PV(当然这个删除操作也是可以不做的,这里我们不想创建太多的PV因此做了删除),然后按照上面的方式重新创建两个PV(注意storageClassName要为“nfs”,accessModes要为“ReadWriteOnce”),使用kubectl create -f进行创建
PV一旦创建完,执行kubectl get pod会发现那三个副本都被正常创建了,执行kubectl get pv可以看到有三个PV被绑定,执行kubectl get pvc也可以看到三个状态为已绑定的PVC

那么假如这个时候我们要测试一下nfspv1,使用kubectl describe pv nfspv1可以看到挂载路径:
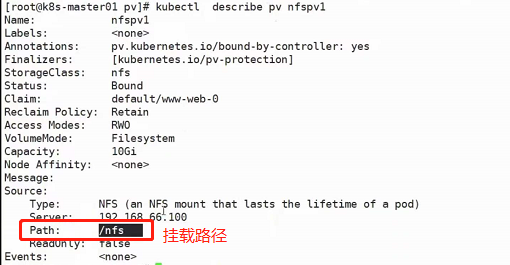
那么可以去NFS服务器,进入目录/nfs,创建index.html并写入一些内容,执行chmod 777 index.html,然后回到k8s集群,执行kubectl get pod -o wide查看pod的ip地址,取任意一个ip地址,使用curl去访问,就可以看到刚才写入NFS服务器的/nfs目录下的index.html中的内容了
然后测试一下statefulSet重启会不会导致数据丢失,执行kubectl delete pod,由于指定了副本数为3,因此会自动启动pod直到pod数为3为止,此时会发现重新起来的pod的ip地址发生了变化,但是为什么还是能正确访问呢?之前说过,是因为NAME不会变:

也就是说可以通过coredns的解析,解析得到的fqdn(Fully Qualified Domain Name)全限定域名一致(这里的fqdn就是上图的NAME,即web-0、web-1、web-2这些),因此可以正确访问
此时执行curl 10.244.2.87会发现数据并没有丢失,这也是StatefulSet的特性
关于StatefulSet
-
匹配Pod name (网络标识)的模式为:
$(statefulset名称)-$(序号),比如上面的示例:web-0,web-1,web-2 -
StatefulSet为每个Pod副本创建了一个DNS域名,这个域名的格式为:
$(podname).(headless servername),也就意味着服务间是通过Pod域名来通信而非Pod IP,因为当Pod所在Node发生故障时,Pod会被飘移到其它Node上,Pod IP会发生变化,但是Pod域名不会有变化(换句话说,之后访问可以用fqdn全限定域名(上面示例的fqdn其实就是NAME,即web-0、web-1、web-2这些)去访问,而不是用ip去访问)测试:

test-pd是一个服务,web-0、web-1、web-2是另一个服务的三个副本,那我们先要进入test-pd服务,然后用域名去ping另一个服务,操作如下:
直接进入
test-pd,然后按照格式$(podname).(headless servername)去ping即可,当然另一个服务的podname是web-0,headless servername可以通过执行命令kubectl get svc来查看,可以得知是nginx,因此执行ping web-0.nginx即可ping通web-0,此时执行kubectl delete pod删除web-0副本,k8s会自动再新建一个web-0副本以维持副本数,此时再次执行ping web-0.nginx发现还能ping通只不过ip变掉了,这就是fqdn的作用。 -
StatefulSet使用Headless服务来控制Pod的域名,这个域名的FQDN为:
$(servicename).$(namespace).svc.cluster.local,其中,“cluster.local”指的是集群的域名测试:
首先执行
kubectl get pod -o wide -n kube-system查看k8s的dns服务地址: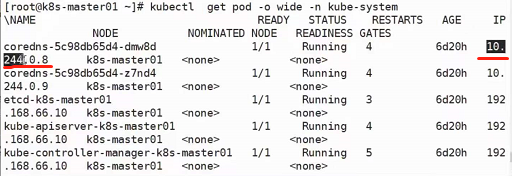
执行
dig -t A myapp-headless.default.svc.cluster.local. @10.244.0.8可以看到对应关系:

这也是能实现绑定地址不同的原因,通过我们的无头服务进行绑定的
-
根据volumeClaimTemplates,为每个Pod创建一个pvc,pvc的命名规则匹配模式:
(volumeClaimTemplates.name)-(pod_name),比如上面的volumeMounts.name=www,Podname=web-[0-2],因此创建出来的PVC是www-web-0、www-web-1、www-web-2 -
删除Pod不会删除其pvc,手动删除pvc将自动释放pv
Statefulset的启停顺序:
-
有序部署:部署StatefulSet时,如果有多个Pod副本,它们会被顺序地创建(从0到
N-1)并且,在下一个Pod运行之前所有之前的Pod必须都是Running和Ready状态。 -
有序删除:当Pod被删除时,它们被终止的顺序是从
N-1到0。测试:执行
kubectl get pod -w监听pod的情况,启动另一个终端窗口执行kubectl delete statefulset --all删除statefulSet:
会发现先删除
web-2再删除web-1最后删除web-0 -
有序扩展:当对Pod执行扩展操作时,与部署一样,它前面的Pod必须都处于Running和Ready状态。
StatefulSet使用场景:
- 稳定的持久化存储,即Pod重新调度后还是能访问到相同的持久化数据,基于PVC来实现。
- 稳定的网络标识符,即Pod重新调度后其PodName和HostName不变(注意这里是PodName和HostName不变,而不是IP地址不变)。
- 有序部署,有序扩展,基于init containers来实现。
- 有序收缩。
那么如果不想要这个集群以及里面的数据了,可以这么操作:
# 如果有yaml文件的话,可以直接通过yaml文件删除
kubectl delete -f xx.yaml
# 删除之后执行kubectl get pod可以看到对应的pod都删除了
kubectl get pod
# 删除之后执行kubectl get statefulset可以看到对应的statefulset都删除了
kubectl get statefulset
# 然后再去删除svc
## 首先执行kubectl get svc查看相应的svc
kubectl get svc
## 删除svc
kubectl delete svc xx(如果想都删了,则执行kubectl delete svc --all)
# 然后删除pvc
## 首先执行kubectl get pvc查看相应的pvc
kubectl get pvc
## 删除pvc
kubectl delete pvc xx(如果想都删了,则执行kubectl delete pvc --all)
执行了上述步骤之后,再执行kubectl get pv可以看到STATUS已经变为Released了:

Released含义:虽然资源已经被释放了,但是没有被对应的api所调用,且仍旧处于待回收状态
那么我们现在需要手动去释放资源,也就是把各个节点上对应的数据删除(其实就是去NFS服务器上把数据删除就行了,NFS上一删,各个节点上挂载的数据也就删掉了)
上图为进入NFS服务器删除数据的操作
但是删除之后会发现PV还是处于Released状态,原因是PV并不会去看文件下有什么具体内容,他只知道在他的描述信息里(yaml文件)依然有连接存在,可以执行命令kubectl get pv xxx -o yaml

可以看到:
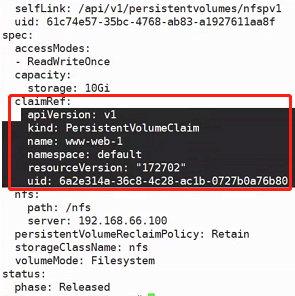
有一个claimRef,我们会发现还是有使用者信息存在,因此PV会觉得自己还是有用的,因此他仍旧处于等待被回收的状态
此时需要手动回收,可以执行kubectl edit nfspv01,进入之后把上图claimRef全部删掉
此时再执行kubectl get pv可以看到:

该PV终于Available(可被绑定使用的状态)了,其余几个PV的手动回收也是这么操作的
总结一下StatefulSet + 无头服务 + PVC + PV + NFS的架构图:
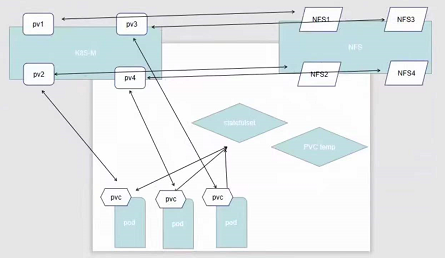
现在看来PVC讲白了其实就是匹配PV的属性选择
StorageClass(SC动态卷供应)
参考:
https://blog.csdn.net/cuichongxin/article/details/121403914(【Kubernetes】k8s的【statefulset】sc的详细说明与创建使用详细代码)
https://cuichongxin.blog.csdn.net/article/details/119734951(超10万字整理完k8s的volume卷之本地卷和网络卷详细说明,代码和理论都超详细,建议跟着做一遍实验【emptyDir、hostPath、nfs共享的网络卷】【1】)
https://cuichongxin.blog.csdn.net/article/details/119808157(超10万字整理完k8s的volume卷之持久性存储pv和pvc原理和创建绑定-超详细说明,代码和理论都超详细,建议跟着做一遍实验【2】)
https://cuichongxin.blog.csdn.net/article/details/119828052(超10万字整理完k8s的volume卷之sc动态卷供应-超详细说明,代码和理论都超详细,建议跟着做一遍实验【3】)
集群调度
调度器 - 调度说明
简介
Scheduler是kubernetes的调度器,主要的任务是把定义的pod分配到集群的节点上。听起来非常简单,但有很多要考虑的问题:
- 公平:如何保证每个节点都能被分配资源
- 资源高效利用:集群所有资源最大化被使用
- 效率:调度的性能要好,能够尽快地对大批量的pod完成调度工作
- 灵活:允许用户根据自己的需求控制调度的逻辑
Sheduler是作为单独的程序运行的,启动之后会一直监听API Server,获取PodSpec.NodeName为空的pod,对每个pod都会创建一个binding,表明该pod应该放到哪个节点上(换句话说,PodSpec.NodeName如果有值,则按照值将pod分配到对应node节点,Scheduler不会参与,除此之外,Scheduler都会参与进来,为pod分配node,建立绑定关系,证明哪些pod应该运行在哪些node上,对应node节点的kubelet就会在监听里得到消息,然后在对应node上建立对应pod)
调度过程
调度分为几个部分:首先是过滤掉不满足条件的节点,这个过程称为predicate;然后对通过的节点按照优先级排序,这个是priority;最后从中选择优先级最高的节点。如果中间任何一步骤有错误,就直接返回错误(意味着该节点被排除)
Predicate有一系列的算法可以使用:
-
PodFitsResources
节点上剩余的资源是否大于pod请求的资源,如果小于直接排除
-
PodFitsHost
如果pod指定了NodeName,检查节点名称是否和NodeName匹配,如果不匹配直接排除
-
PodFitsHostPorts
节点上已经使用的port是否和pod申请的port冲突,如果冲突直接排除
-
PodSelectorMatches
过滤掉和pod指定的label不匹配的节点,如果不匹配直接排除
-
NoDiskConflict
已经mount的volume和pod指定的volume不冲突,除非它们都是只读,如果冲突直接排除
如果在predicate过程中没有合适的节点,pod会一直在pending状态,不断重试调度,直到有节点满足条件。经过这个步骤,如果有多个节点满足条件,就继续priorities过程:按照优先级大小对节点排序
优先级由一系列键值对组成,键是该优先级项的名称,值是它的权重(该项的重要性)。这些优先级选项包括:
-
LeastRequestedPriority
通过计算CPU和Memory的使用率来决定权重,使用率越低权重越高。换句话说,这个优先级指标倾向于资源使用比例更低的节点
-
BalancedResourceAllocation
节点上CPU和Memory使用率越接近,权重越高。这个应该和上面的一起使用,不应该单独使用。
举个例子:一个节点cpu使用率20%:memory使用率60%是1:3,另一个节点cpu使用率50%:memory使用率50%是1:1,虽然前者cpu使用率+memory使用率是80%要小于后者的100%,按照LeastRequestedPriority来说前者资源使用率更低,但是按照BalancedResourceAllocation来说后者资源利用更好,那么最终就会选择后者
-
ImageLocalityPriority
倾向于已经有要使用镜像的节点,镜像总大小值越大,权重越高
通过算法对所有的优先级项目和权重进行计算,得出最终的结果
当然,上述的过滤和优选只是部分常用的,更详细的参考k8s官网,并且,官方已经设计的很好了,不需要我们对这些算法进行修改,那么如果这些算法还不能满足要求,我们可以按照k8s的要求使用相关语言编写自定义调度器,然后在pod中进行选择即可
自定义调度器
除了kubernetes自带的调度器,你也可以编写自己的调度器。通过spec:schedulername参数指定调度器的名字,可以为pod选择某个调度器进行调度。比如下面的pod选择my-scheduler进行调度,而不是默认的default-scheduler:
apiVersion: v1
kind: Pod
metadata:
name: annotation-second-scheduler
labels:
name: multischeduler-example
spec:
schedulername: my-scheduler
containers:
- name: pod-with-second-annotation-container
image: gcr.io/google_containers/pause:2.0
当然自定义调度器的制作涉及go语言,可自行百度
调度器 - 调度亲和性
节点亲和性
pod.spec.nodeAfinity
- preferredDuringSchedulingIgnoredDuringExecution:软策略
- requiredDuringSchedulingIgnoredDuringExecution:硬策略
requiredDuringSchedulingIgnoredDuringExecution
apiVersion: v1
kind: Pod
metadata:
name: affinity
labels:
app: node-affinity-pod
spec:
containers:
- name: with-node-affinity
image: hub.atguigu.com/library/myapp:v1
affinity:
# 节点亲和性
nodeAffinity:
# 硬策略
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: NotIn
values:
- k8s-node02
解释:
-
key是键名,为”
kubernetes.io/hostname"(其实就是node节点的标签)使用命令
kubectl get node --show-labels可以查询节点标签
上图中仔细一找我们就能看到
kubernetes.io/hostname这个标签(每个节点上都有,而且是默认的) -
values是键值,是一个数组,目前只有一个值,为“
k8s-node02” -
operator为“NotIn”,也就是说只要
kubernetes.io/hostname标签不是k8s-node02就能被运行
测试:对于上面的yaml文件,执行kubectl delete pod --all && kubectl create -f xxx.yaml && kubectl get pod -o wide,发现不管执行多少次,pod不会被放置在k8s-node02
同理,如果将operator换成“In”,那么就一定会被放置在k8s-node02
但是如果将operator换成“In”的同时将values中k8s-node02改成k8s-node03(k8s-node03这个节点标签不存在),由于是硬策略,pod不会被创建,会一直处于“Pending”状态:

preferredDuringSchedulingIgnoredDuringExecution
apiVersion: v1
kind: Pod
metadata:
name: affinity
labels:
app: node-affinity-pod
spec:
containers:
- name: with-node-affinity
image: hub.atguigu.com/library/myapp:v1
affinity:
# 节点亲和性
nodeAffinity:
# 软策略
preferredDuringSchedulingIgnoredDuringExecution:
# 权重
- weight: 1
preference:
matchExpressions:
- key: source
operator: In
values:
- qikqiak
解释:
-
weight表示权重
作用在于当有多个软策略的时候,可以选出满足条件且权重最大的那个策略去执行
-
key、operator、values意义跟上面硬策略一样,就不再解释了
测试:这里我们还是把key改成kubernetes.io/hostname跟上面硬策略一样,这样比较好作比较,如果values为“k8s-node03”,由于k8s-node03这个标签并不存在(原因在于k8s-node03这个node节点不存在),那么由于是软策略,pod就会被分配到k8s-node01或k8s-node02这两个node节点上;而如果values为“k8s-node02”,那么pod就会被分配到k8s-node02节点上
合体
apiVersion: v1
kind: Pod
metadata:
name: affinity
labels:
app: node-affinity-pod
spec:
containers:
- name: with-node-affinity
image: hub.atguigu.com/library/myapp:v1
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: NotIn
values:
- k8s-node02
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: source
operator: In
values:
- qikqiak
注意,硬策略软策略一起用的时候,需要先满足硬策略,再去满足软策略
键值运算关系
- In:label的值在某个列表中
- NotIn:label的值不在某个列表中
- Gt:label的值大于某个值
- Lt:label的值小于某个值
- Exists:某个label存在
- DoesNotExist:某个label不存在
注意,如果nodeSelectorTerms下面有多个选项的话,满足任意一个条件就可以了;如果matchExpressions有多个选项的话,则必须同时满足这些条件才能正常调度pod
Pod亲和性
pod.spec.afinity.podAfinity/podAntiAfinity
- preferredDuringSchedulingIgnoredDuringExecution:软策略
- requiredDuringSchedulingIgnoredDuringExecution:硬策略
apiVersion: v1
kind: Pod
metadata:
name: pod-3
labels:
app: pod-3
spec:
containers:
- name: pod-3
image: hub.atguigu.com/library/myapp:v1
affinity:
# 亲和性,如果想让两个pod运行在同一个node上可以使用这种方案
podAffinity:
# 硬策略
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- pod-1
# 以topologyKey的值为主要目标,这里是以kubernetes.io/hostname的值来做判断,因为kubernetes.io/hostname的值是唯一的,如果两者的kubernetes.io/hostname一致则可说明这两个pod处于同一个node节点
topologyKey: kubernetes.io/hostname
# 反亲和性,如果不想让两个pod运行在同一个node上可以使用这种方案
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
# 因为是软策略,因此会有weight权重
- weight: 1
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- pod-2
topologyKey: kubernetes.io/hostname
解释:
- key是标签的键名,为”app“
- values是标签的键值,是一个数组
那么刚才测试节点亲和性的时候我们使用kubectl get node --show-labels来查看节点标签,那么在此要查看pod标签的时候可以使用如下命令:kubectl get pod --show-labels

