对于MySQL的一些额外的补充
使用yum安装MySQL8
先使用yum list installed |grep mysql* 来查看是否有残留mysql
如果有使用yum remove mysql* 删除所有残留mysql
接下来删除 /var/lib/mysql下的所有残留文件
接下来依次执行命令:
wget -i -c https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm
yum -y install mysql80-community-release-el7-3.noarch.rpm
yum -y install mysql-community-server
systemctl start mysqld.service
systemctl status mysqld.service
不出意外的话这个时候应该就好了
查看systemctl中所有enable的项,查看mysql服务是否开机自启:
systemctl list-unit-files|grep enabled
接下来修改密码:
运行命令查看初始化的时候自动生成的密码:
grep "password" /var/log/mysqld.log
在靠近最后一行的位置我们会找到生成的密码:
...A temporary password is generated for root@localhost: xxx
得到密码之后我们就能登录MySQL了
首次登录啥都不能干,只能重置密码,这个时候可能会遇到设置密码过于简单系统无法通过的情况,暂时没办法,只能先设置一个难度级别高的密码
设置完密码之后就可以去修改设置密码的级别了
执行命令:
show variables like 'validate_password%';
我们会看到对于密码设置的诸多限制,有:
- validate_password_length
- validate_password_number_count
- validate_password.policy
- validate_password.check_user_name
- validate_password_mixed_case_count
- validate_password_special_char_count
- …
密码的长度是由validate_password_length决定的,而validate_password_length的计算公式是:
validate_password_length = validate_password_number_count + validate_password_special_char_count + (2 * validate_password_mixed_case_count)
这里我们举个例子改两个参数:
set global validate_password.policy=0;
set global validate_password.length=1;
现在就能将刚才设置的很难的密码改成简单的了:
alter user 'root'@'localhost' identified by 'xxx';
最后一步,设置允许远程连接
grant all privileges on *.* to 'root'@'%' identified by 'password'; // 这里可能会提示一个语法错误。有人说是mysql8的分配权限不能带密码隐式创建账号了,要先创建账号再设置权限。也有的说8.0.11之后移除了grant 添加用户的功能。
那我们试试下面这种方法:
创建用户:CREATE USER 'root'@'%' IDENTIFIED BY 'xxx';
允许远程连接:GRANT ALL ON *.* TO 'root'@'%';
经过测试,使用 update user set host = '%' where user = 'root'; 也可以修改
如果使用客户端连接提示了plugin caching_sha2_password错误,这是因为MySQL8.0的密码策略默认为caching_sha2_password
使用命令修改策略:
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY 'xxx';
最后查看我们创建或修改的用户:
select host, user, plugin from user;
然后关闭防火墙,测试连接成功!
COLLATE
CREATE TABLE `table1` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`field1` text COLLATE utf8_unicode_ci NOT NULL COMMENT '字段1',
`field2` varchar(128) COLLATE utf8_unicode_ci NOT NULL DEFAULT '' COMMENT '字段2',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8_unicode_ci;
COLLATE的作用
所谓utf8_unicode_ci,其实是用来排序的规则。对于mysql中那些字符类型的列,如VARCHAR,CHAR,TEXT类型的列,都需要有一个COLLATE类型来告知mysql如何对该列进行排序和比较。简而言之,COLLATE会影响到ORDER BY语句的顺序,会影响到WHERE条件中大于小于号筛选出来的结果,会影响DISTINCT、GROUP BY、HAVING语句的查询结果。另外,mysql建索引的时候,如果索引列是字符类型,也会影响索引创建,只不过这种影响我们感知不到。总之,凡是涉及到字符类型比较或排序的地方,都会和COLLATE有关。
各种COLLATE的区别
COLLATE通常是和数据编码(CHARSET)相关的,一般来说每种CHARSET都有多种它所支持的COLLATE,并且每种CHARSET都指定一种COLLATE为默认值。例如Latin1编码的默认COLLATE为latin1_swedish_ci,GBK编码的默认COLLATE为gbk_chinese_ci,utf8mb4编码的默认值为utf8mb4_general_ci。
这里顺便讲个题外话,mysql中有utf8和utf8mb4两种编码,在mysql中请大家忘记utf8,永远使用utf8mb4。这是mysql的一个遗留问题,mysql中的utf8最多只能支持3bytes长度的字符编码,对于一些需要占据4bytes的文字,mysql的utf8就不支持了,要使用utf8mb4才行。
很多COLLATE都带有_ci字样,这是Case Insensitive的缩写,即大小写无关,也就是说"A"和"a"在排序和比较的时候是一视同仁的。selection * from table1 where field1=“a"同样可以把field1为"A"的值选出来。与此同时,对于那些_cs后缀的COLLATE,则是Case Sensitive,即大小写敏感的。
使用SHOW COLLATION查看MySQL支持的所有COLLATE
在mysql中使用show collation指令可以查看到mysql所支持的所有COLLATE。以utf8mb4为例,该编码所支持的所有COLLATE如下图所示:
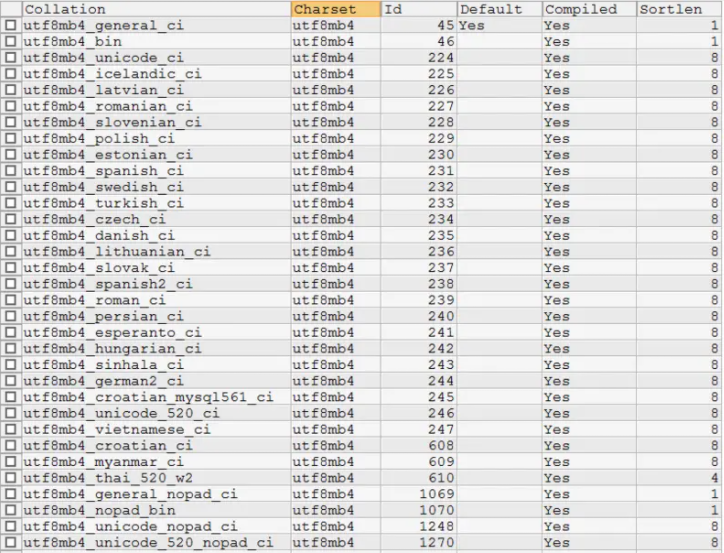
图中我们能看到很多国家的语言自己的排序规则。在国内比较常用的是utf8mb4_general_ci(默认)、utf8mb4_unicode_ci、utf8mb4_bin这三个。我们来探究一下这三个的区别:
首先utf8mb4_bin的比较方法其实就是直接将所有字符看作二进制串,然后从最高位往最低位比对。所以很显然它是区分大小写的。
而utf8mb4_unicode_ci和utf8mb4_general_ci对于中文和英文来说,其实是没有任何区别的。对于我们开发的国内使用的系统来说,随便选哪个都行。只是对于某些西方国家的字母来说,utf8mb4_unicode_ci会比utf8mb4_general_ci更符合他们的语言习惯一些,general是mysql一个比较老的标准了。例如,德语字母“ß”,在utf8mb4_unicode_ci中是等价于"ss"两个字母的(这是符合德国人习惯的做法),而在utf8mb4_general_ci中,它却和字母“s”等价。不过,这两种编码的那些微小的区别,对于正常的开发来说,很难感知到。本身我们也很少直接用文字字段去排序,退一步说,即使这个字母排错了一两个,真的能给系统带来灾难性后果么?从网上找的各种帖子讨论来说,更多人推荐使用utf8mb4_unicode_ci,但是对于使用了默认值的系统,也并没有非常排斥,并不认为有什么大问题。
结论:推荐使用utf8mb4_unicode_ci,对于已经用了utf8mb4_general_ci的系统,也没有必要花时间改造。
另外需要注意的一点是,从mysql 8.0开始,mysql默认的CHARSET已经不再是Latin1了,改为了utf8mb4,并且默认的COLLATE也改为了utf8mb4_0900_ai_ci。utf8mb4_0900_ai_ci大体上就是unicode的进一步细分,0900指代unicode比较算法的编号( Unicode Collation Algorithm version),ai表示accent insensitive(发音无关),例如e, è, é, ê 和 ë是一视同仁的。
COLLATE设置级别及其优先级
设置COLLATE可以在实例级别、库级别、表级别、列级别、以及SQL指定。实例级别的COLLATE设置就是mysql配置文件或启动指令中的collation_connection系统变量。
库级别设置COLLATE的语句如下:
CREATE DATABASE <db_name> DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
如果库级别没有设置CHARSET和COLLATE,则库级别默认的CHARSET和COLLATE使用实例级别的设置。在mysql8.0以下版本中,你如果什么都不修改,默认的CHARSET是Latin1,默认的COLLATE是latin1_swedish_ci。从mysql8.0开始,默认的CHARSET已经改为了utf8mb4,默认的COLLATE改为了utf8mb4_0900_ai_ci。
表级别的COLLATE设置,则是在CREATE TABLE的时候加上相关设置语句,例如:
CREATE TABLE (
...
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
如果表级别没有设置CHARSET和COLLATE,则表级别会继承库级别的CHARSET与COLLATE。
列级别的设置,则在CREATE TABLE中声明列的时候指定,例如:
CREATE TABLE (
`field1` VARCHAR(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT ''
)...