测试就不做了,因为整体逻辑跟节点亲和性一致
就说一种情况:硬策略下想要与标签为”app=pod-1“的pod在同一个拓扑域,而此时并不存在标签为”app=pod-1“的pod时,pod不会被创建,且状态会一直处于”Pending“。此时执行命令kubectl label pod pod-2 app=pod-1 --overwrite=true将pod-2的标签改为”app=pod-1“,一旦改了,处于”Pending“状态的pod-3立马就会被创建
亲和性/反亲和性调度策略比较如下:
| 调度策略 | 匹配标签 | 操作符 | 拓扑域支持 | 调度目标 |
|---|---|---|---|---|
| nodeAfinity | 主机 | In, NotIn, Exists,DoesNotExist, Gt, Lt | 否 | 指定主机 |
| podAfinity | POD | In, NotIn, Exists,DoesNotExist | 是 | POD与指定POD同一拓扑域 |
| podAnitAfinity | POD | In, NotIn, Exists,DoesNotExist | 是 | POD与指定POD不在同一拓扑域 |
上表为什么要说是拓扑域而不说是节点呢?
原因在于可能存在上图三个节点,前两个节点的disk都是1,第三个节点disk是2,那么此时按照disk划分拓扑域的话(体现在编写亲和性策略的时候key为”disk“),前两个节点就是属于同一个拓扑域,第三个节点就属于另一个拓扑域。由此可见这里的拓扑域跟标签挂钩,而不是指节点本身
同理如果编写亲和性策略时key为”kubernetes.io/hostname“,由于每一个node的kubernetes.io/hostname标签都是唯一的,所以同一个node就是同一个拓扑域
调度器 - 污点
Taint和Toleration
节点亲和性,是pod的一种属性(偏好或硬性要求),它使pod被吸引到一类特定的节点。Taint则相反,它使节点能够排斥一类特定的pod
Taint和toleration相互配合,可以用来避免pod被分配到不合适的节点上。每个节点上都可以应用一个或多个taint,这表示对于那些不能容忍这些taint的pod,是不会被该节点接受的。如果将toleration应用于pod上,则表示这些pod可以(但不要求)被调度到具有匹配taint的节点上
按照白话来说,当一个pod去找node节点的时候,如果node节点存在相应污点,那就要看pod的容忍度,如果pod容忍不了,那就不可能被放置到那个节点,但如果pod可以容忍,那就有可能(注意是有可能不是一定)会被放置到那个节点,当然pod也可能被放置到其他节点
运维知识点:k8s集群中有一个节点需要被维护时,可以给这个节点打一个驱逐污点(NoExecute),待到节点上所有pod都被驱逐之后,再把这个节点从k8s集群中去除,然后就可以对节点进行更新维护了,这样就不会影响业务
污点(Taint)
Ⅰ、污点( Taint )的组成
使用kubectl taint命令可以给某个Node节点设置污点,Node被设置上污点之后就和Pod之间存在了一种相斥的关系,可以让Node拒绝Pod的调度执行,甚至将Node已经存在的Pod驱逐出去
每个污点的组成如下:
key=value:effect
或
key:effect
每个污点有一个key和value作为污点的标签,其中value可以为空,effect描述污点的作用。当前taint effect支持如下三个选项:
- NoSchedule:表示k8s将不会将Pod调度到具有该污点的Node上
- PreferNoSchedule:表示k8s将尽量避免将Pod调度到具有该污点的Node上
- NoExecute:表示k8s将不会将Pod调度到具有该污点的Node上,同时会将Node上已经存在的Pod驱逐出去
Ⅱ、污点的设置、查看和去除
# 设置污点
kubectl taint nodes node1 key1=value1:NoSchedule
# 节点说明中,查找Taints字段
kubectl describe pod pod-name
kubectl describe node node-name
# 去除污点 很简单,就是在创建污点的语句后面加一个“-”即可
kubectl taint nodes node1 key1:NoSchedule-
这里我们看看k8s-master01的污点:
执行kubectl describe node k8s-master01,可以看到:
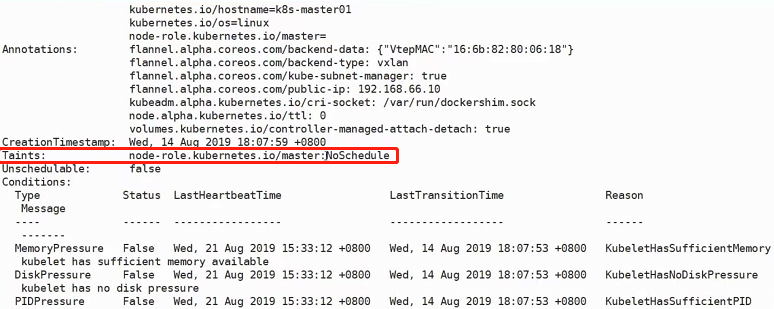
master天生就被打上了上图污点,effect是NoSchedule,这也是k8s会把pod分配到node节点而不是master节点的原因
测试打污点标签:
执行kubectl taint nodes k8s-node01 test=qyf:NoExecute,一旦打了这个标签,所有在k8s-node01节点上的pod都会被驱逐(体现在执行kubectl get pod -o wide后发现所有pod都没了),当然这些pod是自主式pod,没有控制器控制的pod,所以被驱逐后会发现这些pod就真的全没了,如果是Deployment或StatefulSet控制器的pod他就会在除了k8s-node01节点的节点上再次被创建以维持副本数
容忍(Tolerations)
设置了污点的Node将根据taint的efect:NoSchedule、PreferNoSchedule、NoExecute和Pod之间产生互斥的关系,Pod将在一定程度上不会被调度到Node上。但我们可以在Pod上设置容忍( Toleration ),意思是设置了容忍的Pod将可以容忍污点的存在,可以被调度到存在污点的Node上
pod.spec.tolerations
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
tolerationSeconds: 3600
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoExecute"
- key: "key2"
operator: "Exists"
effect: "NoSchedule"
- 其中key, vaule, efect要与Node上设置的taint保持一致
- operator的值为Exists将会忽略value值
- tolerationSeconds用于描述当Pod需要被驱逐时可以在Pod上继续保留运行的时间
测试就不做了,都很好理解且很容易设置
Ⅰ、当不指定key值时,表示容忍所有的污点key:
tolerations:
- operator: "Exists"
Ⅱ、当不指定effect值时,表示容忍所有的污点作用
tolerations:
- key: "key"
operator: "Exists"
Ⅲ、有多个Master存在时,防止资源浪费,可以如下设置
kubectl taint nodes Node-Name node-role.kubernetes.io/master=:PreferNoSchedule
解释:PreferNoSchedule表示尽可能不要在这个节点运行,但万不得已的时候,比方说资源不够用了,那也可以在这个节点上运行
调度器 - 固定节点
指定调度节点
Ⅰ、Pod.spec.nodeName将Pod直接调度到指定的Node节点上,会跳过Scheduler的调度策略,该匹配规则是强制匹配
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: myweb
spec:
replicas: 7
template:
metadata:
labels:
app: myweb
spec:
nodeName: k8s-node01
containers:
- name: myweb
image: hub.atguigu.com/library/myapp:v1
ports:
- containerPort: 80
Ⅱ、Pod.spec.nodeSelector:通过kubernetes的label-selector机制选择节点,由调度器调度策略匹配label,而后调度Pod到目标节点,该匹配规则属于强制约束
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: myweb
spec:
replicas: 2
template:
metadata:
labels:
app: myweb
spec:
nodeSelector:
# type是键名,backEndNode1是键值,当然我们也可以用别的标签键值对,比如视频中老师用的是disk: ssd,表示这个pod要运行到有“disk=ssd”这个标签的节点上
type: backEndNode1
containers:
- name: myweb
image: harbor/tomcat:8.5-jre8
ports:
- containerPort: 80
注意,由于此时并没有存在标签“type=backEndNode1”的节点,因此上述Deployment创建之后会一直处于“Pending”状态,那么执行kubectl label node k8s-node01 type=backEndNode1给k8s-node01打上对应标签,这个时候上述Deployment就会立马被创建在k8s-node01上
当然,除了给k8s-node01打“type=backEndNode1”的标签,还可以给k8s-node02打上述标签,打完标签之后执行kubectl edit deployment myweb将副本数修改为8,然后查看被创建的pod,会发现有一部分pod被创建在k8s-node01上有一部分被创建在k8s-node02上
分发策略之SessionAffinity
基于客户端IP地址进行会话保持/关联的模式,即第1次将某个客户端发起的请求转发到后端的某个Pod上,之后从相同的客户端发起的请求都将被转发到后端相同的Pod上
参考:https://blog.csdn.net/weixin_42715225/article/details/119609253(k8s分发策略之SessionAffinity)
安全
集群安全 - 机制说明
Kubernetes作为一个分布式集群的管理工具,保证集群的安全性是其一个重要的任务。API Server是集群内部各个组件通信的中介,也是外部控制的入口。所以Kubernetes的安全机制基本就是围绕保护API Server来设计的。Kubernetes使用了认证(Authentication)、鉴权(Authorization)、准入控制(AdmissionControl)三步来保证API Server的安全
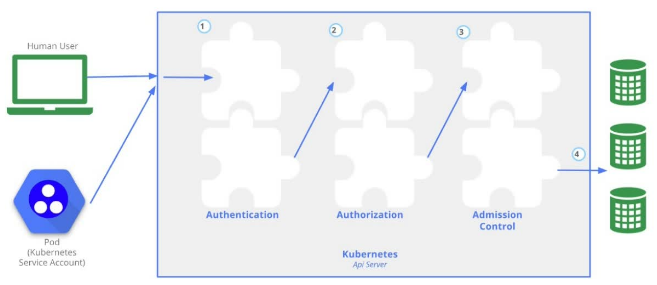
集群安全 - 认证
-
HTTP Token认证:通过一个Token来识别合法用户
- HTTP Token的认证是用一个很长的特殊编码方式的并且难以被模仿的字符串- Token来表达客户的一种方式。Token是一个很长的很复杂的字符串,每一个Token对应一个用户名存储在API Server能访问的文件中。当客户端发起API调用请求时,需要在HTTP Header里放入Token
-
HTTP Base认证:通过用户名+密码的方式认证
- 用户名+:+密码用BASE64算法进行编码后的字符串放在HTTP Request中的HeatherAuthorization域里发送给服务端,服务端收到后进行编码,获取用户名及密码
-
最严格的HTTPS证书认证:基于CA根证书签名的客户端身份认证方式
原先在讲HTTPS的时候我们说他是单向认证,在k8s中他的实现方式是双向认证
企业中一般选择第三种,因为前两种的安全性不高,并且k8s采用http协议进行CS结构的开发,因此https就是最好的加密方案
Ⅰ、HTTPS证书认证:
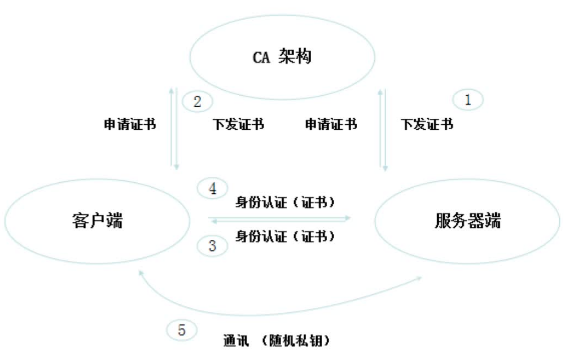
Ⅱ、需要认证的节点
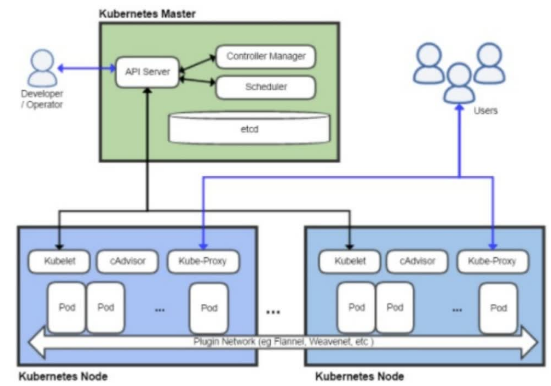
k8s集群中Controller Manager、Scheduler、etcd、kubelet、kube-proxy、部分pod(比如coredns、dashboard)都会访问到api server来获取数据,因此这些组件都需要与api server实现https双向认证
两种类型
- Kubenetes组件对API Server的访问:kubectl、Controller Manager、Scheduler、kubelet、
kube-proxy - Kubernetes管理的Pod对容器的访问:Pod(coredns、dashborad也是以Pod形式运行)
安全性说明
- Controller Manager、Scheduler与API Server在同一台机器,所以直接使用API Server的非安全端口访问(没有双向https加密,当然也可以在master节点关闭非安全端口访问,那么这样的话不得已只能访问https加密端口,但一般情况下同一台机器下访问,加密访问是没有必要的),
--insecure-bind-address=127.0.0.1 - kubectl、kubelet、
kube-proxy访问API Server就都需要证书进行HTTPS双向认证(因为他们都是远程的访问)
证书颁发
- 手动签发:通过k8s集群的跟ca进行签发HTTPS证书
- 自动签发:kubelet首次访问API Server时,使用token做认证,通过后,Controller Manager会为kubelet生成一个证书,以后的访问都是用证书做认证了
当然如果用kubeadm安装集群,是不会涉及到手动签发的,都是自动完成的
Ⅲ、kubeconfig
kubeconfig文件包含集群参数(CA证书、API Server地址),客户端参数(上面生成的证书和私钥),集群context信息(集群名称、用户名)。Kubenetes组件通过启动时指定不同的kubeconfig文件可以切换到不同的集群
kubeconfig在master节点的.kube/文件夹下