如果列级别没有设置CHARSET和COLATE,则列级别会继承表级别的CHARSET与COLLATE。
最后,你也可以在写SQL查询的时候显示声明COLLATE来覆盖任何库表列的COLLATE设置,不太常用,了解即可:
SELECT DISTINCT field1 COLLATE utf8mb4_general_ci FROM table1;
SELECT field1, field2 FROM table1 ORDER BY field1 COLLATE utf8mb4_unicode_ci;
如果全都显示设置了,那么优先级顺序是 :
SQL语句 > 列级别设置 > 表级别设置 > 库级别设置 > 实例级别设置
也就是说列上所指定的COLLATE可以覆盖表上指定的COLLATE,表上指定的COLLATE可以覆盖库级别的COLLATE。如果没有指定,则继承下一级的设置。即列上面没有指定COLLATE,则该列的COLLATE和表上设置的一样。
注意:在系统设计中,我们还是要尽量避免让系统严重依赖中文字段的排序结果,在mysql的查询中也应该尽量避免使用中文做查询条件。
CHECK检查表的状况(查看表是否损坏)
CHECK TABLE t1;
返回结果:
| Table表名称 | Op进行修复 | Msg_type状态、错误、信息或警告之一 | Msg_text消息 |
|---|---|---|---|
| db1.t1 | check | status | OK |
ANALYZE关键字
MySQL 的Optimizer(优化元件)在优化SQL语句时,首先需要收集一些相关信息,其中就包括表的cardinality(可以翻译为“散列程度”),它表示某个索引对应的列包含多少个不同的值——如果cardinality大大少于数据的实际散列程度,那么索引就基本失效了。
我们可以使用SHOW INDEX语句来查看索引的散列程度:
SHOW INDEX FROM PLAYERS;
假设得到结果:
| TABLE | KEY_NAME | COLUMN_NAME | CARDINALITY |
|---|---|---|---|
| PLAYERS | PRIMARY | PLAYERNO | 14 |
如果此时PLAYER表中不同的PLAYERNO数量远多于14,索引基本失效
通过ANALYZE TABLE语句来修复索引:
ANALYZE TABLE PLAYERS;
SHOW INDEX FROM PLAYERS;
假设得到结果:
| TABLE | KEY_NAME | COLUMN_NAME | CARDINALITY |
|---|---|---|---|
| PLAYERS | PRIMARY | PLAYERNO | 1000 |
此时索引已经修复,查询效率大大提高
需要注意的是,如果开启了binlog,那么ANALYZE TABLE的结果也会写入binlog,我们可以在ANALYZE和TABLE之间添加关键字LOCAL取消写入:
ANALYZE LOCAL TABLE tbl_name;
repair table修复表★
REPAIR [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name[,tbl_name] … [QUICK] [EXTENDED] [USE_FRM]
REPAIR TABLE用于修复被破坏的表。默认情况下,REPAIR TABLE与myisamchk –recovertbl_name具有相同的效果。REPAIR TABLE对MyISAM和ARCHIVE表起作用。
通常,您基本上不必运行此语句。但是,如果灾难发生,REPAIR TABLE很有可能从MyISAM表中找回所有数据。如果您的表经常被破坏,您应该尽力找到原因,以避免使用REPAIR TABLE。
本语句会返回表:
| Table表名称 | Op进行修复 | Msg_type状态、错误、信息或警告之一 | Msg_text消息 |
|---|---|---|---|
| .. | .. | .. | .. |
对于每个被修复的表,REPAIR TABLE语句会产生多行的信息。上一行含有一个Msg_type状态值。Msg_test通常应为OK。如果您没有得到OK,您应该尝试使用myisamchk –safe-recover修复表,因为REPAIR TABLE尚不会执行所有的myisamchk选项。
QUICK、EXTENDED、USE_FRM三个参数的区别:
-
QUICK
如果给定了QUICK,则REPAIR TABLE会尝试只修复索引树。这种类型的修复与使用myisamchk –recover –quick相似。
-
EXTENDED
如果您使用EXTENDED,则MySQL会一行一行地创建索引行,代替使用分类一次创建一个索引。这种类型的修复与使用myisamchk –safe-recover相似。
-
USE_FRM
对于REPAIR TABLE,还有一种USE_FRM模式可以利用。如果.MYI索引文件缺失或标题被破坏,则使用此模式。在这种模式下,MySQL可以使用来自.frm文件重新创建.MYI文件。这种修复不能使用myisamchk来完成。注释:只能在您不能使用常规REPAIR模式是,才能使用此模式。.MYI标题包含重要的表元数据(特别是,当前的AUTO_INCREMENT值和Delete链接)。这些元数据在REPAIR…USE_FRM中丢失。如果表被压缩,则不能使用USE_FRM。因为本信息也存储在.MYI文件中。
NO_WRITE_TO_BINLOG(别名LOCAL)的作用:
REPAIR TABLE语句被写入二进制日志中,除非使用了自选的NO_WRITE_TO_BINLOG关键词(或其别名LOCAL)。
警告:如果在REPAIR TABLE运行过程中,服务器停机,则在重新启动之后,在执行其它操作之前,您必须立刻对表再执行一个REPAIR TABLE语句。(通过制作一个备份来启动是一个好办法。)再最不利情况下,您可以有一个新的干净的索引文件,不含有关数据文件的信息。然后,您执行的下一个操作会覆盖数据文件。这很少发生,但是是有可能的。
mysql repair table-Can’t open file: ‘[Table]mytable.MYI’.
也许很多人遇到过类似Can’t open file: ‘[Table]mytable.MYI’ 这样的错误信息,却不知道怎么解决他,下面我们做个介绍:
多数情况下,数据库被破坏只是指索引文件受到了破坏,真正的数据被破坏掉的情况非常少。大多数形式的数据库破坏的的修复相当简单。
下面讲的方法只对MyISAM格式的表有效。其他类型的损坏需要从备份中恢复。
-
REPAIR TABLE SQL statement(mysql服务必须处于运行状态)。
语法:repair table 表名 [选项]
选项如下: QUICK 用在数据表还没被修改的情况下,速度最快 EXTENDED 试图去恢复每个数据行,会产生一些垃圾数据行,万般无奈的情况下用 USE_FRM 用在.MYI文件丢失或者头部受到破坏的情况下。利用.frm的定义来重建索引
多数情况下,简单得用”repair table tablename”不加选项就可以搞定问题。但是当.MYI文件丢失或者头部受到破坏时,这样的方式不管用,例如:
Table Op Msg_type Msg_text sports_results.mytable repair error Can’t open file: ‘[Table]mytable.MYI’(errno:2) 修复失败的原因是索引文件丢失或者其头部遭到了破坏,为了利用相关定义文件来修复,需要用USE_FRM选项:
REPAIR TABLE mytable USE_FRM;操作之后我们可以看到:
Table Op Msg_type Msg_text sports_results.mytable repair warning Number of rows changed from 0 to 2 sports_results.mytable repair status OK 我们可以看到Msg_test表项的输出信息”ok”,表名已经成功修复受损表。
-
命令mysqlcheck(mysql服务可以处于运行状态)。
语法:mysqlcheck -r 数据库名 表名 -uuser -ppass Command: %mysqlcheck -r sports_results mytable -uuser -ppwd Result: sports_results.mytable OK 利用mysqlcheck可以一次性修复多个表。只要在数据库名后列出相应表名即可(用空格隔开)。或者数据库名后不加表名,将会修复数据库中的所有表,例如: Command: %mysqlcheck -r sports_results mytable events -uuser -ppwd Result: sports_results.mytable OK Result: sports_results.events OK Command: %mysqlcheck -r sports_results -uuser -ppwd Result: sports_results.mytable OK Result: sports_results.events OK -
命令myisamchk(必须停掉mysql服务,或者所操作的表处于不活动状态)。
用这种方式时,mysql服务必须停掉,或者所操作的表处于不活动状态(选项skip-external-locking没被使用)。记着一定要在相关.MYI文件的路径下或者自己定义其路径。 语法:myisamchk [选项] [表名] 下面是其选项和描述 –backup, -B 在进行修复前作相关表得备份 –correct-checksum 纠正校验和 –data-file-length=#, -D # 重建表时,指定数据文件得最大长度 –extend-check, -e 试图去恢复每个数据行,会产生一些垃圾数据行,万般无奈的情况下用 –force, -f 当遇到文件名相同的.TMD文件时,将其覆盖掉。 keys-used=#, -k # 指定所用的keys可加快处理速度,每个二进制位代表一个key.第一个key为0 –recover, -r 最常用的选项,大多数破坏都可以通过它来修复。 如果你的内存足够大,可以增大参数sort_buffer_size的值来加快恢复的速度。但是遇到唯一键由于破坏而不唯一的表时,这种方式不管用。 –safe-recover -o 最彻底的修复方式,但是比-r方式慢,一般在-r修复失败后才使用。 这种方式读出所有的行,并以行为基础来重建索引。它的硬盘空间需求比-r方式稍微小一点,因为它没创建分类缓存。你可以增加key_buffer_size的值来加快修复的速度。 –sort-recover, -n mysql用它类分类索引,尽管结果是临时文件会非常大 –character-sets-dir=… 包含字符集设置的目录 –set-character-set=name 为索引定义一个新的字符集 –tmpdir=path, -t 如果你不想用环境变量TMPDIR的值的话,可以自定义临时文件的存放位置 –quick, -q 最快的修复方式,当数据文件没有被修改时用,当存在多键时,第二个-q将会修改 数据文件 –unpack, -u 解开被myisampack打包的文件 myisamchk应用的一个例子 % myisamchk -r mytable recovering (with keycache) MyISAM-table ‘mytable.MYI’ Data records: 0
在修复表的时候,最好先作一下备份。所以你需要两倍于原始表大小的硬盘空间。请确保在进行修复前你的硬盘空间还没有用完。
InnoDB数据损坏修复
InnoDB是带有事务的存储引擎,并且其内部机制会自动修复大部分数据损坏错误,它会在服务器启动时进行修复。 不过,有时候数据损坏得很严重并且InnoDB无法在没有用户交互的情况下完成修复,在这种情况下,有–innodb_force_recovery启动选项(当然也可以在/etc/my.cnf中配置innodb_force_recovery)。该选项可以设置0~6(0 不强制修复 1是最低级别 6最高级别):
- 1:忽略检查到的corrupt页
- 2:阻止主线程的运行,如主线程需要执行full purge操作,则会导致crash
- 3:不执行事务回滚操作