Ⅳ、ServiceAccount
Pod中的容器访问API Server。因为Pod的创建、销毁是动态的,所以要为它手动生成证书就不可行了。Kubenetes使用了Service Account解决Pod访问API Server的认证问题
SA也是一组文件,包含了私钥、命名空间等信息,他是pod认证到api server的标准
Ⅴ、Secret与SA的关系
Kubernetes设计了一种资源对象叫做Secret,分为两类,一种是用于ServiceAccount的service-account-token,另一种是用于保存用户自定义保密信息的Opaque。ServiceAccount中用到包含三个部分:Token、ca.crt、namespace
- token是使用API Server私钥签名的JWT。用于访问API Server时,Server端认证
ca.crt,根证书。用于Client端验证API Server发送的证书- namespace,标识这个
service-account-token的作用域名空间
Json Web Token (JWT),是为了在网络应用环境间传递声明而执行的一种基于JSON的开放标准。该token被设计 为紧凑且安全的,特别适用于分布式站点的单点登录(SSO)场景。JWT的声明一般被用来在身份提供者和服务提供者间传递被认证的用户身份信息,以便于从资源服务器获取资源,也可以增加一些额外的其他业务逻辑所必须的声明信息,该token也可直接被用于认证,也可被加密
kubectl get secret --all-namespaces
kubectl describe secret default-token-5gm9r --namespace=kube-system
默认情况下,每个namespace都会有一个ServiceAccount,如果Pod在创建时没有指定ServiceAccount,就会使用Pod所属的namespace的ServiceAccount
默认挂载目录:/run/secrets/kubernetes.io/serviceaccount/
示例:
执行kubectl get pod -n kube-system,随便选择一个pod,比方说这里我们选kube-proxy-fb85x
执行kubectl exec kube-proxy-fb85x -n kube-system -it -- /bin/sh
进入之后执行cd /run/secrets/kubernetes.io/serviceaccount/可以看到三个文件:ca.crt、namespace、token
总结
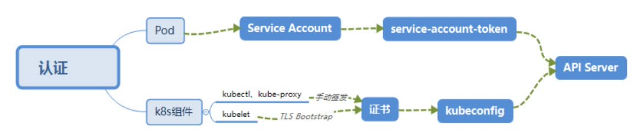
集群安全 - 鉴权
Authorization
上面认证过程,只是确认通信的双方都确认了对方是可信的,可以相互通信。而鉴权是确定请求方有哪些资源的权限。API Server目前支持以下几种授权策略(通过API Server的启动参数“--authorization-mode”设置)
- AlwaysDeny:表示拒绝所有的请求,一般用于测试
- AlwaysAllow:允许接收所有请求,如果集群不需要授权流程,则可以采用该策略
- ABAC(
Attribute-Based Access Control)(已被淘汰,并且现在在修改完成之后并不能马上生效,需要重启api server才行,很费劲):基于属性的访问控制,表示使用用户配置的授权规则对用户请求进行匹配和控制 - Webbook:通过调用外部REST服务对用户进行授权
- RBAC(
Role-Based Access Control)★:基于角色的访问控制,现行默认规则
RBAC授权模式
RBAC(Role-Based Access Control)基于角色的访问控制,在Kubernetes 1.5中引入,现行版本成为默认标准。相对其它访问控制方式,拥有以下优势:
- 对集群中的资源和非资源均拥有完整的覆盖
- 整个RBAC完全由几个API对象完成,同其它API对象一样,可以用kubectl或API进行操作
- 可以在运行时进行调整,无需重启API Server
Ⅰ、RBAC的API资源对象说明
RBAC引入了4个新的顶级资源对象:Role、ClusterRole、RoleBinding、ClusterRoleBinding,4种对象类型均可以通过kubectl与API操作
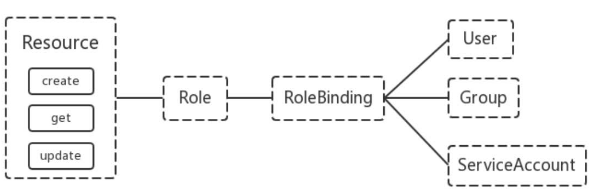
举例:
Role是名称空间级别的
假设有一个用户zhangsan在default命名空间下需要拥有读取pod的权限,那么我会在default命名空间下创建一个具有读取pod权限的Role(上图的readPod),然后通过RoleBinding将该Role与zhangsan绑定;此时又来了一个用户lisi,该用户需要在test命名空间下拥有读取pod的权限,那么我就还需要在test命名空间下创建一个readPod,再执行RoleBinding赋予权限;那如果有100个这样的需求呢?如果按照Role来操作则需要创建100个Role,非常麻烦,那么就有了ClusterRole
ClusterRole能拥有集群下所有名称空间的相关操作权限,举个例子,还是上图的readPod(读取pod权限),如果他是ClusterRole,意味着他具有读取集群下所有名称空间的pod信息的权限
而且注意我们使用的是RoleBinding不是ClusterRoleBinding,在RoleBinding的时候需要指定命名空间,此时给wangwu指定一个命名空间,给zhaoliu指定另一个命名空间,也能达到跟上面单独命名空间创建各自的Role然后RoleBinding一样的效果,相当于资源下放了,非常方便
那如果使用ClusterRoleBinding呢?
那就意味着wangyang这个角色能够读取k8s集群中所有pod的信息(针对readPod来说),反过来讲ClusterRoleBinding能使得角色拥有整个集群下所有命名空间的相关操作权限
根据上面的案例引申出来一个注意点:并不是只有Role可以使用RoleBinding,ClusterRole也能使用RoleBinding
需要注意的是Kubenetes并不会提供用户管理,那么User、Group、ServiceAccount指定的用户又是从哪里来的呢?Kubenetes组件(kubectl、kube-proxy)或是其他自定义的用户在向CA申请证书时,需要提供一个证书请求文件
{
// 这个CN就是指用户
"CN": "admin",
"hosts": [],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "HangZhou",
"L": "XS",
// 这个O就是指组
"O": "system:masters",
"OU": "System"
}
]
}
API Server会把客户端证书的CN字段作为User,把names.O字段作为Group
kubelet使用TLS Bootstaping认证时,API Server可以使用Bootstrap Tokens或者Token authentication file验证=token,无论哪一种,Kubenetes都会为token绑定一个默认的User和Group
Pod使用ServiceAccount认证时,service-account-token中的JWT会保存User信息有了用户信息,再创建一对角色/角色绑定(集群角色/集群角色绑定)资源对象,就可以完成权限绑定了
Role and ClusterRole
在RBAC API中,Role表示一组规则权限,权限只会增加(累加权限),不存在一个资源一开始就有很多权限而通过RBAC对其进行减少的操作;Role可以定义在一个namespace中,如果想要跨namespace则可以创建ClusterRole
kind: Role
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
namespace: default
name: pod-reader
rules:
# apiGroups里面可以写类似这种:rbac.authorization.k8s.io/v1beta1,其实就是apiVersion写的东西
# 这里[""]代表的是空,含义是pod-reader的时候他是要赋予哪个api的组和版本,这里如果不写的话代表的就是core核心组
- apiGroups: [""] # "" indicates the core API group
# 对象是pod类型
resources: ["pods"]
# 操作动作,有“获取”、“监听”、“列出”
# 也就是说如果把pod-reader赋予某个用户的话,这个用户就能在default命名空间下获取pod、监听pod、列出pod
verbs: ["get","watch","list"]
ClusterRole具有与Role相同的权限角色控制能力,不同的是ClusterRole是集群级别的,ClusterRole可以用于:
-
集群级别的资源控制(例如node访问权限)
-
非资源型endpoints(例如
/healthz访问) -
所有命名空间资源控制(例如pods)
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
# "namespace" omitted since ClusterRoles are not namespaced
name: secret-reader
rules:
# apiGroups里面可以写类似这种:rbac.authorization.k8s.io/v1beta1,其实就是apiVersion写的东西
- apiGroups: [""]
# 对象是secret类型
resources: ["secrets"]
# 操作动作,有“获取”、“监听”、“列出”
# 也就是说如果把secret-reader使用ClusterRoleBinding赋予某个用户的话,这个用户就能在集群所有名称空间下进行secret的获取、监听、列出;如果使用RoleBinding赋予某个用户的话,这个用户就能在集群对应名称空间下进行secret的获取、监听、列出
verbs: ["get","watch","list"]
RoleBinding and ClusterRoleBinding
RoloBinding可以将角色中定义的权限授予用户或用户组,RoleBinding包含一组权限列表(subjects),权限列表中包含有不同形式的待授予权限资源类型(users, groups, or service accounts);RoloBinding同样包含对被Bind的Role引用;RoleBinding适用于某个命名空间内授权,而ClusterRoleBinding适用于集群范围内的授权
将default命名空间的pod-reader Role授予jane用户,此后jane用户在default命名空间中将具有pod-reader的权限
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: read-pods
namespace: default
subjects:
- kind: User
name: jane
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role
name: pod-reader
apiGroup: rbac.authorization.k8s.io
RoleBinding同样可以引用ClusterRole来对当前namespace内用户、用户组或ServiceAccount进行授权,这种操作允许集群管理员在整个集群内定义一些通用的ClusterRole,然后在不同的namespace中使用RoleBinding来引用
例如,以下RoleBinding引用了一个ClusterRole,这个ClusterRole具有整个集群内对secrets的访问权限;但是其授权用户dave只能访问development空间中的secrets(因为RoleBinding定义在development命名空间)
# This role binding allows "dave" to read secrets in the "development" namespace.
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: read-secrets
namespace: development # This only grants permissions within the "development" namespace.
subjects:
- kind: User
name: dave
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: secret-reader
apiGroup: rbac.authorization.k8s.io
使用ClusterRoleBinding可以对整个集群中的所有命名空间资源权限进行授权;以下ClusterRoleBinding样例展示了授权manager组内所有用户在全部命名空间中对secrets进行访问
# This cluster role binding allows anyone in the "manager" group to read secrets in any namespace.
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: read-secrets-global
subjects:
- kind: Group
name: manager
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: secret-reader
apiGroup: rbac.authorization.k8s.io
Resources
Kubernetes集群内一些资源一般以其名称字符串来表示,这些字符串一般会在API的URL地址中出现;同时某些资源也会包含子资源,例如logs资源就属于pods的子资源,API中URL样例如下
GET /api/v1/namespaces/{namespace}/pods/{name}/log
上述URL的意义是访问某个命名空间下的某个pod的log日志信息
那么如果授权到了/api/v1/namespaces/{namespace}/pods这个字段,意味着pods的所有下属都有权限去访问;而如果授权到了/api/v1/namespaces/{namespace}/pods/{name}/log这个字段,意味着只有访问对应pod的log日志信息的权限而没有其余的权限了
如果要在RBAC授权模型中控制这些子资源的访问权限,可以通过/分隔符来实现,以下是一个定义pods资资源logs访问权限的Role定义样例
kind: Role
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
namespace: default
name: pod-and-pod-logs-reader
rules:
- apiGroups: [""]
# 如果resources只留下["pods/log"],意味着只能看pod的日志信息
resources: ["pods","pods/log"]
# 操作动作 获取、列出
verbs: ["get","list"]
To Subjects
RoleBinding和ClusterRoleBinding可以将Role绑定到Subjects;Subjects可以是groups、users或者service accounts
Subjects中Users使用字符串表示,它可以是一个普通的名字字符串,如“alice”;也可以是email格式的邮箱地址,如“wangyanglinux@163.com”;甚至是一组字符串形式的数字ID。但是Users的前缀 system: 是系统保留的,集群管理员应该确保普通用户不会使用这个前缀格式
Groups书写格式与Users相同,都为一个字符串,并且没有特定的格式要求;同样 system: 前缀为系统保留
实践:创建一个用户只能管理dev空间
k8s没有自己的用户的管理,也就是说用户的创建的过程需要在linux中自行完成
创建用户并设置密码:
useradd devuser
passwd devuser
然后以该用户的身份登录linux系统,此时使用kubectl get pod发现是访问不到k8s的,因为没有证书信息,所以我们还需要为devuser创建证书请求:
首先到master节点的对应目录
cd /usr/local/install-k8s
mkdir cert
cd cert/
mkdir devuser
cd devuser/
证书后续可能会用到这个文件名(当然文件名可以随意命名,只需要在后续用到的时候能对应上就行了):
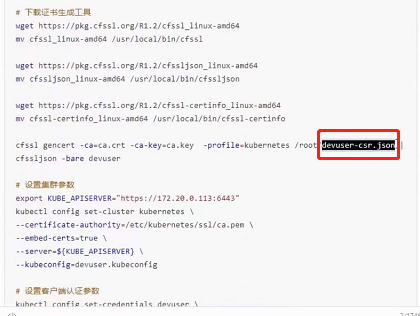
那么就创建该证书文件:
首先执行命令vim devuser-csr.json,然后输入下面的内容:
{
// 用户名
"CN": "devuser",
// 表示可以去使用的主机,如果不写则表示所有;如果写了,比方说写了:["192.168.66.10"],则表示只有该ip的主机可以使用
"hosts": [],
"key": {
// rsa算法
"algo": "rsa",
// 2048位
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
// 组别
"O": "k8s",
"OU": "System"
}
]
}
然后保存退出即可
如果我们想使用工具去生成证书,则应该这么操作:
# 下载证书生成工具
wget https://pkg.cfssl.org/R1.2/cfssl_linux-amd64
mv cfssl_linux-amd64 /usr/local/bin/cfssl
wget https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64
mv cfssljson_linux-amd64 /usr/local/bin/cfssljson
wget https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64
mv cfssl-certinfo_linux-amd64 /usr/local/bin/cfssl-certinfo
chmod a+x /usr/local/bin/*
生成证书:
# 进入/etc/kubernetes/pki/目录下创建证书文件,因为这个目录下存放的都是k8s的密钥信息,所以我们可以把证书创建在这里
cd /etc/kubernetes/pki/
# 解释:-ca表示ca的证书、-ca-key表示ca的私钥、/usr/local/install-k8s/cert/devuser/devuser-csr.json表示请求的文件(其实就是上面我们手动生成的那个文件)、devuser表示输出到devuser(证书的文件名)
cfssl gencert -ca=ca.crt -ca-key=ca.key -profile=kubernetes /usr/local/install-k8s/cert/devuser/devuser-csr.json | cfssljson -bare devuser
需要注意的是上面创建证书的时候最好创建在/etc/kubernetes/pki/文件夹下,因为这个文件夹下存放的都是k8s的密钥信息

执行了上面cfssl gencert -ca=ca.crt -ca-key=ca.key -profile=kubernetes /usr/local/install-k8s/cert/devuser/devuser-csr.json | cfssljson -bare devuser这个命令之后我们会发现目录下多了几个文件:
这样我们的证书请求和我们的证书私钥都已经出来了,现在我们就可以为当前的集群设置一下信息了
还是在master节点
# 回到devuser用户文件目录下(原因是设置的时候会有一些缓存文件生成)
cd /usr/local/install-k8s/cert/devuser/
# 设置集群参数
export KUBE_APISERVER="https://192.168.66.10:6443"
kubectl config set-cluster kubernetes \
--certificate-authority=/etc/kubernetes/pki/ca.crt \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=devuser.kubeconfig
# 设置客户端认证参数,“--embed-certs=true”表示开启认证方式,“devuser.kubeconfig”这个配置文件其实在上一步设置集群参数的时候就会被生成到当前目录下,那么这里的“--kubeconfig=devuser.kubeconfig”的意思就是使用该配置文件,并且后续生成的一些信息也会被写入到该配置文件
kubectl config set-credentials devuser \
--client-certificate=/etc/kubernetes/pki/devuser.pem \
--client-key=/etc/kubernetes/pki/devuser-key.pem \
--embed-certs=true \
--kubeconfig=devuser.kubeconfig
# 设置上下文参数,意义就是帮我们的角色绑定到某一个命名空间,这里是dev命名空间,当然在这一步之前需要确保k8s有dev这个命名空间,如果没有的话,则执行kubectl create namespace dev先创建一个dev命名空间
kubectl config set-context kubernetes \
--cluster=kubernetes \
--user=devuser \
--namespace=dev \
--kubeconfig=devuser.kubeconfig
# 创建rolebinding,那么在k8s集群中已经存在一个clusterrole叫做“admin”,这个角色可以为所欲为,如果将admin这个clusterrole进行rolebinding,也就是下放层级,绑定至dev命名空间,表明devuser这个用户可以在dev下为所欲为
kubectl create rolebinding devuser-admin-binding --clusterrole=admin --user=devuser --namespace=dev
# 然后在devuser用户家目录下创建.kube文件夹,并执行命令将devuser.kubeconfig转移至.kube文件夹中,并转移权限
cp devuser.kubeconfig /home/devuser/.kube/
chown devuser:devuser /home/devuser/.kube/devuser.kubeconfig
# 然后查看master中./kube下的证书文件名字叫config,那么我们也将devuser.kubeconfig改名为config
mv devuser.kubeconfig config
# 设置默认上下文,也就是设置上下文信息,即所谓的切换。这个切换上下文的概念其实就是让kubectl去读取到配置信息,也就是kubeconfig信息
# 那么首先需要以devuser的身份登录linux服务器,进入/home/devuser/.kube/文件夹下,然后执行下述代码
kubectl config use-context kubernetes --kubeconfig=config
上面每设置一步,当前目录下生成的devuser.kubeconfig文件(在第一步设置的时候就会创建)中就会多对应的一些内容,到最后文件的内容就会变成类似于master节点中./kube/config文件,具体请自行查看
设置上下文参数之前需要确保k8s有dev这个命名空间,如果没有的话,则执行kubectl create namespace dev先创建一个dev命名空间
做完了上述步骤之后,我们测试一下devuser用户创建的pod到底在哪个命名空间下:
执行kubectl run nginx --image=wangyanglinux/myapp:v2,然后执行kubectl get pod会发现devuser下能显示这个pod,然后我们回到master节点,执行kubectl get pod --all-namespace -o wide | grep nginx(--all-namespace表示查询所有命名空间)可以发现刚才创建的pod在dev命名空间下
由此可见使用devuser创建的pod不需要加命名空间默认就是在dev命名空间下,而且当以devuser身份执行kubectl get pod -n default访问default命名空间下的pod的时候会报错,原因是没有权限
至此我们就做到了权限分配
集群安全 - 准入控制
上面讲了认证与鉴权,事实上是这个顺序:HTTPS双向认证 -> RBAC鉴权 -> 准入控制(如果有的话),白话讲就是认证之后需要鉴权,鉴权过后如果还有准入控制则还需要准入控制
如果要做准入控制,那么如果允许访问集群中的某些资源,则在准入控制中去书写,那么到时候如果准入控制中有这种资源类型,才能去访问到某些资源
当然,不是所有的都需要做准入控制,但有大部分是需要做的
准入控制是API Server的插件集合,通过添加不同的插件,实现额外的准入控制规则。甚至于API Server的一些主要的功能都需要通过Admission Controllers实现,比如ServiceAccount官方文档上有一份针对不同版本的准入控制器推荐列表,其中最新的1.14的推荐列表是(不同版本不一样,需要自行查询,当然推荐列表中的东西也并不需要全用,也可以适当删除一点):
NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultStorageClass,DefaultTolerationSeconds,Mutat
ingAdmissionWebhook,ValidatingAdmissionWebhook,ResourceQuota
上面几个是1.14版本建议开启的准入控制列表
列举几个插件的功能:
- NamespaceLifecycle:防止在不存在的namespace上创建对象,防止删除系统预置namespace,删除namespace时,连带删除它的所有资源对象。
- LimitRanger:确保请求的资源不会超过资源所在Namespace的LimitRange的限制。(意味着如果没开这个功能的话,那资源就随便超,所以还是建议把准入控制放到一个默认的规则中,不要自行修改,因为很多特殊的功能都需要准入控制去实现)
- ServiceAccount:实现了自动化添加ServiceAccount。
- ResourceQuota:确保请求的资源不会超过资源的ResourceQuota限制。
可以理解为,准入控制能帮助我们实现一些额外的功能,甚至某些功能的开启都需要到准入控制中去添加。
Helm及其他功能性组件
部署Helm
什么是Helm
在没使用helm之前,向kubernetes部署应用,我们要依次部署deployment、svc等,步骤较繁琐。况且随着很多项目微服务化,复杂的应用在容器中部署以及管理显得较为复杂,helm通过打包的方式,支持发布的版本管理和控制,很大程度上简化了Kubernetes应用的部署和管理
Helm本质就是让K8s的应用管理(Deployment,Service等)可配置,能动态生成。通过动态生成K8s资源清单文件(deployment.yaml,service.yaml)(也就是说对于Helm来讲yaml文件不是不变的,不像以前编写好yaml文件保存退出之后文件就不会变动了,Helm可以使用类似于环境变量的东西去修改yaml文件信息,使yaml更能适应到环境之中)。然后调用Kubectl自动执行K8s资源部署
Helm是官方提供的类似于YUM的包管理器,是部署环境的流程封装。Helm有两个重要的概念:chart和release
- chart是创建一个应用的信息集合(包括Deployment、SVC、Ingress、存储等等是如何创建的,都需要声明出来),包括各种Kubernetes对象的配置模板、参数定义(根据参数定义可以达到与当前环境相匹配的结果)、依赖关系、文档说明等。chart是应用部署的自包含逻辑单元。可以将chart想象成apt、yum中的软件安装包
- release是chart的运行实例,代表了一个正在运行的应用。当chart被安装到Kubernetes集群,就生成一个release。chart能够多次安装到同一个集群,每次安装都是一个release
Helm包含两个组件:Helm客户端和Tiller服务器,如下图所示
Helm客户端负责chart和release的创建和管理以及和Tiller(Helm Client对应客户端,Tiller对应的就是服务端)的交互。Tiller服务器运行在Kubernetes集群中,它会处理Helm客户端的请求,与Kubernetes API Server交互
Helm部署
越来越多的公司和团队开始使用Helm这个Kubernetes的包管理器,我们也将使用Helm安装Kubernetes的常用组件。Helm由客户端命helm令行工具和服务端tiller组成,Helm的安装十分简单。下载helm命令行工具到master节点node1的/usr/local/bin下,这里下载的2.13. 1版本:
ntpdate ntp1.aliyun.com
wget https://storage.googleapis.com/kubernetes-helm/helm-v2.13.1-linux-amd64.tar.gz
tar -zxvf helm-v2.13.1-linux-amd64.tar.gz
cd linux-amd64/
cp helm /usr/local/bin/
chmod a+x /usr/local/bin/helm
为了安装服务端tiller,还需要在这台机器上配置好kubectl工具和kubeconfig文件,确保kubectl工具可以在这台机器上访问apiserver且正常使用。这里的node1节点以及配置好了kubectl
因为Kubernetes APIServer开启了RBAC访问控制,所以需要创建tiller使用的service account: tiller并分配合适的角色给它。详细内容可以查看helm文档中的Role-based Access Control。这里简单起见直接分配cluster- admin这个集群内置的ClusterRole给它。创建rbac-config.yaml文件:
apiVersion: v1
kind: ServiceAccount
metadata:
name: tiller
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: tiller
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
# 集群管理员角色
name: cluster-admin
subjects:
- kind: ServiceAccount
name: tiller
namespace: kube-system
kubectl create -f rbac-config.yaml
serviceaccount/tiller created
clusterrolebinding.rbac.authorization.k8s.io/tiller created
helm init --service-account tiller --skip-refresh
创建完之后使用helm version就可以看到helm信息
tiller默认被部署在k8s集群中的kube-system这个namespace下
kubectl get pod -n kube-system -l app=helm
NAME READY STATUS RESTARTS AGE
tiller-deploy-c4fd4cd68-dwkhv 1/1 Running 0 83s
helm version
Client: &version.Version{SemVer:"v2.13.1", GitCommit:"618447cbf203d147601b4b9bd7f8c37a5d39fbb4",GitTreeState:"clean"}
Server: &version.Version{SemVer:"v2.13.1",GitCommit:"618447cbf203d147601b4b9bd7f8c37a5d39fbb4",GitTreeState:"clean"}
去Helm官网找代码下载相应组件(类比maven)
之前说了chart是安装应用的信息集合(类比docker的image镜像),那么直接去官网找到chart

能搜到一堆chart:
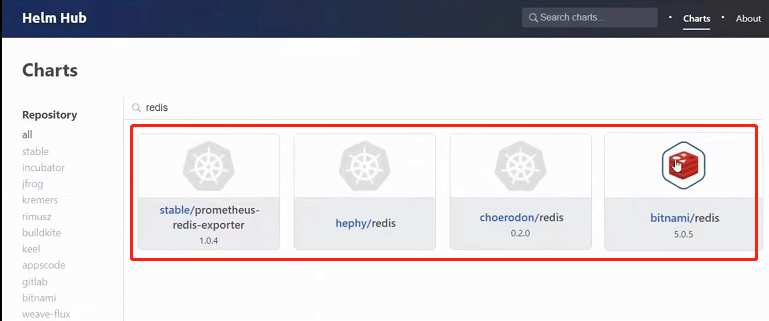
进入之后到Install这边,提示我们先配置repo仓库(类比yum源),之后再install该chart(没错,安装一个redis集群就是这么简单):
install的命令还可以在下边Installing the Chart中找到:
当然底下还有一些其他的说明,比方说字段的更改等:
Helm自定义模板
# 创建文件夹
$ mkdir ./hello-world
$ cd ./hello-world
# 创建自描述文件 Chart.yaml,这个文件必须有 name 和 version 定义
$ cat <<'EOF' > ./Chart.yaml
name: hello-world
version: 1.0.0
EOF
# 创建模板文件,用于生成Kubernetes资源清单(manifests)
$ mkdir ./templates
$ cat <<'EOF' > ./templates/deployment.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: hello-world
spec:
replicas: 1
template:
metadata:
labels:
app: hello-world
spec:
containers:
- name: hello-world
image: hub.atguigu.com/library/myapp:v1
ports:
- containerPort: 80
protocol: TCP
EOF
$ cat <<'EOF' > ./templates/service.yaml
apiVersion: v1
kind: Service
metadata:
name: hello-world
spec:
type: NodePort
ports:
- port: 80
targetPort: 80
protocol: TCP
selector:
app: hello-world
EOF
# 使用命令 helm install RELATIVE_PATH_TO_CHART 创建一次Release
# --name可以指定RELEASE_NAME,--namespace可以指定命名空间,其他更多参数参考官网
$ helm install .
# helm帮助文档
$ helm help
# 列出已经部署的Release
$ helm ls
# 更新一个release,“.”的意思是在当前目录下更新,那么什么时候要用到这个命令呢?templates下的yaml文件发生变动之后
$ helm upgrade RELEASE_NAME .
# fetch the release history
$ helm history RELEASE_NAME
# 查询一个特定的Release的状态,包括暴露的端口等
$ helm status RELEASE_NAME
# 移除所有与这个Release相关的Kubernetes资源
$ helm delete cautious-shrimp
# helm rollback RELEASE_NAME REVISION_NUMBER
$ helm rollback cautious-shrimp 1
# 使用 helm delete --purge RELEASE_NAME 移除所有与指定Release相关的Kubernetes资源和所有这个Release的记录
$ helm delete --purge cautious-shrimp
$ helm ls --deleted
注意helm delete这个命令,实际测试中,使用helm delete my_release01删除my_release01之后,在使用helm install --name my_release01 .会报错,说是名为my_release01的release已经存在,此时执行helm list --deleted会发现my_release01还是存在一些残留信息:

原因是他考虑到了后续我们可能会想要还原release(类比回收站),如果需要还原release,可以执行helm rollback RELEASE_NAME REVISION_NUMBER
如果想要彻底删除,需要执行helm delete --purge,彻底删除之后将无法还原release
自定义变量,将重要信息配置出去,方便后续更改:
# 配置体现在配置文件 values.yaml
$ cat <<'EOF' > ./values.yaml
image:
repository: gcr.io/google-samples/node-hello
tag: '1.0'
EOF
# 这个文件中定义的值,在模板文件中可以通过 .VAlues对象访问到
$ cat <<'EOF' > ./templates/deployment.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: hello-world
spec:
replicas: 1
template:
metadata:
labels:
app: hello-world
spec:
containers:
- name: hello-world
image: {{ .Values.image.repository }}:{{ .Values.image.tag }}
ports:
- containerPort: 8080
protocol: TCP
EOF
# 在 values.yaml 中的值可以被部署 release 时用到的参数 --values YAML_FILE_PATH 或 --set key1=value1, key2=value2 覆盖掉
$ helm install --set image.tag='latest' .
# 升级版本
$ helm upgrade -f values.yaml test .
当然,除了自定义变量,还有很多系统预定义变量,即helm的chart中模板里面的预定义变量,如果需要进行修改,可以查阅helm官方文档
Debug
# 使用模板动态生成K8s资源清单,非常需要能提前预览生成的结果。
# 使用--dry-run --debug 选项来打印出生成的清单文件内容,而不执行部署
$ helm install . --dry-run --debug --set image.tag=latest
使用Helm部署dashboard
我们先来看看helm官网的“stable/kubernetes-dashboard”文件结构是什么样的
$ helm help # 查阅helm帮助手册,看到fetch命令可以帮助下载网络上的chart
$ helm repo update # 仓库更新,类比yum -y update
执行helm repo list可以看到谷歌的仓库和本地的仓库这两个仓库:

$ helm fetch stable/kubernetes-dashboard # 下载“stable/kubernetes-dashboard”
下载后使用tar -zxvf命令解压,进入解压后的文件:

发现有chart、templates、values.yaml,跟helm要求的格式一模一样
看过了官网给我们封装的dashboard的文件结构,现在我们来真正安装dashboard
kubernetes-dashboard.yaml(其实就是上面所说的values.yaml):
image:
repository: k8s.gcr.io/kubernetes-dashboard-amd64
tag: v1.10.1
ingress:
enabled: true
hosts:
- k8s.frognew.com
annotations:
nginx.ingress.kubernetes.io/ssl-redirect: "true"
nginx.ingress.kubernetes.io/backend-protocol: "HTTPS"
tls:
- secretName: frognew-com-tls-secret
hosts:
- k8s.frognew.com
rbac:
clusterAdminRole: true
# -n 是 --name 的缩写,用于指定名称
helm install stable/kubernetes-dashboard \
-n kubernetes-dashboard \
--namespace kube-system \
-f kubernetes-dashboard.yaml
这里会需要下载镜像,速度可能会比较慢,解决方式有:1、如果本地已经有镜像了,可以尝试传输到远程k8s服务器并scp到其余节点,然后docker load -i加载镜像;2、使用harbor私有镜像仓库
完毕之后使用kubectl get svc -n kube-system可以看到dashboard的svc,使用kubectl edit svc kubernetes-dashboard -n kube-system将ClusterIP修改为NodePort,然后外部就能访问了,但谷歌浏览器可能会警告:

这种情况下的解决方案:
-
给谷歌浏览器导入我们k8s集群的CA证书
ca.crt在master节点的/etc/kubernetes/pki/ca.crt -
下载别的浏览器,比如火狐
进入dashboard之后有两中访问方式:
一种是指定config文件(在master节点的家目录下的.kube/config);
一种是使用token令牌:
# kubernetes-dashboard-token-pkm2s就是token
$ kubectl -n kube-system get secret | grep kubernetes-dashboard-token
kubernetes-dashboard-token-pkm2s kubernetes.io/service-account-token 3 3m7s
$ kubectl describe secret kubernetes-dashboard-token-pkm2s -n kube-system
Name: kubernetes-dashboard-token-pkm2s
Namespace: kube-system
Labels: <none>
Annotations:
kubernetes.io/service-account.name: kubernetes-dashboard
kubernetes.io/service-account.uid: 2f0781dd-156a-11e9-b0f0-080027bb7c43
Type: kubernetes.io/service-account-token
Data ====
ca.crt: 1025bytes
namespace: 11bytes
token:
...
把上述token复制一下,去客户端输入并登录:
之后就进来了
使用dashboard进行创建:
创建方式有多种,可以手动编写yaml来创建,可以通过yaml文件创建,也可以通过像上图这样来创建,具体的自行探索
部署成功:
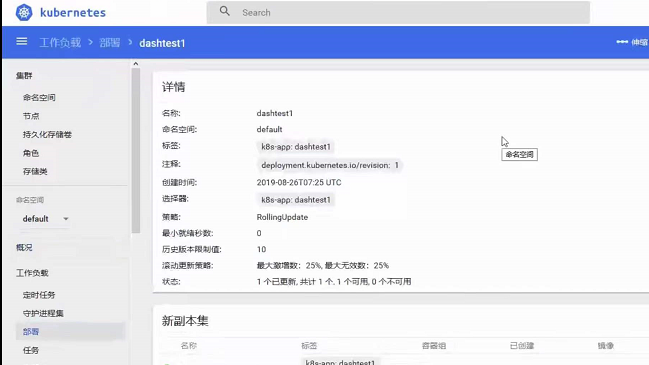
使用Helm部署metrics-server
metrics-server和下一小节的prometheus只能选其一,推荐直接上prometheus,因为prometheus已经集成了metrics-server
从Heapster的github <https://github.com/kubernetes/heapster >中可以看到已经,heapster已经DEPRECATED。这里是heapster的deprecation timeline。可以看出heapster从Kubernetes 1.12开始将从Kubernetes各种安装脚本中移除。Kubernetes推荐使用metrics-server。我们这里也使用helm来部署metrics-server。
metrics-server.yaml:
args:
- --logtostderr
- --kubelet-insecure-tls
- --kubelet-preferred-address-types=InternalIP
helm install stable/metrics-server \
-n metrics-server \
--namespace kube-system \
-f metrics-server.yaml
使用下面的命令可以获取到关于集群节点基本的指标信息:
$ kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
node1 650m 32% 1276Mi 73%
node2 73m 3% 527Mi 30%
$ kubectl top pod --all-namespaces
NAMESPACE NAME CPU(cores) MEMORY(bytes)
ingress-nginx nginx-ingress-controller-6f5687c58d-jdxzk 3m 142Mi
ingress-nginxnginx-ingress-controller-6f5687c58d-lxj5q 5m 146Mi
ingress-nginxnginx-ingress-default-backend-6dc6c46dcc-lf882 1m 4Mi
kube-systemcoredns-86c58d9df4-k5jkh 2m 15Mi
kube-systemcoredns-86c58d9df4-rw6tt 3m 23Mi
kube-systemetcd-node 120m 86Mi
部署prometheus
相关地址信息
Prometheus github地址:https://github.com/coreos/kube-prometheus
组件说明
- MetricServer:是kubernetes集群资源使用情况的聚合器,收集数据给kubernetes集群内使用,如kubectl,hpa,scheduler等。
- PrometheusOperator:是一个系统监测和警报工具箱,用来存储监控数据。
- NodeExporter:用于各node的关键度量指标状态数据。
- KubeStateMetrics:收集kubernetes集群内资源对象数据,制定告警规则。
- Prometheus:采用pull方式收集apiserver,scheduler,
controller-manager,kubelet组件数据,通过http协议传输。 - Grafana:是可视化数据统计和监控平台。
构建记录
$ git clone https://github.com/coreos/kube-prometheus.git
$ cd /root/kube-prometheus/manifests
修改grafana-service.yaml文件,使用nodepode方式访问grafana:
$ vim grafana-service.yaml
apiVersion: v1
kind: Service
metadata:
name: grafana
namespace: monitoring
spec:
type: NodePort #添加内容
ports:
- name: http
port: 3000
targetPort: http
nodePort: 30100 #添加内容
selector:
app: grafana
修改prometheus-service.yaml,改为nodepode
$ vim prometheus-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
prometheus: k8s
name: prometheus-k8s
namespace: monitoring
spec:
type: NodePort
ports:
- name: web
port: 9090
targetPort: web
nodePort: 30200
selector:
app: prometheus
prometheus: k8s
修改alertmanager-service.yaml,改为nodepode
vim alertmanager-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
alertmanager: main
name: alertmanager-main
namespace: monitoring
spec:
type: NodePort
ports:
- name: web
port: 9093
targetPort: web
nodePort: 30300
selector:
alertmanager: main
app: alertmanager
然后去下载prometheus的镜像,教材中有,如果没有则自行百度
把上图这三个文件拉到master节点
解压prometheus.tar.gz
查看load-images.sh脚本:
#!/bin/bash
cd /root/prometheus
ls /root/prometheus | grep -v load-images.sh > /tmp/k8s-images.txt
for i in $(cat /tmp/k8s-images.txt)
do
docker load -i %i
done
rm -rf /tmp/k8s-images.txt
执行命令:
$ mv prometheus load-images.sh /root/ # 将prometheus和load-images.sh脚本移到/root/目录下
$ chmod a+x load-images.sh
$ ./load-images.sh
脚本文件会帮我们加载Prometheus的镜像
之后执行scp -r prometheus/ load-image.sh root@k8s-node01:/root/将文件传至其他节点,然后在其他节点执行load-image.sh脚本加载镜像
之后进入master节点,进入/prometheus/kube-prometheus/manifests目录,这个目录会有一些yaml文件,那么我们执行kubectl apply -f ../manifests/执行这些yaml文件,如果有报错,是因为他们需要互相链接,多运行几次该命令即可
打开/prometheus/kube-prometheus/manifests/grafana-deployment.yaml可以看到构建的东西所在的命名空间是“monitoring”
执行kubectl get pod -n monitoring即可看到刚才构建的东西
此时执行kubectl top node、kubectl top pod就可以看到一些信息了:
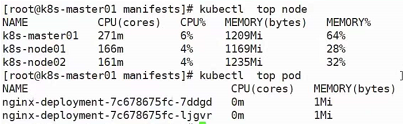
然后直接跳到下方的“访问prometheus”小结
Horizontal Pod Autoscaling
Horizontal Pod Autoscaling可以根据CPU利用率自动伸缩一个Replication Controller、Deployment或者Replica Set中的Pod数量
为了演示Horizontal Pod Autoscaler,我们将使用一个基于php-apache镜像的定制Docker镜像。在https://k8smeetup.github.io/docs/user-guide/horizontal-pod-autoscaling/image/Dockerfile可以看到完整的Dockerfile定义。镜像中包括一个https://k8smeetup.github.io/docs/user-guide/horizontal-pod-autoscaling/image/index.php页面,其中包含了一些可以运行CPU密集计算任务的代码,用于测试
下载完之后在所有节点使用docker load -i导入镜像
然后执行:
# --requests=cpu=200m意思是CPU最大资源限制200M
$ kubectl run php-apache --image=gcr.io/google_containers/hpa-example --requests=cpu=200m --expose --port=80
使用kubectl top pod或kubectl top pod POD_NAME查看pod的CPU以及内存的占用率:

创建HPA控制器
# 意思是cpu利用率一旦超过50%就开始创建副本开始负载均衡,最少1个副本,最大10个副本
$ kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
查看HPA控制器
$ kubectl get hpa

增加负载,查看负载节点数目
# 首先开启一个pod
$ kubectl run -i --tty load-generator --image=busybox /bin/sh
# 然后在该pod下运行下述代码,表示一直请求上述所说的php页面
$ while true; do wget -q -O- http://php-apache.default.svc.cluster.local; done
然后回master节点,执行kubectl get hpa -w:
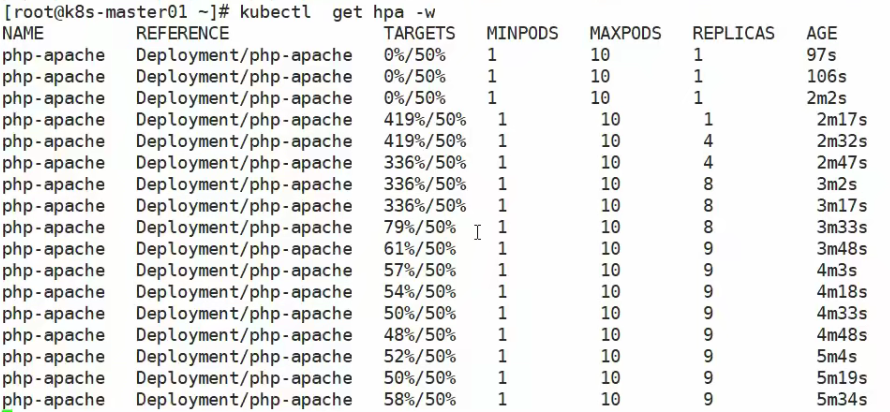
TARGETS中“419%/50%”中419%为当前CPU实际利用率,50%为阈值(也就是在创建hpa的时候执行autoscale命令的时候设置的"--cpu-percent=50")
执行kubectl get pod -w,会发现php-apache自动在扩展:
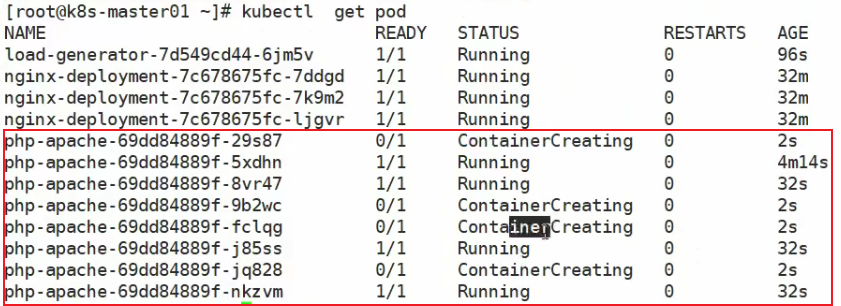
但是到10个为止就不会再继续扩展了因为设置了--max=10
此时我们将用于请求测试的pod删掉,会发现CPU利用率逐渐下降到50%以下,但会发现pod并没有被及时缩容(扩容的时候挺快的),原因是可能存在一种场景:由于网络原因请求一下子就下去了,如果此时pod缩容,一旦网络恢复请求一下子上去,极有可能把那个仅存的pod压死,在等待了很长时间之后,他最终会缩容到一个节点
现阶段hpa只支持对于cpu和内存去进行扩缩容,以后肯定会有更多的特性,比如基于网络io、基于磁盘io或者指定的阈值来进行扩缩容
资源限制
在讲docker的时候说过一定要给docker设置资源使用的阈值,比方说cpu利用率、内存利用率等,做这些措施主要为了防止出现OOM机制杀死一些重要的进程,所以资源限制是非常重要的,在k8s中,主要有两种资源限制,一种是pod资源限制,一种是名称空间资源限制
资源限制 - Pod
Kubernetes对资源的限制实际上是通过cgroup来控制的,cgroup是容器的一组用来控制内核如何运行进程的相关属性集合。针对内存、CPU和各种设备都有对应的cgroup
默认情况下,Pod运行没有CPU和内存的限额。这意味着系统中的任何Pod将能够像执行该Pod所在的节点一样,消耗足够多的CPU和内存。一般会针对某些应用的pod资源进行资源限制,这个资源限制是通过resources的requests和limits来实现
spec:
containers:
- image: xxxx
imagePullPolicy: Always
name: auth
ports:
- containerPort: 8080
protocol: TCP
resources:
limits:
cpu: "4"
memory: 2Gi
requests:
cpu: 250m
memory: 250Mi
requests要分分配的资源,limits为最高请求的资源值。可以简单理解为初始值和最大值
如果直接用命令创建pod时可以这么写:
# --requests=cpu=200m意思是CPU最大资源限制200M
$ kubectl run php-apache --image=img01 --requests=cpu=200m
资源限制 - 名称空间
Ⅰ、计算资源配额
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources
namespace: spark-cluster
spec:
hard:
pods: "20"
requests.cpu: "20"
requests.memory: 100Gi
limits.cpu: "40"
limits.memory: 200Gi
Ⅱ、配置对象数量配额限制
apiVersion: v1
kind: ResourceQuota
metadata:
name: object-counts
namespace: spark-cluster
spec:
hard:
configmaps: "10"
persistentvolumeclaims: "4"
replicationcontrollers: "20"
secrets: "10"
services: "10"
# loadbalancer上面讲过,是基于云服务器做负载均衡的一种方案
services.loadbalancers: "2"
Ⅲ、配置CPU和内存LimitRange
pod资源限制如果不设置resources的requests和limits的话,会使用当前名称空间下的最大资源,如果名称空间资源限制也不设置的话默认使用集群中的最大资源,这种时候极有可能出现OOM
那么如何设置一个pod能够使用的最大的默认值呢?或者pod里面容器能够使用的最大的默认值呢?就是采用LimitRange
apiVersion: v1
kind: LimitRange
metadata:
name: mem-limit-range
spec:
limits:
- default:
# 如果不够用内存最大 50Gb,cpu最大 5核心
memory: 50Gi
cpu: 5
defaultRequest:
# 一上来默认分配内存 1Gb,cpu 1核心
memory: 1Gi
cpu: 1
type: Container
- default即limit的值
- defaultRequest即request的值
访问prometheus
prometheus对应的nodeport端口为30200,访问http://MasterIP:30200
通过访问http://MasterIP:30200/target可以看到prometheus已经成功连接上了k8s的apiserver
如果都是UP状态,则代表已经成功部署
查看service-discovery
Prometheus自己的指标
prometheus的WEB界面上提供了基本的查询K8S集群中每个POD的CPU使用情况,查询条件如下:
sum by (pod_name)( rate(container_cpu_usage_seconds_total{image!="", pod_name!=""}[1m] ) )
上述的查询有出现数据,说明node-exporter往prometheus中写入数据正常
接下来我们就可以部署grafana组件,实现更友好的webui展示数据了
访问grafana
查看grafana服务暴露的端口号:
$ kubectl get service -n monitoring | grep grafana
grafana NodePort 10.107.56.143 <none> 3000:30100/TCP 20h
如上可以看到grafana的端口号是30100,浏览器访问http://MasterIP:30100用户名密码默认admin/admin