- 4:不执行插入缓存的合并操作
- 5:不查看重做日志,InnoDB存储引擎会将未提交的事务视为已提交
- 6:不执行前滚的操作
如果发生损坏,可以从1开始尝试修复,直到可以启动服务器并且可以访问有问题的表为止。 启动后使用select into outfile将表转储到文件中,然后使用drop和create命令重新创建表,最后用–innodb_force_recovery=0重新启动服务器,然后加载文件数据。 当需要在–innodb_force_recovery选项是正数的情况下修复数据库时,错误日志通常会有明确的提示信息。
当设置innodb_force_recovery大于0之后,可以对表进行select、create、drop操作,但insert、update、delete这类操作是不允许的。所以在最后表修复完成之后,不要忘了把innodb_force_recovery设置为0或注释掉
如果仍不能启动,可以使用备份来还原数据库,推荐先物理备份下/var/lib/mysql,之后可以试着删除ib_logfile0、ib_logfile1和ibdata1文件,然后启动mysql服务来还原
数据备份
参考:https://www.cnblogs.com/gered/p/10410978.html(MySQL备份(数据导出与导入))、https://blog.csdn.net/u012436346/article/details/86570902(使用mysqldump导入与导出数据)
注意,mysqldump的时候可能会报错:
mysqldump: Couldn't execute 'SELECT COLUMN_NAME,JSON_EXTRACT(HISTOGRAM, '$."number-of-buckets-specified"')ROM information_schema.COLUMN_STATISTICS WHERE SCHEMA_NAME = 'store' AND TABLE_NAME = 't_address';': Unknown table 'column_statistics' in information_schema (1109)
原因是早期版本MySQL的information_schema数据库中没有名为COLUMN_STATISTICS的数据表,而新版的mysqldump对于--column-statistics参数默认是启动的(--column-statistics=1),我们可以通过--column-statistics=0来禁用他:
$ mysqldump --column-statistics=0 -h x.x.x.x -P xxxx -u xxx -p xxx > xxx.sql
OPTIMIZE关键字
MySQL执行命令delete语句时,如果包括where条件,并不会真正的把数据从表中删除,而是将数据转换成了碎片,通过下面的命令可以查看表中的碎片数量和索引等信息:
show table status like tbl_name;

查询结果中:
Index_length 代表索引的数量
Data_free 代表碎片数量
然后执行下面命令进行优化整理:
OPTIMIZE TABLE tbl_name;
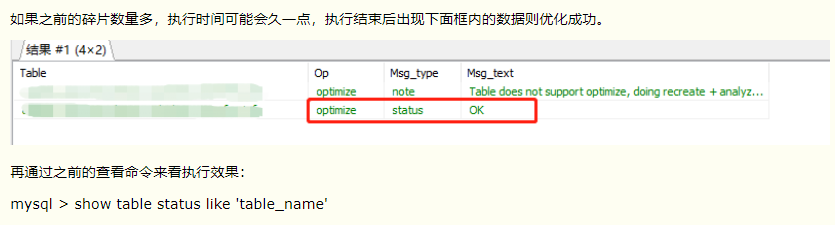
需要注意的是,如果开启了binlog,那么OPTIMIZE TABLE的结果也会写入binlog,我们可以在OPTIMIZE和TABLE之间添加关键字LOCAL取消写入:
OPTIMIZE LOCAL TABLE tbl_name;
OPTIMIZE TABLE只对MyISAM, BDB和InnoDB表起作用。
注意:在OPTIMIZE TABLE运行过程中,MySQL会锁定表。
DUPLICATE关键字
在日常业务开发中经常有这样一个场景,首先创建一条记录,然后插入到数据库,如果数据库已经存在同一主键的记录,执行update操作;否则,执行insert操作。这个操作可以在业务层做,也可以在数据库层面做。业务层一般做法是先查询,如果不存在就插入,如果存在就更新;但是查询和插入不是原子性操作,在并发量比较高的时候,可能两个线程都查询不到某个记录,所以会执行两次插入,其中一条必然会因为唯一性约束冲突而失败。数据库层mysql中INSERT … ON DUPLICATE KEY UPDATE就可以做这个事情,并且是原子性操作。
INSERT … ON DUPLICATE KEY UPDATE命令
-
单条记录下使用
INSERT INTO t1 (a,b,c) VALUES (1,2,3) ON DUPLICATE KEY UPDATE c = c + 1;如上sql假如t1表的主键或者UNIQUE 索引是a,那么当执行sql的时候,如果数据库里面已经存在a=1的记录则更新这条记录的c字段的值为原来值+1,然后返回值为2;如果不存在则插入记录a=1,b=2,c=3,然后返回值为1。
**如果insert语句中同时出现UNIQUE索引和PRIMARY KEY,则以后者为准。**ON DUPLICATE KEY UPDATE后面可以放多个字段,用英文逗号分割。
-
多条记录下使用
INSERT INTO t1 (a,b,c) VALUES (1,2,3),(4,5,6) ON DUPLICATE KEY UPDATE c = VALUES(c), b = VALUES(b); -- VALUES() 是针对同时插入多条记录时获取正确的待设置值 --
注意:case when、duplicate key update、for循环更新或插入数据时,duplicate key update是最快的,但是一般大公司都禁用,公司一般都禁止使用replace into和INSERT INTO … ON DUPLICATE KEY UPDATE,这种sql有可能会造成数据丢失和主从上表的自增id值不一致。而且用这个更新时,记得一定要加上id,而且values()括号里面放的是数据库字段,不是java对象的属性字段:

DELAYED关键字
延迟插入操作
DELAYED调节符应用于INSERT和REPLACE语句。当DELAYED插入操作到达的时候i,服务器把数据行放入一个队列中,并立即给客户端返回一个状态信息,这样客户端就可以在数据表被真正地插入记录之前继续进行着操作了。如果读取者从该数据表中读取数据,队列中的数据就会被保持着,直到没有读取者为止。接着服务器开始插入延迟数据行(delayed-row)队列中的数据行。在插入操作的同时,服务器还要检查是否有新的读取请求到达和等待。如果有,延迟数据行队列就被挂起,允许读取者继续操作。当没有读取者的时候,服务器再次开始插入延迟的数据行。这个过程一直进行,直到队列空了为止。
下面几点要注意的事项:
- INSERT DELAYED应该仅用于指定值清单的INSERT语句。服务器忽略用于INSERT DELAYED…SELECT语句的DELAYED
- 服务器忽略用于INSERT DELAYED…ON DUPLICATE UPDATE语句的DELAYED
- 因为在行被插入前,语句立刻返回,所以您不能使用LAST_INSETT_ID()来获取AUTO_INCREMENT值。AUTO_INCREMENT值可能由语句生成。
- 对于SELECT语句,DELAYED行不可见,直到这些行确实被插入了为止。
- DELAYED在从属复制服务器中被忽略了,因为DELAYED不会在从属服务器中产生与主服务器不一样的数据。注意,目前在队列中的各行只保存在存储器中,直到它们被插入到表中为止。这意味着,如果你强行终止了mysql或者如果mysql意外停止,则所有没有写入磁盘的行都会丢失。
CACHE INDEX语句
语法:
CACHE INDEX {
tbl_index_list [, tbl_index_list] ...
| tbl_name PARTITION (partition_list)
}
IN key_cache_name
-- tbl_index_list: tbl_name [{INDEX|KEY} (index_name [, index_name] ...)] --
-- partition_list: {partition_name[, partition_name] ... | ALL} --
CACHE INDEX语句将表索引分配给特定的键缓存。它只适用于MyISAM表,包括分区的MyISAM表。分配索引后,如果需要,可以将它们预加载到缓存中,并将索引加载到缓存中。 以下语句将表t1、t2和t3中的索引分配给名为hot_cache的密钥缓存:
CACHE INDEX t1, t2, t3 IN hot_cache;
CACHE INDEX的语法使您可以指定仅将表中的特定索引分配给高速缓存。但是,该实现将表的所有索引分配给高速缓存,因此,除了表名外,没有其他必要指定任何内容。
CACHE INDEX可以通过使用参数设置语句或在服务器参数设置中设置其大小来创建语句中 引用的键高速缓存。例如:
SET GLOBAL keycache1.key_buffer_size=128*1024;
关键高速缓存参数作为结构化系统变量的成员进行访问。 在为其分配索引之前,键高速缓存必须存在,否则会发生错误:
CACHE INDEX t1 IN non_existent_cache;
-- ERROR 1284 (HY000): Unknown key cache 'non_existent_cache' --
默认情况下,表索引分配给服务器启动时创建的主(默认)键高速缓存。销毁键高速缓存时,分配给它的所有索引都将重新分配给默认键高速缓存。 索引分配会全局影响服务器:如果一个客户端将索引分配给给定的缓存,则该缓存将用于涉及该索引的所有查询,无论哪个客户端发出查询。 CACHE INDEX支持分区MyISAM表。您可以将一个,多个或所有分区的一个或多个索引分配给给定的键高速缓存。例如,您可以执行以下操作:
CREATE TABLE pt (c1 INT, c2 VARCHAR(50), INDEX i(c1))
ENGINE=MyISAM
PARTITION BY HASH(c1)
PARTITIONS 4;
SET GLOBAL kc_fast.key_buffer_size = 128 1024;
SET GLOBAL kc_slow.key_buffer_size = 128 1024;
CACHE INDEX pt PARTITION (p0) IN kc_fast;
CACHE INDEX pt PARTITION (p1, p3) IN kc_slow;
上一组语句执行以下操作:
创建一个包含4个分区的分区表;这些分区会自动命名为p0,…,p3; 该表的索引名为 icolumn c1。
创建两个名为kc_fast和的 密钥缓存kc_slow
受让人为分区的索引p0的 kc_fast键缓存和用于分区的索引p1和p3 到kc_slow键缓存; 其余分区的索引(p2)使用服务器的默认键缓存。
如果希望将表中所有分区的索引分配给pt名为的单个键高速缓存 kc_all,则可以使用以下两个语句之一:
CACHE INDEX pt PARTITION (ALL) IN kc_all;
CACHE INDEX pt IN kc_all;
上面两个语句是等效的,发出其中一个具有完全相同的效果。换句话说,如果您希望将分区表的所有分区的索引分配给同一键高速缓存,则该PARTITION (ALL)子句是可选的。
在将多个分区的索引分配给键高速缓存时,这些分区不必是连续的,并且您无需以任何特定顺序列出其名称。未明确分配给键高速缓存的任何分区的索引将自动使用服务器默认键高速缓存。
分区MyISAM表还支持索引预加载 。
LOAD INDEX INTO CACHE语句
语法:
LOAD INDEX INTO CACHE{
tbl_index_list [, tbl_index_list] ...
| tbl_name PARTITION (partition_list)
}
-- tbl_index_list:
-- tbl_name
-- [PARTITION (partition_list)]
-- [{INDEX|KEY} (index_name[, index_name] ...)]
-- [IGNORE LEAVES]
-- partition_list: {
-- partition_name[, partition_name] ...
-- | ALL
-- }
LOAD INDEX INTO CACHE语句将表索引预加载到由显式CACHE INDEX语句为其分配的键高速缓存中,否则预加载 到默认键高速缓存中。 LOAD INDEX INTO CACHE仅适用于MyISAM 表,包括分区MyISAM表。此外,分区表上的索引可以预载一个,几个或所有分区。
所述IGNORE LEAVES改性剂导致要预装只为索引的非叶结点的块。
IGNORE LEAVES分区MyISAM表也受支持。
以下语句为表t1和的索引预加载节点(索引块)t2:
LOAD INDEX INTO CACHE t1, t2 IGNORE LEAVES;
该语句从中预加载所有索引块 t1。它仅从中预加载非叶节点的块t2。
的语法LOAD INDEX INTO CACHE使您可以指定仅应预加载表中的特定索引。但是,该实现将表的所有索引都预加载到缓存中,因此,除了表名外,没有其他必要指定其他内容。
可以在分区MyISAM表的特定分区上预加载索引。例如,在以下2条语句中,第一条预加载已分区表pt的分区p0的索引,而第二条预加载同一表的分区p1和p3的索引:
LOAD INDEX INTO CACHE pt PARTITION (p0);
LOAD INDEX INTO CACHE pt PARTITION (p1, p3);
要预加载table中所有分区的索引 pt,可以使用以下两个语句之一:
LOAD INDEX INTO CACHE pt PARTITION (ALL);
LOAD INDEX INTO CACHE pt;
上面两句是等效的。换句话说,如果您希望为分区表的所有分区预加载索引,则该 PARTITION (ALL)子句是可选的。
当预加载多个分区的索引时,这些分区不必是连续的,并且您无需以任何特定顺序列出其名称。
LOAD INDEX INTO CACHE … IGNORE LEAVES失败,除非表中的所有索引具有相同的块大小。要确定表的索引块大小,请使用myisamchk -dv并检查Blocksize列。
IGNORE关键字
MySQL提供了ignore用来避免数据的重复插入,若有导致unique key冲突的记录,则该条记录不会被插入到数据库中
举例:
INSERT IGNORE INTO `tbl_name` (`email`, `phone`, `user_id`) VALUES ('test9@163.com', '99999', '9999');
-- 如果有重复记录就会忽略,执行后返回数字0 --
还有个应用是复制表的时候避免重复记录:
INSERT IGNORE INTO `tbl_name` (`col`) SELECT `col` FROM `tbl_name2`;
SELECT … FOR UPDATE使用方法
作用:
select for update是为了在查询时,避免其他用户以该表进行插入,修改或删除等操作,造成表的不一致性
举例子:
select * from t for update; -- 会等待行锁释放之后,返回查询结果
select * from t for update nowait; -- 不等待行锁释放,提示锁冲突,不返回结果
select * from t for update wait 5; -- 等待5秒,若行锁仍未释放,则提示锁冲突,不返回结果
select * from t for update skip locked; -- 查询返回查询结果,但忽略有行锁的记录
select … for update语句的语法如下:
SELECT ... FOR UPDATE [OF column_list][WAIT n|NOWAIT][SKIP LOCKED];
-- 其中:
-- OF子句用于指定即将更新的列,即锁定行上的特定列
-- WAIT子句指定等待其他用户释放锁的秒数,防止无限期的等待
-- 使用FOR UPDATE WAIT子句的优点如下:
-- 1、防止无限期地等待被锁定的行
-- 2、允许应用程序中对锁的等待时间进行更多的控制
-- 3、对于交互式应用程序非常有用,因为这些用户不能等待不确定
-- 4、若使用了skip locked,则可以越过锁定的行,不会报告由wait n引发的‘资源忙’异常报告
补充:
分成两类:加锁范围子句和加锁行为子句
**加锁范围子句:**在select … for update之后,可以使用of子句选择对select的特定数据表进行加锁操作。默认情况下,不使用of子句表示在select所有的数据表中加锁
**加锁行为子句:**当我们进行for update的操作时,与普通select存在很大不同。一般select是不需要考虑数据是否被锁定,最多根据多版本一致读的特性读取之前的版本。加入for update之后,Oracle就要求启动一个新事务,尝试对数据进行加锁。如果当前已经被加锁,默认的行为必然是block等待。使用nowait子句的作用就是避免进行等待,当发现请求加锁资源被锁定未释放的时候,直接报错返回。
在日常中,我们对for update的使用还是比较普遍的,特别是在如pl/sql developer中手工修改数据。此时只是觉得方便,而对for update真正的含义缺乏理解。
For update是Oracle提供的手工提高锁级别和范围的特例语句。Oracle的锁机制是目前各类型数据库锁机制中比较优秀的。所以,Oracle认为一般不需要用户和应用直接进行锁的控制和提升。甚至认为死锁这类锁相关问题的出现场景,大都与手工提升锁有关。
所以,Oracle并不推荐使用for update作为日常开发使用。而且,在平时开发和运维中,使用了for update却忘记提交,会引起很多锁表故障。 那么,什么时候需要使用for update?就是那些需要业务层面数据独占时,可以考虑使用for update。场景上,比如火车票订票,在屏幕上显示邮票,而真正进行出票时,需要重新确定一下这个数据没有被其他客户端修改。所以,在这个确认过程中,可以使用for update。这是统一的解决方案方案问题,需要前期有所准备。
筛选并查看变量
show variables where variable_name like 'wait%' and value='on';
查看已安装的插件
SHOW PLUGINS;
generated column
定义Generated column列的语法如下:
列名 类型 [GENERATED ALWAYS] AS (expr) [VIRTUAL | STORED] [NOT NULL | NULL] [UNIQUE [KEY]] [[PRIMARY] KEY] [COMMENT 'string']
- AS(expr)用于生成计算列值的表达式。
- VIRTUAL或STORED关键字表示是否存储计算列的值
- VIRTUAL:默认就是设置为VIRTUAL。不存储该列值,即MySQL只是将这一列的元信息保存在数据字典中,并不会将这一列数据持久化到磁盘上,而是当读取该行时,触发触发器对该列进行计算显示。InnoDB支持Virtual Generated Column。
- STORED:在添加或更新行时计算并存储列值。存储列需要存储空间,并且可以创建索引。所以相对于Virtual Column列需要更多的磁盘空间,与Virtual Column相比并没有优势。因此,MySQL 5.7中,不指定Generated Column的类型,默认是Virtual Column。
- 在表中允许Virtual Column和Stored Column的混合使用
- 提高效率:由于mysql在普通索引上加函数会造成索引失效,造成查询性能下降,Generated Column(函数索引)刚好可以解决这个问题,可以在Generated Column加上索引来提高效率
注意:还可以在generated column上建立索引以加快查找速度
计算列表达式的要求:
-
允许使用文本、内置函数和运算符,但不能使用返回值不确定的函数,比如NOW()。
-
不允许使用存储函数和用户定义函数。
-
不允许使用存储过程和函数参数。
-
不允许使用变量(系统变量、用户定义变量和存储程序的局部变量)。
-
不允许子查询。
-
计算列在定义时可以引用其他的计算列,但只能引用表定义中较早出现的列。
-
可以在计算列上创建索引,但不能在VIRTUAL类型的计算列上创建聚集索引。
mysql> create table t1(a int, b int , c int GENERATED ALWAYS AS (a / b), primary key(c)); ERROR 3106 (HY000): 'Defining a virtual generated column as primary key' is not supported for generated columns. mysql> create table t1(a int, b int , c int GENERATED ALWAYS AS (a / b) STORED, primary key(c)); Query OK, 0 rows affected (0.11 sec) -
不能在Virtual Generated Column上创建全文索引和空间索引
-
Virtual Generated Column不能作为外键
Generated Column上创建索引与Oracle的函数索引的区别
首先创建表:
CREATE TABLE t1 (first_name VARCHAR(10), last_name VARCHAR(10));
假设这时候需要建一个full_name的索引,在Oracle中,我们可以直接在创建索引的时候使用函数,如下所示:
alter table t1 add index full_name_idx(CONCAT(first_name,' ',last_name));
但是,上面这条语句在MySQL中就会报错。在MySQL中,我们可以先新建一个Generated Column,然后再在这个Generated Column上建索引,如下所示:
alter table t1 add column full_name VARCHAR(255) GENERATED ALWAYS AS (CONCAT(first_name,' ',last_name));
alter table t1 add index full_name_idx(full_name);
乍一看,MySQL需要在表上增加一列,才能够实现类似Oracle的函数索引,似乎代价会高很多。但是,我们在上面提过,对于Virtual Generated Column,MySQL只是将这一列的元信息保存在数据字典中,并不会将这一列数据持久化到磁盘上,因此,在MySQL的Virtual Generated Column上建立索引和Oracle的函数索引类似,并不需要更多的代价,只是使用方式有点不一样而已。
Binary类型
CREATE TABLE test_bin (
bin_id BINARY(16) NOT NULL
) Engine=InnoDB;
INSERT INTO test_bin(bin_id) VALUES(UNHEX(‘FA34E10293CB42848573A4E39937F479‘));
-- 或 --
INSERT INTO test_bin(bin_id) VALUES(x‘FA34E10293CB42848573A4E39937F479‘);
SELECT HEX(bin_id) AS bin_id FROM test_bin;
SELECT HEX(bin_id) AS bin_id FROM test_bin WHERE bin_id = UNHEX(‘FA34E10293CB42848573A4E39937F479‘);
SELECT HEX(bin_id) AS bin_id FROM test_bin WHERE bin_id = x‘FA34E10293CB42848573A4E39937F479‘;
Binary妙用:
假设表t_user有字段name类型是varchar,那么要求根据name来做筛选
where自居的字符串比较是不区分大小写的,但是可以使用binary关键字设定where子句区分大小写:
select * from t_user where binary name = 'Zhangsan'; -- 搜不到东西 --
select * from t_user where name = 'Zhangsan'; -- 可以搜到name为zhangsan的 --
unsigned类型
-- 其实就跟c语言中的unsigned差不多 --
CREATE TABLE t(
a INT UNSIGNED,
b INT UNSIGNED
)ENGINE=INNODB;
ZEROFILL
zerofill 默认是unsigned
CREATE TABLE t(
a INT(4) ZEROFILL,
)ENGINE=INNODB;
-- 向表t插入a为10的一条数据
-- 执行select语句查询a结果为0010
COMMENT
用于对字段进行说明
CREATE TABLE `mytest`(
`text` varchar(255) DEFAULT '' COMMENT '内容'
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
REPLACE INTO
有这样一种场景:如果没有则插入,如果有则更新。
我们当然可以用insert、update、select来做到这点,但是效率太低,此时就可以使用replace [into],into可以省略。
-
语法1:
REPLACE [INTO] tbl_name(col_name1, col_name2, ...) VALUES (...); -
语法2:
REPLACE [INTO] tbl_name(col_name1, col_name2, ...) SELECT ...;replace select 的用法类似于insert select,这种方法并不一定要求列名匹配,事实上,MYSQL甚至不关心SELECT返回的列名,它需要的是列的位置
例子1:
REPLACE [INTO] tbl1(name, title, mood) SELECT rname, rtitle, rmood from tbl2; -- 意思是将tbl2中的所有数据导入到tbl1中 --例子2:
REPLACE [INTO] tbl1(id, update_time) SELECT 1, now(); -
语法3:
REPLACE [INTO] tbl1 SET col_name=value, ...;replace set 的用法类似于update set ,如果使用一个例如“SET col_name = col_name + 1”的赋值,则对于右侧的列名称的引用会被作为DEFAULT(col_name)处理。因此,该赋值相当于“SET col_name = DEFAULT(col_name) + 1”
replace into 跟insert功能类似,不同点在于:replace into 首先尝试插入数据到表中,如果发现表中已经有此行数据**(根据主键或者唯一索引判断)**则先删除此行数据,然后插入新的数据,否则,直接插入新的数据。
要注意的是,插入数据的表必须要有主键或者唯一索引,否则,replace into 会直接插入数据,这将导致表中出现重复的数据。
在实际使用中语法1和语法2会用的多一些。虽然replace into中的into可以省略,但是最好还是加上,因为这样意思更加直观
另外,对于那些没有给予值的列,MySQL将自动为这些列赋上默认值。
内连接、外连接
select * from (a1.name,a2.name from b left join a as a1 on b.id = a1.id)
left join a as a2 on b.hid = a2.id;
select * from 表1 as x1 inner join 表2 as x2 on x1.'id'=x2.'hyuid' and
'hyuid'=1600702113;
select * from (select goods_id,cat_id,goods_name from goods order by cat_id
asc,goods_id desc) as temp group by cat_id;
外键约束(on delete和on update)的使用
外键约束(On Delete和On Update)都有Restrict,No Action, Cascade,Set Null属性。
外键约束1–ON DELETE A.restrict(约束):当在父表(即外键的来源表)中删除对应记录时,首先检查该记录是否有对应外键,如果有则不允许删除。 B.no action:意思同restrict.即如果存在从数据,不允许删除主数据。 C.cascade(级联):当在父表(即外键的来源表)中删除对应记录时,首先检查该记录是否有对应外键,如果有则也删除外键在子表(即包含外键的表)中的记录。 D.set null:当在父表(即外键的来源表)中删除对应记录时,首先检查该记录是否有对应外键,如果有则设置子表中该外键值为null(不过这就要求该外键允许取null)
外键约束2–ON UPDATE A.restrict(约束):当在父表(即外键的来源表)中更新对应记录时,首先检查该记录是否有对应外键,如果有则不允许更新。 B.no action:意思同restrict. C.cascade(级联):当在父表(即外键的来源表)中更新对应记录时,首先检查该记录是否有对应外键,如果有则也更新外键在子表(即包含外键的表)中的记录。 D.set null:当在父表(即外键的来源表)中更新对应记录时,首先检查该记录是否有对应外键,如果有则设置子表中该外键值为null(不过这就要求该外键允许取null)。
注:NO ACTION和RESTRICT的区别:只有在及个别的情况下会导致区别,前者是在其他约束的动作之后执行,后者具有最高的优先权执行。
案例:
CREATE TABLE `filedb`.`tblfile` (
`FileID` int(10) unsigned NOT NULL AUTO_INCREMENT,
`FileOwner` varchar(50) DEFAULT NULL COMMENT '外键,引用用户表',
`FileName` varchar(200) NOT NULL COMMENT '文件原始名称',
`FilePath` varchar(200) NOT NULL COMMENT '文件存放路径',
`FileType` varchar(10) NOT NULL COMMENT '文件类型',
`FileSubject` varchar(100) NOT NULL COMMENT '文件标题',
`FileCreated` datetime DEFAULT '0000-00-00 00:00:00' COMMENT '创建时间',
PRIMARY KEY (`FileID`),
KEY `FK_tblfile_1` (`FileOwner`),
CONSTRAINT `FK_tblfile_1` FOREIGN KEY (`FileOwner`) REFERENCES `tbluser` (`UserID`) ON DELETE SET NULL ON UPDATE CASCADE
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
-- 那么如果我删除用户表中ST001对应记录时,则根据ON DELETE SET NULL规则,文件表中FileOwner应该被设置为null,动手尝试后也确实如此;如果我将用户表中ST001改为ST003,则根据ON UPDATE CASCADE规则,文件表中FileOwner应该连锁设置为ST003,也的确如此。
on delete和on update也可以作用于timestamp时间戳类型的字段
案例:
CREATE TABLE `mytest`(
`text` varchar(255) DEFAULT '' COMMENT '内容',
`created_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`updated_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间'
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
外键的使用对于减少数据库冗余性,以及保证数据完整性和一致性有很大作用。
另外注意,如果两张表之间存在外键关系,则MySQL不能直接删除表(Drop Table),而应该先删除外键,之后才可以删除。
外键约束以及建立索引( create index)
// 添加外键约束以及建立索引(底层B+树,提高效率)如下:
create table Three_student(
id int auto_increment
primary key,
s_name varchar(16) not null,
s_grade_id int not null,
constraint Three_student_s_grade_id_ffbb8485_fk_Three_grade_id
foreign key (s_grade_id) references Three_grade (id)
);
create INDEX Three_student_s_grade_id_ffbb8485_fk_Three_grade_id on Three_student(s_grade_id);
Mysql的CURRENT_TIMESTAMP
在创建时间字段的时候(比方说常见的created_at和updated_at)
创建一条数据记录的时候,我们可能会希望created_at和updated_at这两个字段能够自动创建
DEFAULT CURRENT_TIMESTAMP
表示当插入数据的时候,该字段默认值为当前时间
ON UPDATE CURRENT_TIMESTAMP
表示每次更新这条数据的时候,该字段都会更新成当前时间
这两个操作是MySQL数据库本身在维护的,所以可以根据这个特性来生成【创建时间】和【更新时间】两个字段,且不需要代码来维护
CREATE TABLE `mytest`(
`text` varchar(255) DEFAULT '' COMMENT '内容',
`created_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`updated_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间'
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
联合algorithm创建视图
create algorithm = merge view v
as
select 语句;
必要时使用algorithm可以用于提高效率;以上写法并不会建立临时表。
如果algorithm = temptable 则指定生成临时表
如果拿不准用什么,algorithm= undefined,让系统帮我们定
Ifnull|nullif|其他
-
表看成集合的话一行是一个元素
-
数据库实现量表的笛卡儿积:select * from 表1,表2;
-
可以直接写 select 2>1;或者select 2<1或者select ‘list’=null;
-
null的比较需要用特殊的运算符,遇到其他运算符一律返回null is null , is not null; 例如:select * from name where snum is not null;
-
在开发中,会员的信息优化往往是把频繁用到的信息,优先考虑效率,存储到一张表中,不常用的信息和比较占据空间的信息,优先考虑空间占用,存储到辅表中。
-
myisam\innodb\bdb utf8\gbk\latin1…
-
对于结果中的列如果想再筛选,用having
-
用myisam引擎时count()和count(1)没有区别。而用lnnodb引擎时,count()效率很低,因为他真的要去数一遍。
-
ifnull(‘aaa’,0)–>aaa; ifnull(null,0)–>0; ifnull('',0)–>'';
-
nullif(a,b) 判断a和b是否相等,相等返回1,不等返回null;
-
数据库设计(项目经理、架构师):触发器、事物、锁、索引优化、引擎优化、表的涉及、读写分离
-
数据库的管理者(DBA 知识):权限管理、数据备份、运行监控、性能监测
查看MySQL网络连接相关的变量属性与网络连接状态
查看mysql网络连接的变量属性:show variables like '%connection%';、show global variables like '%connection%';
查看mysql网络连接的状态:show status like '%connection%';、show global status like '%connection%';
索引
创建索引时,需要保证索引是应用在sql查询语句的条件(一般作为where子句的条件)。
实际上索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录。索引大大提高查询速度,但降低了更新表的速度。
在where条件中,对某列使用了函数,则此列的索引不发挥作用。
mysql在使用like查询的时候只有使用后面的%时,才会使用到索引。
创建索引
create index 索引名 on 表名(属性名(length));
-- 如果是char,varchar类型,length可以小于字段实际长度;如果是blob,text,必须指定length
alter table 表名 add index 索引名(列名);
创建表时添加索引
create table 表名(
id int not null,
uname varchar(16) not null,
index[索引名](uname(length))
);
删除索引
drop index[索引名] on 表名;
普通索引
# 待补充 2021 05 26
唯一索引
create unique index 索引名 on 表名(列名(length); -- 创建
alter table 表名 add unique index[索引名] (列名(length)); -- 修改
创建表时添加唯一索引
create table 表名(
id int not null,
uname varchar(16) not null,
unique index[索引名](uname(length))
);
有四种方式来添加数据表的索引
-- 1
ALTER TABLE tbl_name ADD PRIMARY KEY (column_list); -- 该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL。
-- 2
ALTER TABLE tbl_name ADD UNIQUE index_name (column_list); -- 这条语句创建索引的值必须是唯一的(除了NULL外,NULL可能会出现多次)。
-- 3
ALTER TABLE tbl_name ADD INDEX index_name (column_list); -- 添加普通索引,索引值可出现多次。
-- 4
ALTER TABLE tbl_name ADD FULLTEXT index_name (column_list); -- 该语句指定了索引为 FULLTEXT ,用于全文索引。