修改密码并登陆
添加数据源grafana默认已经添加了Prometheus数据源,grafana支持多种时序数据源,每种数据源都有各自的查询编辑器
Prometheus数据源的相关参数:
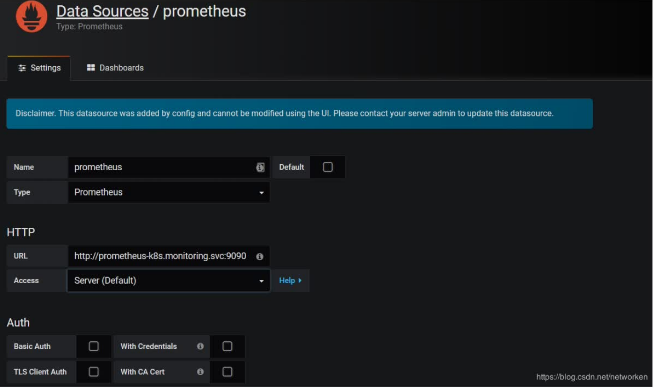
目前官方支持了如下几种数据源:
导入已有的dashboard模板:
然后进入Home:
随便找一个节点:
比方说node节点:
再比方说pod的:
部署 EFK 平台
架构图:
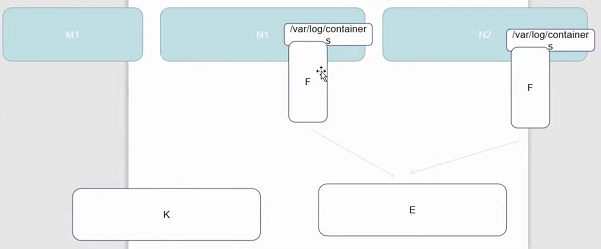
首先有一个master节点,两个node节点,使用daemon方式部署fluentd,然后在master节点添加fluentd的污点,这样可以保证除了master节点,每个node节点上都能部署一个F,然后再将node节点某个文件目录挂载到F中。然后F再将数据传递给elasticsearch,这里采用集群化部署E,防止E出现单点故障,然后再用kibana展示数据。
当然,这套架构也可以使用进程的方式去部署(很麻烦),这里采用k8s部署,即基于pod去部署,当然我们也不会手动去创建deployment,那样也麻烦,最终我们会使用helm部署。
添加Google incubator仓库
helm repo add incubator http://storage.googleapis.com/kubernetes-charts-incubator
部署Elasticsearch
kubectl create namespace efk
helm fetch incubator/elasticsearch
下载完之后解压,然后进入文件目录,打开values.yaml进行修改:
...
cluster:
env:
# 在当前集群下最少的master节点个数必须要有两个才证明这个集群是活跃的状态,如果电脑内存只有16g,建议只开1个就够了
MINIMUM_MASTER_NODES: "2"
...
client:
# 客户端副本数
replicas: 1
...
master:
# master副本数
replicas: 1
persistence:
# 这里有个持久卷需要有一个PVC请求,但是实验中没有多余的PV给他用了,因此enabled改为false,在实际生产环境中,只要PV能满足这里的要求的,就可以将enabled改为true
enabled: false
accessMode: ReadWriteOnce
name: data
size: "4Gi"
# storageClass: "ssd"
...
data:
# data副本数
replicas: 1
persistence:
# 这里有个持久卷需要有一个PVC请求,但是实验中没有多余的PV给他用了,因此enabled改为false,在实际生产环境中,只要PV能满足这里的要求的,就可以将enabled改为true
enabled: false
accessMode: ReadWriteOnce
name: data
size: "30Gi"
# storageClass: "ssd"
使用helm进行安装
$ helm install --name els1 --namespace=efk -f values.yaml incubator/elasticsearch
安装完之后可以起一个临时pod进行测试:
# 这里--rm是指退出之后就删除该pod
kubectl run cirror-$RANDOM --rm -it --image=cirros --/bin/sh
# 实验中是:curl 10.101.94.81:9200/_cat/nodes
curl Elasticsearch:Port/_cat/nodes

说明E的集群没有问题
部署Fluentd
helm fetch stable/fluentd-elasticsearch
tar -zxvf fluentd-elasticsearch-xxx
然后修改文件中values.yaml中Elasticsearch访问地址:
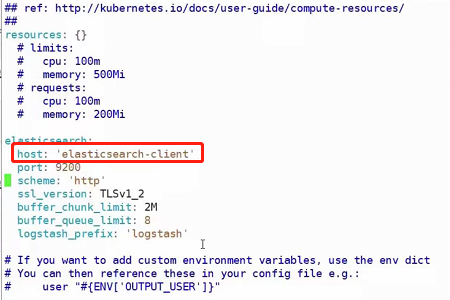
使用kubectl get svc -n efk:

这个就是Elasticsearch访问地址
使用helm进行安装:
$ helm install --name flu1 --namespace=efk -f values.yaml stable/fluentd-elasticsearch
由于F是使用daemon方式部署,因此理论上node01和node02节点上都应该部署了F:
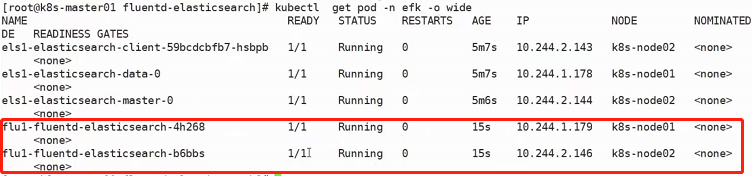
部署kibana
# --version指定版本
# 注意,部署EFK或ELK的时候E和K的版本一定要一致,不然会报错
helm fetch stable/kibana --version 0.14.8
tar -axvf stable/kibana-xxx
还是跟上面一样,打开values.yaml,修改ElasticSearch地址:
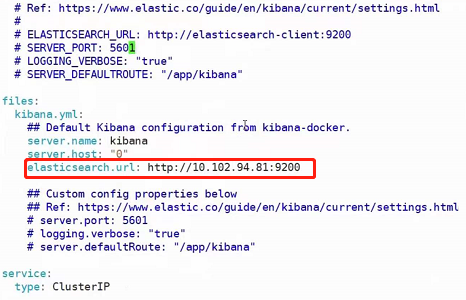
然后我们看到kibana使用到的镜像及其版本:
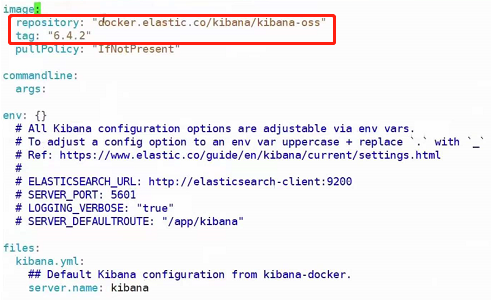
可以使用docker pull xxx:xx将其提前下载下来
下载完之后使用docker save -o xx.tar保存该镜像,使用scp xx.tar root@k8s-node02:/root/将文件传输到node02,然后在node02使用docker load -i xx.tar导入镜像
使用helm进行安装:
helm install --name kib1 --namespace=efk -f values.yaml stable/kibana --version 0.14.8
使用kubectl get svc -n efk可以看到kibana暴露端口类型是ClusterIP,使用kubectl edit svc xxx -n efk,将ClusterIP改为NodePort
之后就能访问了:
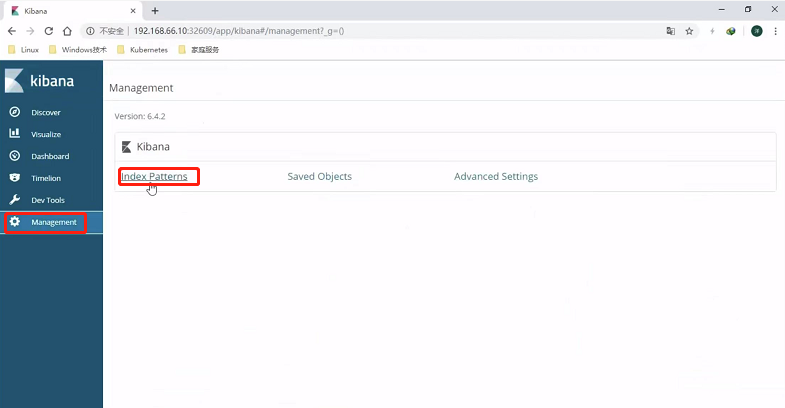
点击management,点击index patterns创建索引序列,可以根据时间进行创建,为什么要创建索引序列呢?因为如果把所有的文件都索引上了速度会很慢
然后选择使用时间序列进行分片:
创建完成:
查看日志:
证书可用年限修改
针对问题:证书时间到期
k8s的证书:
$ cd /etc/kubernetes/pki # 这个目录下全是关于k8s的证书(xxx.crt xxx.key xxx.pub xxx.pem ...)
$ openssl x509 -in apiserver.crt -text -noout # apiserver.crt就是k8s的证书,这里我们输出证书的文本信息
可以看到证书的起始终止时间,是1年。
再看看ca.crt的信息:
可以看到是10年
所以按证书年限可以分为两类,一类1年,一类10年。
apiserver.crt见名知意就是k8s中apiserver的证书,apiserver是进入k8s的唯一途径,那么他只有一年有效期显然是不够用的
那么为什么官方只给一年有效期的证书呢?官方这么做可能是希望我们能跟随他的脚步频繁更新k8s集群,因为一旦更新k8s版本,证书的问题是不需要我们考虑的,他自己就会帮我们替换成一张新证书。但是有很多企业会跑一些离线的业务,由于隔离网络,更新集群就很不方便了,因此只能写脚本手动触发证书的更新,但是这样还是很麻烦。此时就能想到既然k8s集群可以用kubeadm搭建,证书自然也是通过他来获取的,那么能不能通过修改kubeadm的源码来控制证书的有效年限呢?可以的!这也是我们要学习的一种方案
想法就是先把kubeadm源码down下来,修改证书年限,再创建集群即可
1、go环境部署(要修改kubeadm源码,因此需要搭建go环境)
$ wget https://dl.google.com/go/go1.12.7.linux-amd64.tar.gz
$ tar -zxvf go1.12.1.linux-amd64.tar.gz -C /usr/local
$ vi /etc/profile
export PATH=$PATH:/usr/local/go/bin
$ source /etc/profile
当然,上面这个go的网址被墙了,速度很慢甚至不能访问,如果要下载go,可以在百度输入“go中文社区”,进入下载页面下载linux版本即可:
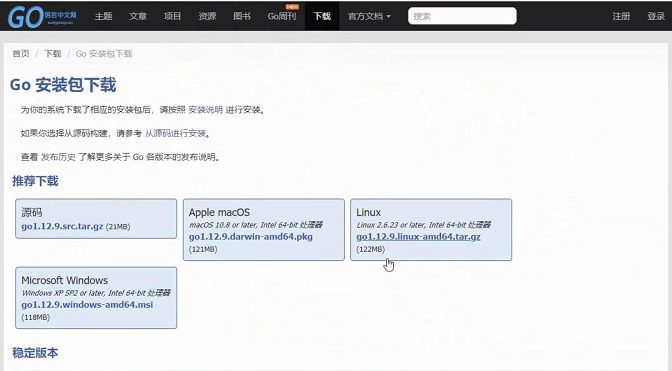
下完之后执行tar -zxvf xxx.tar.gz -C /usr/local/将文件解压到指定目录
然后点击安装说明:
按照提示配置环境变量即可:
执行vim /etc/profile,添加go环境变量,然后执行source /etc/profile
2、下载源码
$ cd /data && git clone https://github.com/kubernetes/kubernetes.git
下载完之后要将git仓库分支切到kubeadm对应的版本上
执行kubeadm version可以查看kubeadm版本:

可以看到GitVersion是v1.15.1
执行$ git checkout -b remotes/origin/release-1.15.1 v1.15.1创建新分支remotes/origin/release-1.15.1并指向v1.15.1
3、修改Kubeadm源码包更新证书策略
$ vim staging/src/k8s.io/client-go/util/cert/cert.go # kubeadm 1.14 版本之前
$ vim cmd/kubeadm/app/util/pkiutil/pki_helpers.go # kubeadm 1.14 至今。1.17版本之后就不确定了,需要查看kubernetes官网的开发者手册
const duration365d = time.Hour * 24 * 365
NotAfter: time.Now().Add(duration365d).UTC(),
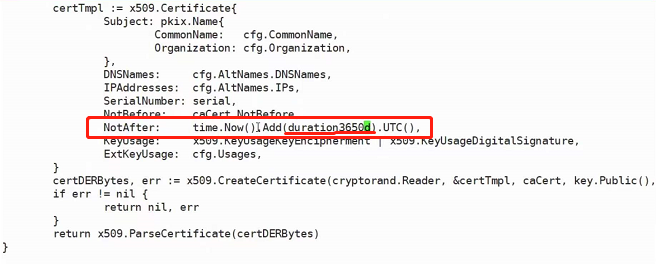
# 编译kubeadm
$ make WHAT=cmd/kubeadm GOFLAGS=-v
$ cp _output/bin/kubeadm /root/kubeadm-new
4、更新kubeadm
# 将 kubeadm 进行替换
# 备份原先的kubeadm(演示的时候可能为了后续回复方便,老师将原先的kubeadm做了备份)
$ cp /usr/bin/kubeadm /usr/bin/kubeadm.old
# 将/root/kubeadm-new复制过来
$ cp /root/kubeadm-new /usr/bin/kubeadm
# 赋予权限
$ chmod a+x /usr/bin/kubeadm
5、更新各节点证书至Master节点
# 备份pki
$ cp -r /etc/kubernetes/pki /etc/kubernetes/pki.old
$ cd /etc/kubernetes/pki
# kubeadm-config.yaml是安装k8s集群时需要用到的yaml文件,由此可见,这些文件一定要好好保存,不要用过一次之后就丢了
$ kubeadm alpha certs renew all --config=/root/kubeadm-config.yaml
$ openssl x509 -in apiserver.crt -text -noout | grep Not
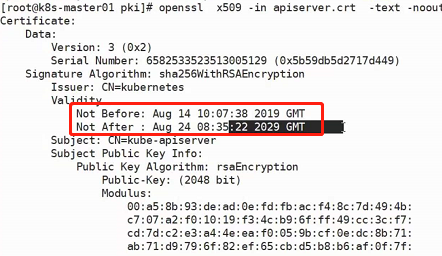
此时证书时限就变成10年了
6、HA集群其余master节点证书更新
#!/bin/bash
# 其余master节点ip地址
masterNode="192.168.66.20 192.168.66.21"
# for host in ${masterNode}; do
# scp /etc/kubernetes/pki/{ca.crt,ca.key,sa.key,sa.pub,front-proxy-ca.crt,front-proxy-ca.key} "${USER}"@$host:/etc/kubernetes/pki/
# scp /etc/kubernetes/pki/etcd/{ca.crt,ca.key} "root"@$host:/etc/kubernetes/pki/etcd
# scp /etc/kubernetes/admin.conf "root"@$host:/etc/kubernetes/
# done
for host in ${CONTROL_PLANE_IPS}; do
scp /etc/kubernetes/pki/{ca.crt,ca.key,sa.key,sa.pub,front-proxy-ca.crt,front-proxy-ca.key} "${USER}"@$host:/root/pki/
scp /etc/kubernetes/pki/etcd/{ca.crt,ca.key} "root"@$host:/root/etcd
scp /etc/kubernetes/admin.conf "root"@$host:/root/kubernetes/
done
高可用k8s集群搭建
node节点被master监控,node节点一旦损坏会进行离线处理,在master端会发现该node是一个notready的状态,此时在该node中的pod就可以被驱离了,这是node节点的高可用,但万一master节点故障了呢?
换句话说,node节点的死亡不会使得集群死亡,但单节点master一旦死亡集群就死亡了
如果采用ETCD在k8s集群内部被托管的方案的话(还有一种方案是在集群外部或者其他节点服务器去构建ETCD集群,然后k8s连接过去),要实现高可用需要做到Apiserver、ETCD、controller-manager、scheduler这四个模块的高可用,还有两个关键模块kubelet和proxy是在每个节点上去运行的,节点死完后,他们只会在当前节点上运行并完成任务,所以他们是不需要高可用的
当然,Apiserver、ETCD、controller-manager、scheduler这四个模块的高可用在kubeadm发展到1.15版本之后它的实现方案就不一致了
对于apiserver来说,如果同时存在三个不同的apiserver的话并不会影响集群的访问,他们会有一个竞争关系,就是跟ETCD去沟通,处理对应的事务即可
对于ETCD来说,如果指定多主集群的话,多台主服务器在加入主集群内部以后,ETCD会实现一个集群化的扩展,也就是说,放在集群内部的ETCD会自动变成一个ETCD高可用集群
对于controller-manager和scheduler来说,如果向k8s指定多主集群的话,多个controller-manager中只有一个会正常工作,其余的会处于挂起状态,一旦工作状态的那个死了,会从其余的里面随机选一个将他由挂起状态唤醒无缝接替工作。scheduler也是这样。
总结来讲,除了apiserver,别的模块的高可用k8s都已经帮我们解决了
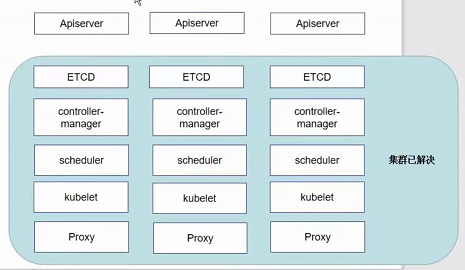
那么apiserver我们知道其实就相当于一个web服务器,采用的就是restful风格的http协议,既然是http协议,我们就可以采用一个4层或者7层代理
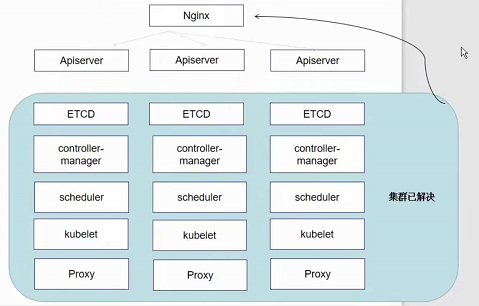
任何集群内的请求都不交给apiserver了而是交给nginx,然后nginx再去做反向代理将请求分发到apiserver,任何一个节点死亡(或者说apiserver死亡),nginx就会将它排除出去
nginx部署在别的节点还是有点消耗资源的,那么可以在每个节点上都部署一个nginx,然后他们之间通过keepalive(或者说heartbeat)选出一个VIP,然后集群直接连接VIP同样可以实现高可用
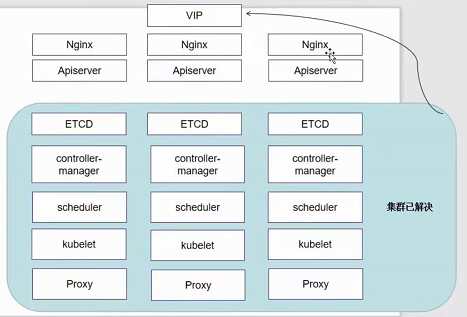
国内有个软件叫“睿云Breeze”他是基于kubeadm实现的,并且它通过haproxy和keepalive实现了apiserver的高可用,并且他以镜像的方式将haproxy和apiserver这两个东西封装起来了
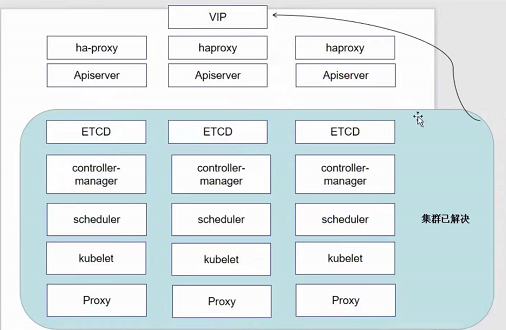
此时通过keepalive从haproxy中选出VIP,集群指向这个VIP即可
系统初始化
按步骤进行检查
$ getenforce
Disabled
$ systemctl status firewalld
inactive
$ systemctl status iptables
active
设置系统主机名以及Host文件的相互解析
$ hostnamectl set-hostname k8s-master01
# 设置域名解析
$ vim /etc/hosts
执行scp命令将/etc/hosts文件传输到其余所有节点,然后ping以下域名看看行不行
安装依赖包
$ yum install -y conntrack ntpdate ntp ipvsadm ipset jq iptables curl sysstat libseccomp wget vim net-tools git
设置防火墙为Iptables并设置空规则
$ systemctl stop firewalld && systemctl disable firewalld
$ yum -y install iptables-services && systemctl start iptables && systemctl enable iptables && iptables -F && service iptables save
关闭SELINUX
swapoff -a && sed -i '/swap/s/^\(.*\)$/#\1/g' /etc/fstab
setenforce 0 && sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config
调整内核参数,对于K8S
$ cat > kubernetes.conf <<EOF
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
net.ipv4.ip_forward=1
net.ipv4.tcp_tw_recycle=0
vm.swappiness=0 # 禁止使用 swap 空间,只有当系统 OOM 时才允许使用它
vm.overcommit_memory=1 # 不检查物理内存是否够用
vm.panic_on_oom=0 # 开启 OOM
fs.inotify.max_user_instances=8192
fs.inotify.max_user_watches=1048576
fs.file-max=52706963
fs.nr_open=52706963
net.ipv6.conf.all.disable_ipv6=1
net.netfilter.nf_conntrack_max=2310720
EOF
$ cp kubernetes.conf /etc/sysctl.d/kubernetes.conf
$ sysctl -p /etc/sysctl.d/kubernetes.conf
调整系统时区
# 设置系统时区为 中国/上海
$ timedatectl set-timezone Asia/Shanghai
# 将当前的 UTC 时间写入硬件时钟
$ timedatectl set-local-rtc 0
# 重启依赖于系统时间的服务
$ systemctl restart rsyslog
$ systemctl restart crond
关闭系统不需要服务
$ systemctl stop postfix && systemctl disable postfix
设置rsyslogd和systemd journald
mkdir /var/log/journal # 持久化保存日志的目录
mkdir /etc/systemd/journald.conf.d
cat > /etc/systemd/journald.conf.d/99-prophet.conf <<EOF
[Journal]
# 持久化保存到磁盘
Storage=persistent
# 压缩历史日志
Compress=yes
SyncIntervalSec=5m
RateLimitInterval=30s
RateLimitBurst=1000
# 最大占用空间 10G
SystemMaxUse=10G
# 单日志文件最大 200M
SystemMaxFileSize=200M
# 日志保存时间 2 周
MaxRetentionSec=2week
#不将日志转发到 syslog
ForwardToSyslog=no
EOF
systemctl restart systemd-journald
升级系统内核为4.44
CentOS 7.x系统自带的3.10.x内核存在一些Bugs,导致运行的Docker、Kubernetes不稳定,例如:rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-3.el7.elrepo.noarch.rpm
$ rpm -Uv hhttp://www.elrepo.org/elrepo-release-7.0-3.el7.elrepo.noarch.rpm
# 安装完成后检查 /boot/grub2/grub.cfg 中对应内核 menuentry 中是否包含 initrd16 配置,如果没有,再安装一次!
$ yum --enablerepo=elrepo-kernel install -y kernel-lt
# 设置开机从新内核启动
$ grub2-set-default "CentOS Linux (4.4.182-1.el7.elrepo.x86_64) 7 (Core)"
# 重启后安装内核源文件
$ yum --enablerepo=elrepo-kernel install kernel-lt-devel-$(uname -r) kernel-lt-headers-$(uname-r)
关闭NUMA
$ cp /etc/default/grub{,.bak}
$ vim /etc/default/grub # 在GRUB_CMDLINE_LINUX 一行添加 `numa=off` 参数,如下所示:
$ diff /etc/default/grub.bak /etc/default/grub
6c6
< GRUB_CMDLINE_LINUX="crashkernel=auto rd.lvm.lv=centos/root rhgb quiet"
---
> GRUB_CMDLINE_LINUX="crashkernel=auto rd.lvm.lv=centos/root rhgb quiet numa=off"
$ cp /boot/grub2/grub.cfg{,.bak}
$ grub2-mkconfig -o /boot/grub2/grub.cfg
kubeadm 部署安装
kube-proxy开启ipvs的前置条件
modprobe br_netfilter
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack_ipv4
安装Docker软件
$ yum install -y yum-utils device-mapper-persistent-data lvm2
$ yum-config-manager \
--add-repo \
http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
$ yum update -y && yum install -y docker-ce
# 更新yum并重启之后有些文件可能会被重新覆盖,因此可能还需要重新再设置一下开机从新内核启动
$ grub2-set-default "CentOS Linux (4.4.182-1.el7.elrepo.x86_64) 7 (Core)"
# 验证一下到底有没有从新内核启动
$ uname -r
## 创建 /etc/docker 目录
$ mkdir /etc/docker
# 配置 daemon.
$ cat > /etc/docker/daemon.json <<EOF
{
# 指定使用systemd为cgroupdriver
"exec-opts": ["native.cgroupdriver=systemd"],
# 设置docker日志保存为json文件
"log-driver": "json-file",
"log-opts": {
# 设置轮替大小是100m
"max-size": "100m"
}
}
EOF
$ mkdir -p /etc/systemd/system/docker.service.d
# 重启docker服务
$ systemctl daemon-reload && systemctl restart docker && systemctl enable docker
在主节点启动Haproxy与Keepalived容器
导入脚本 > 运行 > 查看可用节点
$ mkdir /usr/local/kubernetes/install
$ cd !$ # 表示进入/usr/local/kubernetes/install
然后将镜像拖入
上图haproxy、keepalived这两个镜像是“睿云“公司编写的,他们的”Breeze”就是利用这两个镜像去实现的,kubeadm-basic是kubeadm的基础镜像,其余的文件就是一些启动脚本
然后将这些文件传输到其他master节点
$ scp * root@k8s-master03:/usr/local/kubernetes/install/
导入镜像
$ docker load -i haproxy.tar
$ docker load -i keepalived.tar
$ tar -zxvf kubeadm-basic.images.tar.gz
之后修改load-images.sh脚本(这个脚本的目的是为了导入kubeadm-basic.images中的一系列镜像)
$ vim load-images.sh
#!bin/bash
cd /usr/local/kubernetes/install/kubeadm-basic.images/
ls /usr/local/kubernetes/install/kubeadm-basic.images/ | grep -v load-images.sh > /tmp/k8s-images.txt
for i in $( cat /tmp/k8s-images.txt )
do
docker load -i $i
done
rm -rf /tmp/k8s-images.txt
将脚本文件导入到其他master节点
$ scp load-images.sh root@k8s-master03:/usr/local/kubernetes/install/
修改load-images.sh权限并执行
$ chmod a+x load-images.sh
$ ./load-images.sh
接下来解压start.keep.tar.gz
$ tar -zxvf start.keep.tar.gz
$ mv data/ /
$ cd /data/
修改haproxy.cfg配置文件
$ vim /data/lb/etc/haproxy.cfg
打开这个文件,我们会发现使用的端口是6444:
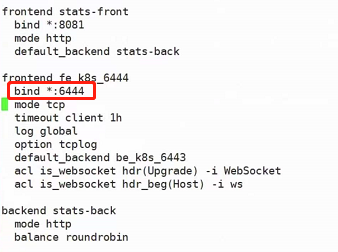
修改一下负载到的每一个节点:
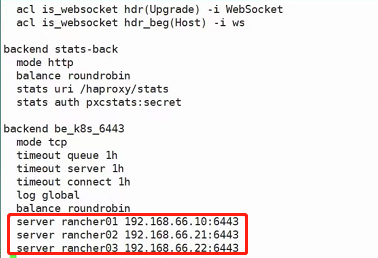
由于如果要一个一个节点添加且同时写三个负载集群的话(上图红圈圈),第一个(192.168.66.10)在新建成功以后第二个再加入的话可能要负载到第二个节点(192.168.66.21)上,这样他就加入失败了(实验的时候老师是这么说的,不清楚具体理由)
因此先备份haproxy.cfg文件
$ cp haproxy.cfg /root/
然后打开haproxy.cfg文件,把上述三个节点只保留一个
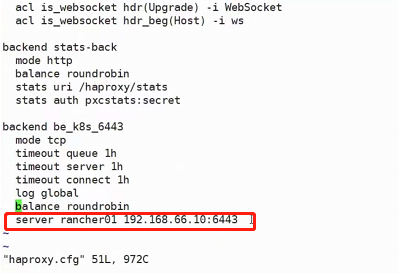
然后再打开start-haproxy.sh脚本
$ vim /data/lb/start-haproxy.sh
修改master节点ip地址:
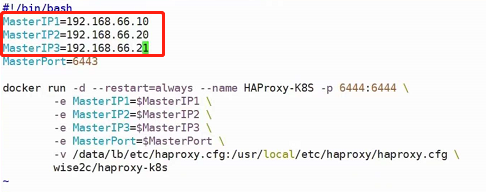
改完之后执行
$ ./start-haproxy.sh
$ netstat -anpt | grep :6444

然后打开start-keepalived.sh脚本
$ vim /data/lb/start-keepalived.sh
修改虚拟IP地址以及网卡:
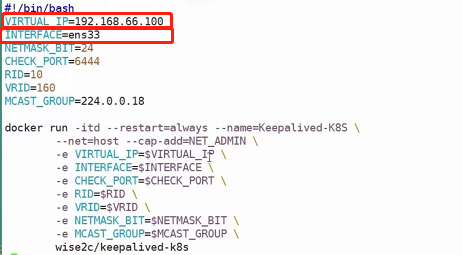
网卡可以通过ifconfig得知是“ens33”
改完后执行
$ ./start-keepalived.sh
$ ip addr show
可以看到192.168.66.100这个虚拟IP已经起来了:
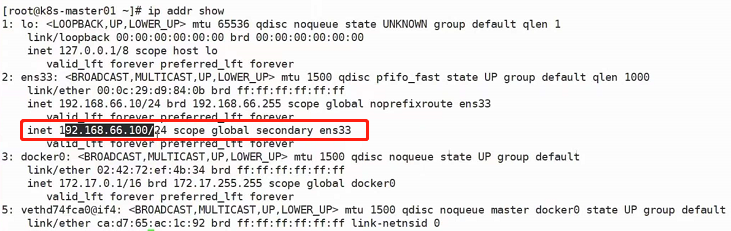
安装Kubeadm(主从配置)
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
yum -y install kubeadm-1.15.1 kubectl-1.15.1 kubelet-1.15.1
# kubelet用于维持容器的生命周期,所以kubelet的服务肯定是要被启动的
systemctl enable kubelet.service
初始化主节点
上述所有文件都是在/usr/local/kubernetes/install目录下,首先在该目录新建文件夹images/,然后将该目录下文件全部移至images/文件夹下
# 下面这行命令会初始化一个kubeadm-config.yaml文件,但里面具体参数的修改请自行上网搜索,如果实在找不到案例,可以参考教学视频“尚硅谷Kubernetes教程(K8s入门到精通) 12-3_尚硅谷_高可用的 K8S 构建 -3”第13分钟左右 视频中会出现一个完整的配置好的kubeadm-config.yaml文件
kubeadm config print init-defaults > kubeadm-config.yaml
在kubeadm-config.yaml文件中做出的修改:
修改advertiseAddress为当前节点的IP地址
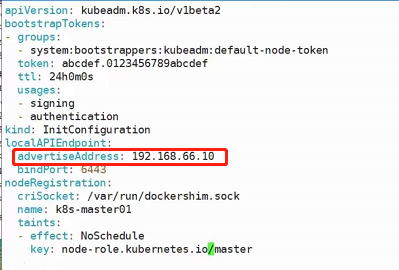
修改controlPlaneEndpoint为高可用的虚拟IP地址,注意这里默认情况下是一个空字符串,并且如果不创建高可用集群的话这里不需要去填写,但是如果要创建高可用集群,这个地方就需要填写高可用虚拟IP地址了(即上面使用keepalived虚拟出来的地址)
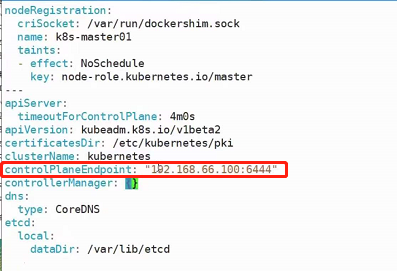
改完之后执行kubeadm初始化
# tee的作用:在初始化kubeadm的过程中显示 kubeadm-init.log 文件中的内容
$ kubeadm init --config=kubeadm-config.yaml --experimental-upload-certs | tee kubeadm-init.log
完成之后会出现提示信息:
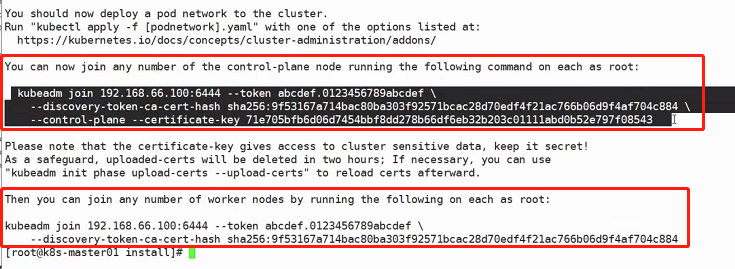
根据kubeadm-init.log的信息,我们发现他比没有构建高可用集群的时候多了些内容(上图第一个红圈圈是多出来的内容,第二个红圈圈是之前没有构建高可用集群的时候也会存在的这么一条信息)
这俩条命令见名知意,一条是用于添加控制节点,一条是用于添加工作节点
需要注意的是,这种方式是在1.14版本之后出现的,1.14之前是没有官方的kubeadm高可用方案的,只能手动拷贝cert证书,而在这里他会帮我们自动生成一个cert证书
然后kubeadm-init.log会有下一步的提示:
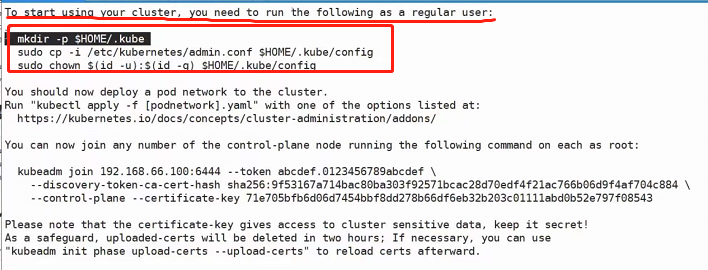
按照提示执行:
$ mkdir -p $HOME/.kube
$ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
$ sudo chown $(id -u):$(id -g) $HOME/.kube/config
之后可以打开/root/.kube.config看看