举个例子,比如你在为某商场做一个会员卡的系统。
这个系统有一个会员表
有下列字段:
会员编号 INT
会员姓名 VARCHAR(10)
会员身份证号码 VARCHAR(18)
会员电话 VARCHAR(10)
会员住址 VARCHAR(50)
会员备注信息 TEXT
那么这个 会员编号,作为主键,使用 PRIMARY
会员姓名 如果要建索引的话,那么就是普通的 INDEX
会员身份证号码 如果要建索引的话,那么可以选择 UNIQUE (唯一的,不允许重复)
会员备注信息 ,如果需要建索引的话,可以选择 FULLTEXT,全文搜索。
回表、索引下推
参考:https://zhuanlan.zhihu.com/p/401198674(在Mysql中,什么是回表,什么是覆盖索引,索引下推?)、https://blog.csdn.net/demored/article/details/123067992(MySQL回表、覆盖索引、前缀索引、索引下推详解)
全文索引
like + % 在文本比较少时是合适的,但是对于大量的文本数据检索,是不可想象的。全文索引在大量的数据面前,能比 like + % 快 N 倍,速度不是一个数量级,但是全文索引可能存在精度问题。
我们知道各种搜索引擎,他们的索引对象是超大量的数据,并且通常其背后都不是关系型数据库,不过全文索引的基本原理跟他们差不多。
注意:只有字段的数据类型为 char、varchar、text 及其系列才可以建全文索引。
版本支持
- MySQL 5.6 以前的版本,只有 MyISAM 存储引擎支持全文索引;
- MySQL 5.6 及以后的版本,MyISAM 和 InnoDB 存储引擎均支持全文索引;
测试或使用全文索引时,要先看一下自己的 MySQL 版本、存储引擎和数据类型是否支持全文索引。
创建全文索引
-
创建表时创建全文索引
create table fulltext_test ( id int(11) NOT NULL AUTO_INCREMENT, content text NOT NULL, tag varchar(255), PRIMARY KEY (id), FULLTEXT KEY content_tag_fulltext(content,tag) -- 创建联合全文索引列 ) ENGINE=MyISAM DEFAULT CHARSET=utf8; -
在已存在的表上创建全文索引
create fulltext index content_tag_fulltext on fulltext_test(content,tag); -
通过SQL语句ALTER TABLE创建全文索引
alter table fulltext_test add fulltext index content_tag_fulltext(content,tag);
修改全文索引
一般不修改,直接删掉重建
删除全文索引
drop index content_tag_fulltext on fulltext_test; -- 直接使用 DROP INDEX 删除全文索引
alter table fulltext_test drop index content_tag_fulltext; -- 通过 SQL 语句 ALTER TABLE 删除全文索引
使用全文索引
和常用的模糊匹配使用 like + % 不同,全文索引有自己的语法格式,使用 match 和 against 关键字
select * from fulltext_test where match(content,tag) against('xxx xxx');
注意: match() 函数中指定的列必须和全文索引中指定的列完全相同,否则就会报错,无法使用全文索引,这是因为全文索引不会记录关键字来自哪一列。如果想要对某一列使用全文索引,请单独为该列创建全文索引。
有了上面的知识,就可以测试一下全文索引了。
首先创建测试表,插入测试数据
create table test (
id int(11) unsigned not null auto_increment,
content text not null,
primary key(id),
fulltext key content_index(content)
) engine=MyISAM default charset=utf8;
insert into test (content) values ('a'),('b'),('c');
insert into test (content) values ('aa'),('bb'),('cc');
insert into test (content) values ('aaa'),('bbb'),('ccc');
insert into test (content) values ('aaaa'),('bbbb'),('cccc');
按照全文索引的使用语法执行下面查询
select * from test where match(content) against('a');
select * from test where match(content) against('aa');
select * from test where match(content) against('aaa');
根据我们的惯性思维,应该会显示 4 条记录才对,然而结果是 1 条记录也没有,只有在执行下面的查询时:
select * from test where match(content) against('aaaa');
才会搜到 aaaa 这 1 条记录。
为什么?这个问题有很多原因,其中最常见的就是 最小搜索长度 导致的。另外插一句,使用全文索引时,测试表里至少要有 4 条以上的记录,否则,会出现意想不到的结果。
MySQL 中的全文索引,有两个变量,最小搜索长度和最大搜索长度,对于长度小于最小搜索长度和大于最大搜索长度的词语,都不会被索引。通俗点就是说,想对一个词语使用全文索引搜索,那么这个词语的长度必须在以上两个变量的区间内。
这两个的默认值可以使用以下命令查看
show variables like '%ft%';
可以看到这两个变量在 MyISAM 和 InnoDB 两种存储引擎下的变量名和默认值
// MyISAM
ft_min_word_len = 4;
ft_max_word_len = 84;
// InnoDB
innodb_ft_min_token_size = 3;
innodb_ft_max_token_size = 84;
可以看到最小搜索长度 MyISAM 引擎下默认是 4,InnoDB 引擎下是 3,也即,MySQL 的全文索引只会对长度大于等于 4 或者 3 的词语建立索引,而刚刚搜索的只有 aaaa 的长度大于等于 4。
配置最小搜索长度
全文索引的相关参数都无法进行动态修改,必须通过修改 MySQL 的配置文件来完成。修改最小搜索长度的值为 1,首先打开 MySQL 的配置文件 /etc/my.cnf,在 [mysqld] 的下面追加以下内容
[mysqld]
innodb_ft_min_token_size = 1
ft_min_word_len = 1
然后重启 MySQL 服务器,并修复全文索引。注意,修改完参数以后,一定要修复下索引,不然参数不会生效。
两种修复方式,可以使用下面的命令修复
repair table test quick;
或者直接删掉重新建立索引,再次执行上面的查询,a、aa、aaa 就都可以查出来了。
但是,这里还有一个问题,搜索关键字 a 时,为什么 aa、aaa、aaaa 没有出现结果中,讲这个问题之前,先说说两种全文索引。
两种全文索引
自然语言的全文索引
默认情况下,或者使用 in natural language mode 修饰符时,match() 函数对文本集合执行自然语言搜索,上面的例子都是自然语言的全文索引。
自然语言搜索引擎将计算每一个文档对象和查询的相关度。这里,相关度是基于匹配的关键词的个数,以及关键词在文档中出现的次数。在整个索引中出现次数越少的词语,匹配时的相关度就越高。相反,非常常见的单词将不会被搜索,如果一个词语的在超过 50% 的记录中都出现了,那么自然语言的搜索将不会搜索这类词语。上面提到的,测试表中必须有 4 条以上的记录,就是这个原因。
这个机制也比较好理解,比如说,一个数据表存储的是一篇篇的文章,文章中的常见词、语气词等等,出现的肯定比较多,搜索这些词语就没什么意义了,需要搜索的是那些文章中有特殊意义的词,这样才能把文章区分开。
布尔全文索引
对于上面提到的问题,可以使用布尔全文索引查询来解决,使用下面的命令,a、aa、aaa、aaaa 就都被查询出来了。
select * test where match(content) against('a*' in boolean mode);
在布尔搜索中,我们可以在查询中自定义某个被搜索的词语的相关性,当编写一个布尔搜索查询时,可以通过一些前缀修饰符来定制搜索。
MySQL 内置的修饰符,上面查询最小搜索长度时,搜索结果 ft_boolean_syntax 变量的值就是内置的修饰符,下面简单解释几个,更多修饰符的作用可以查手册
-
+ 必须包含该词
-
- 必须不包含该词
-
> 提高该词的相关性,查询的结果靠前
-
< 降低该词的相关性,查询的结果靠后
-
* 通配符,只能接在词后面
-
~表示允许出现该单词,但是出现时相关性为负
-
() 子表达式
-
"" 匹配双引号中的字面值,全文检索引擎会将双引号中的内容按照单词分开,非单词字符不用匹配,比如“test phrase”匹配“test,phrase”
-
(no operator) 表示所查询的字符是可选的,如果出现,其相关性会更高
-
@distance 仅仅适用于innodb。测试两个或多个单词出现的距离是否在distance的值之内,distance的单位是单词的个数。下面的测试结果是多个单词之间最远的距离要在distance之间:
假设数据库article表中有这么一条记录:
id title body 12 BOOLEN Tutorial s1,w2,d3,a4,s5,s6,s7,s8,s9,s10,a11,c12 执行语句:
SELECT * FROM articles WHERE MATCH (title , body) AGAINST ('"w2 a4 s9" @9' IN BOOLEAN MODE);查询结果:
id title body 12 BOOLEN Tutorial s1,w2,d3,a4,s5,s6,s7,s8,s9,s10,a11,c12 执行语句:
SELECT * FROM articles WHERE MATCH (title , body) AGAINST ('"w2 a4 s9" @8' IN BOOLEAN MODE);查询结果:
id title body 12 BOOLEN Tutorial s1,w2,d3,a4,s5,s6,s7,s8,s9,s10,a11,c12 执行语句:
SELECT * FROM articles WHERE MATCH (title , body) AGAINST ('"w2 a4 s9" @7' IN BOOLEAN MODE);查询结果:
Empty set
执行语句:
SELECT * FROM articles WHERE MATCH (title , body) AGAINST ('"w2 a4 s9" @6' IN BOOLEAN MODE);查询结果:
Empty set
解释:w2 a4 s9 三个单词在“s1,w2,d3,a4,s5,s6,s7,s8,s9,s10,a11,c12”这串字符串中w2和a4距离为2,w2和s9距离为7,a4和s9距离为5,因此只需要@x中的x满足x>2且x>7且x>5即可满足要求,即可把该条记录筛选出来。
小结
MySQL 的全文索引最开始仅支持英语,因为英语的词与词之间有空格,使用空格作为分词的分隔符是很方便的。亚洲文字,比如汉语、日语、汉语等,是没有空格的,这就造成了一定的限制。不过 MySQL 5.7.6 开始,引入了一个 ngram 全文分析器来解决这个问题,并且对 MyISAM 和 InnoDB 引擎都有效。
事实上,MyISAM 存储引擎对全文索引的支持有很多的限制,例如表级别锁对性能的影响、数据文件的崩溃、崩溃后的恢复等,这使得 MyISAM 的全文索引对于很多的应用场景并不适合。所以,多数情况下的建议是使用别的解决方案,例如 Sphinx、Lucene 等等第三方的插件,亦或是使用 InnoDB 存储引擎的全文索引。
几个注意点:
- 使用全文索引前,搞清楚版本支持情况;
- 全文索引比 like + % 快 N 倍,但是可能存在精度问题;
- 如果需要全文索引的是大量数据,建议先添加数据,再创建索引;
- 对于中文,可以使用 MySQL 5.7.6 之后的版本,或者第三方插件。
全文索引测试示例
由于建立全文索引的表的存储引擎类型必须为MyISAM
因此新建一个utf8 MyISAM类型的表并建立一个全文索引:
CREATE TABLE articles (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR(200),
body TEXT,
FULLTEXT (title,body)
) ENGINE=MyISAM DEFAULT
其中FULLTEXT(title, body) 给title和body这两列建立全文索引,之后检索的时候注意必须同时指定这两列。
给这个表添加点测试数据
INSERT INTO articles (title,body) VALUES
('MySQL Tutorial','DBMS stands for DataBase ...'),
('How To Use MySQL Well','After you went through a ...'),
('Optimizing MySQL','In this tutorial we will show ...'),
('1001 MySQL Tricks','1. Never run mysqld as root. 2. ...'),
('MySQL vs. YourSQL','In the following database comparison ...'),
('MySQL Security','When configured properly, MySQL ...');
全文检索测试
SELECT * FROM articles WHERE MATCH (title,body) AGAINST ('database');
注意:
-
MATCH (title,body) 里面的值必须是前面建立全文索引的两个字段不能少。
-
FULLTEXT用于搜索很长一篇文章的时候,效果最好。用在比较短的文本,如果就一两行字的,普通的 INDEX 也可以。
空间索引spatial
CREATE TABLE `shop_info` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'id',
`shop_name` varchar(64) NOT NULL COMMENT '门店名称',
`geom_point` geometry NOT NULL COMMENT '经纬度',
PRIMARY KEY (`id`),
SPATIAL KEY `geom_index` (`geom_point`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
初始化测试数据:
delimiter //
CREATE PROCEDURE init_shop_info()
BEGIN
DECLARE count INT;
DECLARE batch INT;
DECLARE initLong INT;
DECLARE initLat INT;
SET count = 0;
SET initLong = 121;
SET initLat = 31;
WHILE count < 5000000 DO
SET batch = 0;
START TRANSACTION;
WHILE batch < 1000 DO
insert into shop_info(shop_name, geom_point) values (concat('shop', count), Point(initLong + Rand(),initLat + Rand()));
SET batch = batch + 1;
SET count = count + 1;
END WHILE;
COMMIT;
END WHILE;
END //
delimiter ;
call init_shop_info();
执行SQL获取附近2KM以内的记录
粗精度
为了指定位置周围创建边界矩形(以便可以利用其上的空间索引),可以使用经度和纬度之间的平均距离111公里。每纬度近似111km,而每经度则超过111km。因此创建出来的边界矩形会比实际需求的边界大。
-- 东经121.5
set @longitude = 121.5;
-- 北纬31.5
set @latitude = 31.5;
-- 2KM范围内
set @distance = 2000;
select id, x(geom_point) longitude, y(geom_point) latitude, ST_Distance_Sphere(Point(@longitude, @latitude), geom_point) as distance
from shop_info
where MBRContains(ST_MakeEnvelope(
point((@longitude+(@distance/1000/111)), (@latitude+(@distance/1000/111))),
point((@longitude-(@distance/1000/111)), (@latitude-(@distance/1000/111))))
, geom_point)
order by distance limit 10;
细精度
如果需要边界矩形更精确,则可以使用cos(radians(${latitude})) * 111进行经度计算。示例SQL如下:
-- 东经121.5
set @longitude = 121.5;
-- 北纬31.5
set @latitude = 31.5;
-- 2KM范围内
set @distance = 2000;
select id, x(geom_point) longitude, y(geom_point) latitude, ST_Distance_Sphere(Point(@longitude, @latitude), geom_point) as distance
from shop_info
where MBRContains(ST_MakeEnvelope(
point((@longitude+(@distance/1000/111*cos(radians(@latitude)))), (@latitude+(@distance/1000/111))),
point((@longitude-(@distance/1000/111*cos(radians(@latitude)))), (@latitude-(@distance/1000/111))))
, geom_point)
order by distance limit 10;
注意:
- ST_MakeEnvelope和ST_Distance_Sphere从MYSQL 5.7.6版本开始支持
ST_Distance_Sphere返回的单位为米
geometry类型
当需要将多边形每个角上的坐标点存入MySQL的时候,就需要用到geometry类型了
CREATE TABLE `gim` (
`path` varchar(512) NOT NULL,
`box` geometry NOT NULL,
PRIMARY KEY (`path`),
SPATIAL KEY `box` (`box`)
) ;
插入数据
数据的插入和普通的数据插入一样,只是geometry数据需要使用st_geomfromtext等函数来构造,相关的文档参考在这里gis-data-formats还有这个populating-spatial-columns。
这里只展示一个简单数据插入,这里我使用的是单多边形,只有四个点(逆时针顺序),使用WKT描述几何数据。
insert into gim (path,box) values('%s',ST_GeomFromText(
'Polygon((116.18866 39.791107, 116.124115 39.791107, 116.18866 39.833679, 116.124115 39.833679, 116.18866 39.791107))'));
查询这里和普通的查询也一样,只是where字句后面使用空间过滤相关选项就是。
使用空间索引进行查询的相关文档在这里using-spatial-indexes
MySQL的文档中只提及了MBRContains和MBRWithin两种方式,经过测试,MBRIntersects、MBREqual、MBROverlaps、MBRTouches、MBRDisjoint都可以使用。
SpatiaLite中有一幅关于空间检索的图,放在这里做个参考。
SpatiaLite有一篇详细介绍空间索引的文档,链接在这里http://www.gaia-gis.it/spatialite-2.1/SpatiaLite-manual.html
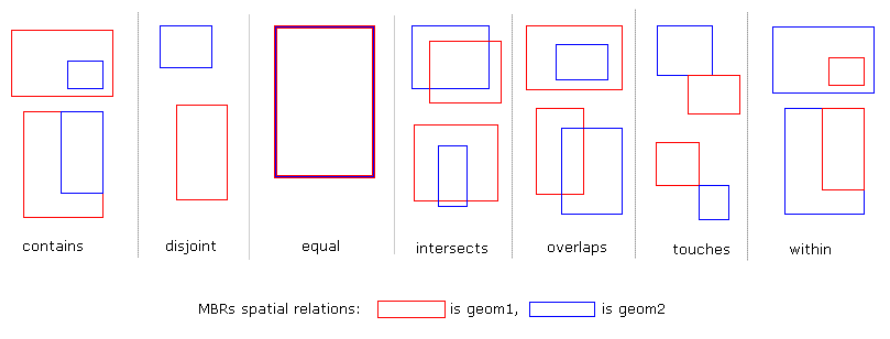
一个简单的查询示例:
select * from gim where MBRContains(st_geomfromtext('polygon((116.438599 39.832306, 116.374054 39.832306, 116.438599 39.876251, 116.374054 39.876251, 116.438599 39.832306))'),box);
返回结果:
+------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------------------+
| path | box |
+------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------------------+
| file:///root1/北京/北京分区/æœé˜³åŒº/æœé˜³åŒº2016/J50G004039.tif | POLYGON((116.438599 39.832306, 116.374054 39.832306, 116.438599 39.876251, 116.374054 39.876251, 116.438599 39.832306)) |
| file:///root1/北京/北京分区/æœé˜³åŒº/æœé˜³åŒº2005/J50G004039.tif | POLYGON((116.438599 39.832306, 116.374054 39.832306, 116.438599 39.876251, 116.374054 39.876251, 116.438599 39.832306)) |
| file:///root1/北京/北京分区/æœé˜³åŒº/æœé˜³åŒº2003/J50G004039.tif | POLYGON((116.438599 39.832306, 116.374054 39.832306, 116.438599 39.876251, 116.374054 39.876251, 116.438599 39.832306)) |
| file:///root1/北京/北京分幅/J50G004039.tif | POLYGON((116.438599 39.832306, 116.374054 39.832306, 116.438599 39.876251, 116.374054 39.876251, 116.438599 39.832306)) |
+------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------------------+
4 rows in set
其他的还可以使用MBRIntersects、MBREqual、MBROverlaps、MBRTouches、MBRDisjoint:
select url from ngcc_metadata where MBRIntersects(st_geomfromtext('polygon((116.438599 39.832306, 116.374054 39.832306, 116.438599 39.876251, 116.374054 39.876251, 116.438599 39.832306))'),`5`);
select url from ngcc_metadata where MBREqual(st_geomfromtext('polygon((116.438599 39.832306, 116.374054 39.832306, 116.438599 39.876251, 116.374054 39.876251, 116.438599 39.832306))'),`5`);
select url from ngcc_metadata where MBROverlaps(st_geomfromtext('polygon((116.438599 39.832306, 116.374054 39.832306, 116.438599 39.876251, 116.374054 39.876251, 116.438599 39.832306))'),`5`);
select url from ngcc_metadata where MBRTouches(st_geomfromtext('polygon((116.438599 39.832306, 116.374054 39.832306, 116.438599 39.876251, 116.374054 39.876251, 116.438599 39.832306))'),`5`);
select url from ngcc_metadata where MBRDisjoint(st_geomfromtext('polygon((116.438599 39.832306, 116.374054 39.832306, 116.438599 39.876251, 116.374054 39.876251, 116.438599 39.832306))'),`5`);
更多的或者更具体的使用方法请参考官方文档
索引中的visible与invisible
参考博客:https://blog.csdn.net/zhizhengguan/article/details/87276163
mysql查询某个表的字段名
描述表字段信息
DESC TableName;
查表字段及其信息
SHOW COLUMNS FROM TableName;
information_schema库详解(存放MySQL的元数据)
SCHEMATA # 提供了关于数据库的信息。
TABLES # 给出了关于数据库中的表的信息。
COLUMNS # 给出了表中的列信息。
STATISTICS # 给出了关于表索引的信息。
USER_PRIVILEGES # 给出了关于全程权限的信息。该信息源自mysql.user授权表。
SCHEMA_PRIVILEGES # 给出了关于方案(数据库)权限的信息。该信息来自mysql.db授权表。
TABLE_PRIVILEGES # 给出了关于表权限的信息。该信息源自mysql.tables_priv授权表。