这里的地址也已经改为了高可用的虚拟IP地址
执行kubectl get node:

会发现已经ok了,并且发起的端口应该是6444的,也就是说haproxy已经生效了
需要注意的是,现在的负载节点只有一个,另外两个负载节点的做法也是一样的
我们执行scp haproxy.cfg root@192.168.66.20:/root/和scp haproxy.cfg root@192.168.66.21:/root/发送文件
然后到对应节点执行
$ cd /usr/local/kubernetes/install
$ tar -zxvf start.keep.tar.gz
$ mv /data /
$ cp -a haproxy.cfg /data/lb/etc/haproxy.cfg
$ cd /data/lb
$ vim /etc/haproxy.cfg
跟上面创建第一个负载节点的时候一样,haproxy.cfg中负载节点还是只保留一个,把多余的都删掉:
到时候全部做完之后再去添加,这么做的原因是如果现在保留很多负载节点,再去进行后端的添加的话,他可能会负载到一个未启动的节点之上,他就会报错
其实现在要修改的东西跟上面创建第一个负载节点的时候修改的东西是一样的,为了不费劲,我们直接删除节点的/data文件夹
然后回到第一个负载节点,执行:
$ scp -r /data root@k8s-master02:/
$ scp -r /data root@k8s-master03:/
再次回到第二个或第三个负载节点,执行:
$ cd /usr/local/kubenetes/install
$ docker load -i haproxy.tar
$ docker load -i keepalived.tar
$ cd /data/lb
$ ./start-haproxy.sh
$ ./start-keepalived.sh
$ docker ps -a # 查看haproxy和keepalived这两个容器是否启动成功
都ok之后仍旧是回到上方**安装Kubeadm(主从配置)小节,将安装Kubeadm(主从配置)**小节的那一大段代码再次在当前负载节点执行一次
然后就可以添加这个新的负载节点了
回到第一个负载节点,复制下面这段用于添加控制负载节点的命令
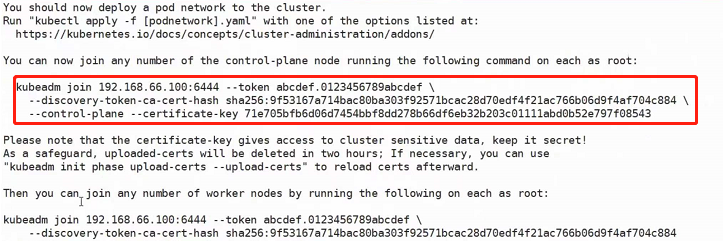
回到新的负载节点,粘贴该命令回车运行
完事之后会出现提示信息:
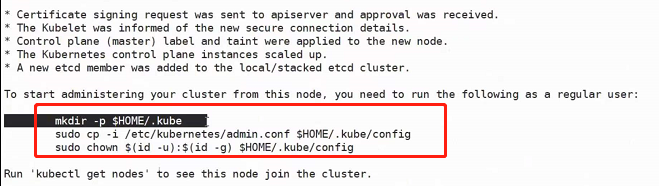
那么我们执行:
$ mkdir -p $HOME/.kube
$ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
$ sudo chown $(id -u):$(id -g) $HOME/.kube/config
然后执行kubectl get node:

会发现有两个负载节点了
执行cat .kube/config
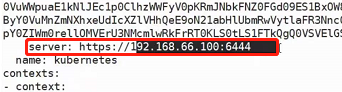
会发现地址也已经成功改为了高可用虚拟IP地址
接下来第三个负载节点的创建就不废话了,跟第二个一模一样
在第三个负载节点中执行kubectl get pod -n kube-system
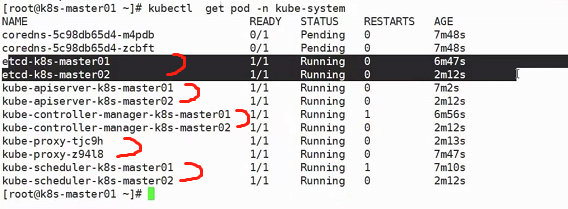
会发现etcd、apiserver、controller、proxy、scheduler全部变成了两个节点
第三个节点也加入之后,还需要改一下kubeadm的haproxy
执行docker ps | grep haproxy:

可以得知名称叫"HAProxy-K8S"
修改/usr/local/kubernetes/install/etc/haproxy.cfg文件,添加负载节点(每个负载节点都需要修改):
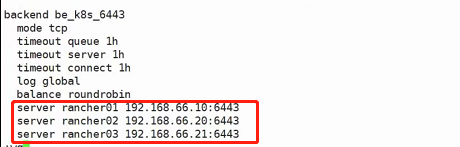
执行docker rm -f HAProxy-K8S && bash /data/lb/start-haproxy.sh重启haproxy镜像
然后把haproxy.cfg文件拷贝到其他负载节点,为了确保万无一失,在其他负载节点上重新执行:
$ mkdir -p $HOME/.kube
$ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
$ sudo chown $(id -u):$(id -g) $HOME/.kube/config
然后执行docker rm -f HAProxy-K8S && bash /data/lb/start-haproxy.sh重启haproxy镜像
到此为止,就ok了,但没完全ok,执行kubectl get node发现状态都是NotReady,原因是还没有部署flannel网络,那么我们部署一下
部署网络
首先回到上面kubeadm部署安装小节,在那里我们之前已经写好了一个kube-flannel.yaml文件,现在将他复制到第一个负载节点(注意,只需要在第一个负载节点中操作就可以了)的/usr/local/kubernetes/install目录下并执行kubectl apply -f kube-flannel.yaml,然后执行kubectl get pod -n kube-system:
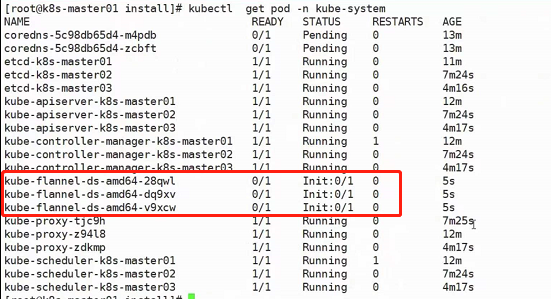
会发现flannel最终会被创建
然后再次执行kubectl get node会发现全部都Ready了
此时我们将其中一台机器shutdown -h now关机
然后执行kubectl get node会发现一个问题:kubectl get node这个命令执行了三下就不行了:
原因是在./kube/config文件中使用的访问地址是一个负载的地址,那么我们把他改为当前节点的地址:
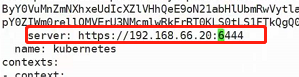
有什么含义呢?
节点本机连接集群的时候使用本机的地址即可,如果节点本机都已经死亡的情况下,是不可能再在该已死亡节点本机上去执行kubectl命令的,这是逻辑上的事情,也是实际操作中的情况,当然也是上面“其中一个节点shutdown之后,在另一个节点执行kubectl get node这个命令执行了三下就不行了”这个问题的解释
那么我们去给每一个负载节点做一下config文件的修改:
$ vim /root/.kube/config
将地址改为自己的地址:
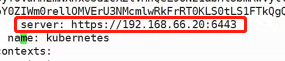
当然haproxy去找负载节点的话,是需要时间认证的,所以我们会发现在一个节点shutdown的情况下,执行kubectl get node显示全部节点仍旧都是Ready状态
加入主节点以及其余工作节点
执行安装日志中的加入命令即可
集群状态查看
首先将上述所有负载节点(master01、master02、master03)全部开启
在任意节点下执行kubectl get endpoints kube-controller-manager --namespace=kube-system -o yaml会发现controller-manager会工作在其中一个节点(这里是master02),其余节点的controller-manager是处于挂起状态的:
包括scheduler也是在master02(执行kubectl get endpoints kube-scheduler --namespace=kube-system -o yaml):
apiserver看不了,因为他是一个负载调度的实现方案,是我们自己外加的,不归k8s管
当然,也可以查看etcd的状态,可以执行下面的命令:
# 进入etcd-k8s-master01容器,-- 表示需要在容器中执行后续的这些命令,etcdctl 是容器内部去执行的命令,--endpoints 指定访问的地址为192.168.66.10:2379,2379是etcd的端口,--ca-file 指定ca证书,--cert-file 指定server证书,--key-file 指定密钥,cluster-health 表示指定查看的方式(或者说查看的结果)是cluster-health(集群的健康)
kubectl -n kube-system exec etcd-k8s-master01 -- etcdctl \
--endpoints=https://192.168.66.10:2379 \
--ca-file=/etc/kubernetes/pki/etcd/ca.crt \
--cert-file=/etc/kubernetes/pki/etcd/server.crt \
--key-file=/etc/kubernetes/pki/etcd/server.key \
cluster-health

这里告诉我们目前集群中有三个节点,而且集群是健康的
$ kubectl -n kube-system exec etcd-k8s-master01 -- etcdctl \
--endpoints=https://192.168.92.10:2379 \
--ca-file=/etc/kubernetes/pki/etcd/ca.crt \
--cert-file=/etc/kubernetes/pki/etcd/server.crt \
--key-file=/etc/kubernetes/pki/etcd/server.keycluster-health
$ kubectl get endpoints kube-controller-manager --namespace=kube-system -o yaml
$ kubectl get endpoints kube-scheduler --namespace=kube-system -o yaml
添加工作节点
那么工作节点的添加就很简单了,可以去/usr/local/kubernetes/install/kubeadm-init.log文件,看到下面这行命令:
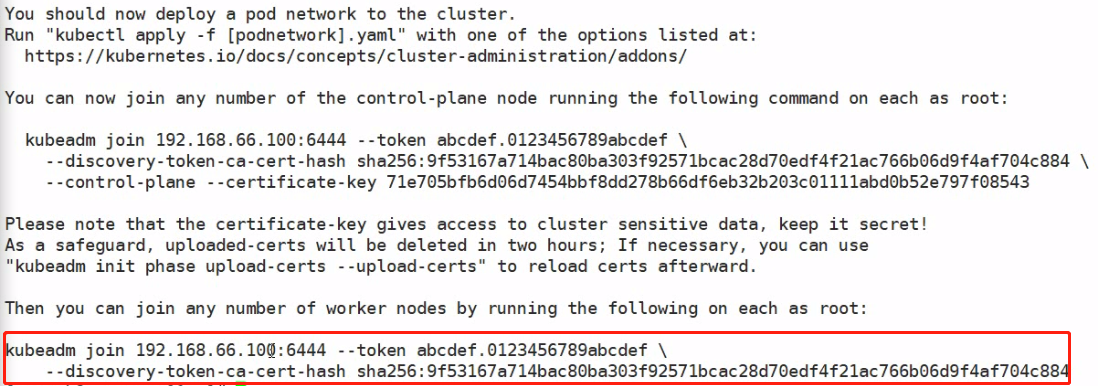
用这行命令逐一添加工作节点即可
部署案例
部署PowerJob:
apiVersion: v1
kind: ConfigMap
metadata:
name: init-config
namespace: xxx
data:
initdb.sql: |
CREATE DATABASE IF NOT EXISTS `powerjob-product` DEFAULT CHARSET utf8mb4;
TZ: Asia/Shanghai
JVMOPTIONS: ""
PARAMS: "--spring.profiles.active=product --spring.datasource.core.jdbc-url=jdbc:mysql://localhost:3306/powerjob-product?useUnicode=true&characterEncoding=UTF-8 --spring.datasource.core.username=root --spring.datasource.core.password=root --spring.data.mongodb.uri=mongodb://localhost:27017/powerjob-product"
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv0001
spec:
capacity:
storage: xxx
volumeMode: Filesystem
accessModes:
- xxx
# 回收策略
persistentVolumeReclaimPolicy: xxx
storageClassName: xxx
# mountOptions可以不用指定,让他自行判断
# mountOptions:
# - hard
# - nfsvers=4.1
nfs:
path: xxx
server: xxx
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv0002
spec:
capacity:
storage: xxx
volumeMode: Filesystem
accessModes:
- xxx
# 回收策略
persistentVolumeReclaimPolicy: xxx
storageClassName: xxx
# mountOptions可以不用指定,让他自行判断
# mountOptions:
# - hard
# - nfsvers=4.1
nfs:
path: xxx
server: xxx
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: powerjob-server-data
spec:
accessModes:
xxx
resources:
requests:
storage: xxx
# storageClassName: xxx
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: m2
spec:
accessModes:
xxx
resources:
requests:
storage: xxx
# storageClassName: xxx
---
apiVersion: v1
kind: Deployment
metadata:
name: powerjob-server
namespace: xxx
spec:
replicas: xxx
selector:
matchLabels:
app: powerjob-server
# release: xxx
# env: xxx
template:
metadata:
labels:
app: powerjob-server
# release: xxx
# env: xxx
spec:
# Init C没启动完毕之前Main C是不会启动的
containers:
- name: powerjob-server
# 这里镜像最好指定版本或者标签,不然的话默认下载latest,而10年前的latest跟现在的latest肯定不是一个版本,可能会导致镜像重复拉取最终导致拉取失败,导致报错,导致容器启动失败
image: tjqq/powerjob-server:latest
imagePullPolicy: IfNotPresent
ports:
- name: xxx1
containerPort: 7700
- name: xxx2
containerPort: 10086
env:
- name: TZ
valueFrom:
configMapKeyRef:
name: init-config
key: TZ
- name: JVMOPTIONS
valueFrom:
configMapKeyRef:
name: init-config
key: JVMOPTIONS
- name: PARAMS
valueFrom:
configMapKeyRef:
name: init-config
key: PARAMS
volumeMounts:
- mountPath: /root/powerjob/server
name: powerjob-server-data
- mountPath: /root/.m2
name: m2
volumes:
- name: powerjob-server-data
persistentVolumeClaim:
claimName: powerjob-server-data
- name: m2
persistentVolumeClaim:
claimName: m2
# initContainers表示以下容器是需要被先初始化的(就是上面说的Init C)
# 注意,不管是readinessProbe还是livenessProbe还是Init C还是start还是stop都是可以绑在一个容器下配合使用的,这里是为了演示方便,才单独分开写
initContainers:
- name: init-mysql
image: xxx
command: ['sh', '-C', 'mysql -u xxx -p xxx -h xxx -P xxx < app/config/init.sql']
volumeMounts:
- name: mysql-initdb
mountPath: app/config
volumes:
- name: mysql-initdb
configMap:
name: init-config
items:
- key: initdb.sql
path: init.sql
---
apiVersion: v1
kind: Service
metadata:
name: powerjob-server
namespace: xxx
spec:
type: xxx
selector:
app: powerjob-server
# release: xxx
# env: xxx
ports:
- name: xxx1
port: 7700
targetPort: 7700
- name: xxx2
port: 10086
targetPort: 10086