COLUMN_PRIVILEGES # 给出了关于列权限的信息。该信息源自mysql.columns_priv授权表。
CHARACTER_SETS # 提供了关于可用字符集的信息。
COLLATIONS # 提供了关于各字符集的对照信息。
COLLATION_CHARACTER_SET_APPLICABILITY # 指明了可用于校对的字符集。
TABLE_CONSTRAINTS # 描述了存在约束的表。
KEY_COLUMN_USAGE # 描述了具有约束的键列。
ROUTINES # 提供了关于存储子程序(存储程序和函数)的信息。此时,ROUTINES表不包含自定义函数(UDF)。
VIEWS # 给出了关于数据库中的视图的信息。
TRIGGERS # 提供了关于触发程序的信息。
用法实例:
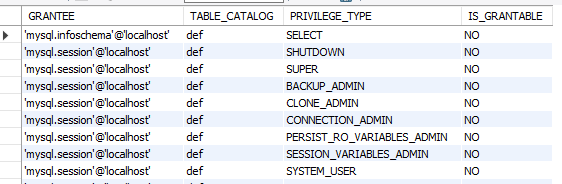
-- 比方说USER_PRIVILEGES
select * from information_schema.USER_PRIVILEGES;
查字段
select
COLUMN_NAME
from
information_schema.COLUMNS
where table_name = "TableName" and table_schema = "DatabaseName";
查看字段详细信息
SELECT
COLUMN_NAME "字段名称",
COLUMN_TYPE "字段类型长度",
IF(EXTRA="auto_increment",CONCAT(COLUMN_KEY,"(", IF(EXTRA="auto_increment","自增长",EXTRA),")"),COLUMN_KEY) "主外键",
IS_NULLABLE "空标识",
COLUMN_COMMENT "字段说明"
FROM
information_schema. COLUMNS
WHERE TABLE_SCHEMA = "DatabaseName" AND TABLE_NAME = "TableName";
查询字段个数
select
count(*)
from
information_schema.COLUMNS
where table_name = "TableName" and table_schema = "DatabaseName";
查询某字段所在行数
set @temp = 0;
select * from (
select @temp:=@temp+1 as new_id, t.COLUMN_NAME as col_name from(
select
COLUMN_NAME
from
information_schema.COLUMNS
where
table_schema="DatabaseName" and table_name="TableName"
) t
) t
where col_name="需要查询的字段的名称";
处理成插入的字段
-- 一列,逗号在前
SET @mytemp = 0;
SELECT
(CASE t.newid
WHEN 1
THEN CONCAT(' ',COLUMN_NAME)
ELSE CONCAT(',',COLUMN_NAME)
END
)COLUMN_NAME
-- t.newid,t.COLUMN_NAME
FROM (
SELECT * FROM (
SELECT (@mytemp:=@mytemp+1) AS newid,t.COLUMN_NAME FROM
(
SELECT
COLUMN_NAME
FROM
information_schema.COLUMNS
WHERE
TABLE_SCHEMA = 'DatabaseName'
AND TABLE_NAME = 'TableName'
)t
) t
)t
-- 用分组的方法(一行)
SELECT
COUNT(*) count_num,GROUP_CONCAT(COLUMN_NAME)
FROM
information_schema.COLUMNS
WHERE
TABLE_SCHEMA = 'DatabaseName'
AND TABLE_NAME = 'TableName'

查询某个库除了主键以外的约束
SELECT
TABLE_NAME '表名',
COLUMN_NAME '字段名',
CONSTRAINT_NAME '约束名',
REFERENCED_TABLE_NAME '父表名',
REFERENCED_COLUMN_NAME '父表字段名'
FROM
INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE
TABLE_SCHEMA = 'net_management'
AND CONSTRAINT_name != 'PRIMARY';
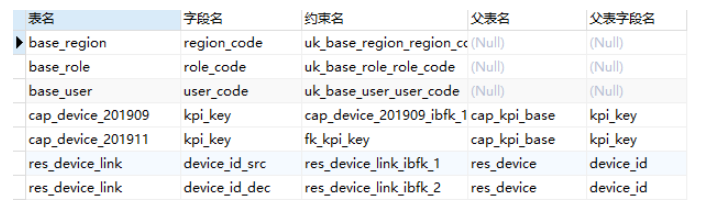
查询某个库的约束和约束类型
SELECT
kcu.CONSTRAINT_NAME '约束名称',
LEFT(tc.CONSTRAINT_TYPE,1) '约束类型',
kcu.TABLE_SCHEMA '子库',
kcu.TABLE_NAME '子表',
kcu.COLUMN_NAME '子表字段',
kcu.REFERENCED_TABLE_NAME '父库',
kcu.REFERENCED_TABLE_SCHEMA '父表',
kcu.REFERENCED_COLUMN_NAME '父表字段'
FROM
information_schema.KEY_COLUMN_USAGE kcu
LEFT JOIN
information_schema.`TABLE_CONSTRAINTS` tc
ON kcu.TABLE_SCHEMA = tc.TABLE_SCHEMA
AND kcu.TABLE_NAME = tc.TABLE_NAME
AND kcu.CONSTRAINT_NAME = tc.CONSTRAINT_NAME
WHERE
kcu.TABLE_SCHEMA = 'zx_public'
-- AND kcu.CONSTRAINT_NAME!='PRIMARY'
-- AND kcu.TABLE_NAME = 'res_site'
ORDER BY kcu.TABLE_SCHEMA,kcu.TABLE_NAME,tc.CONSTRAINT_TYPE;
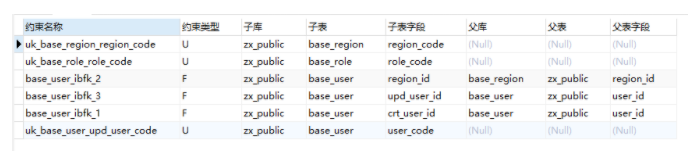
MAXVALUE关键字
代表一个比最大可能的integer的值还要大的数值,用数学语言来讲就是数值的最大上界
常被用于MySQL范围分区中
MySQL分区(partition)功能
= 水平分区(根据列属性按行分) =
举个例子:一个包含十年发票记录的表可以被分区为十个不同的分区,每个分区包含的是其中一年的记录
水平分区的模式
- Range(范围)- 这种模式允许DBA将数据划分不同范围。例如DBA可以将一个表通过年份划分成三个分区,比如:80年代的数据,90年代的数据以及任何在2000年(包括2000年)后的数据
- Hash(哈希)- 这种模式允许DBA通过对表的一个或多个列的Hash Key进行计算,最后通过这个Hash码不同数值对应的数据区域进行分区,比如DBA可以建立一个对表主键进行分区的表
- Key(键值)- Hash模式的一种延伸,这里的Hash Key是MySQL系统产生的
- List(预定义列表)- 这种模式允许系统通过DBA定义的列表的值所对应的行数据进行分割,比如:DBA建立了一个横跨三个分区的表,分别根据2004年2005年和2006年值所对应的数据
- Composite(复合模式)- 其实就是以上模式的组合使用,比如:在初始化已经进行了Range范围分区的表上,我们可以对其中一个分区再进行hash哈希分区
垂直分区(按列分)
举个例子:一个包含了大text和BLOB列的表,这些text和BLOB列不经常被访问,这时候就要把这些不经常使用的text和BLOB划分到另一个分区,在保证它们数据相关性的同时还能提高访问的速度
分区的优点
- 可以提高数据库的性能
- 对大表(行较多)的维护更快、更容易,因为数据分布在不同的逻辑文件上
- 删除分区或它的数据是容易的,因为它不影响其他表
注意:pruning,即截断。意思是说当你查询时,只扫描所需要查询的分区,其他部分不会扫描,这就大大提高了性能
分区表和未分区表试验过程
创建分区表,按日期的年份拆分
CREATE TABLE part_tab ( c1 int default NULL, c2 varchar(30) default NULL, c3 date default NULL) engine=myisam
PARTITION BY RANGE (year(c3))
(PARTITION p0 VALUES LESS THAN (1995) , PARTITION p1 VALUES LESS THAN (1996) ,
PARTITION p2 VALUES LESS THAN (1997) , PARTITION p3 VALUES LESS THAN (1998) ,
PARTITION p4 VALUES LESS THAN (1999) , PARTITION p5 VALUES LESS THAN (2000) ,
PARTITION p6 VALUES LESS THAN (2001) , PARTITION p7 VALUES LESS THAN (2002) ,
PARTITION p8 VALUES LESS THAN (2003) , PARTITION p9 VALUES LESS THAN (2004) ,
PARTITION p10 VALUES LESS THAN (2010), PARTITION p11 VALUES LESS THAN MAXVALUE );
注意到最后一行,考虑到可能的最大值
创建未分区表
create table no_part_tab (
c1 int(11) default NULL,
c2 varchar(30) default NULL,
c3 date default NULL
) engine=myisam;
通过存储过程灌入800万数据到两个表中,然后测试性能发现分区的表执行了0.5秒,未分区的执行了4.7秒,使用explain来分析执行的情况:
id: 1
select_type: SIMPLE
table: no_part_tab #未分区的表的表名
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 8000000 #需要查询800万条记录
Extra: Using where
id: 1
select_type: SIMPLE
table: part_tab #分区的表的表名
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 798458 #只需要查询798458条记录
Extra: Using where
试验创建索引后情况
create index idx_of_c3 on no_part_tab (c3);
create index idx_of_c3 on part_tab (c3);
创建索引后的数据库文件大小列表:
2008-05-24 09:23 8,608 no_part_tab.frm
2008-05-24 09:24 255,999,996 no_part_tab.MYD
2008-05-24 09:24 81,611,776 no_part_tab.MYI
2008-05-24 09:25 0 part_tab#P#p0.MYD
2008-05-24 09:26 1,024 part_tab#P#p0.MYI
2008-05-24 09:26 25,550,656 part_tab#P#p1.MYD
2008-05-24 09:26 8,148,992 part_tab#P#p1.MYI
2008-05-24 09:26 25,620,192 part_tab#P#p10.MYD
2008-05-24 09:26 8,170,496 part_tab#P#p10.MYI
2008-05-24 09:25 0 part_tab#P#p11.MYD
2008-05-24 09:26 1,024 part_tab#P#p11.MYI
2008-05-24 09:26 25,656,512 part_tab#P#p2.MYD
2008-05-24 09:26 8,181,760 part_tab#P#p2.MYI
2008-05-24 09:26 25,586,880 part_tab#P#p3.MYD
2008-05-24 09:26 8,160,256 part_tab#P#p3.MYI
2008-05-24 09:26 25,585,696 part_tab#P#p4.MYD
2008-05-24 09:26 8,159,232 part_tab#P#p4.MYI
2008-05-24 09:26 25,585,216 part_tab#P#p5.MYD
2008-05-24 09:26 8,159,232 part_tab#P#p5.MYI
2008-05-24 09:26 25,655,740 part_tab#P#p6.MYD
2008-05-24 09:26 8,181,760 part_tab#P#p6.MYI
2008-05-24 09:26 25,586,528 part_tab#P#p7.MYD
2008-05-24 09:26 8,160,256 part_tab#P#p7.MYI
2008-05-24 09:26 25,586,752 part_tab#P#p8.MYD
2008-05-24 09:26 8,160,256 part_tab#P#p8.MYI
2008-05-24 09:26 25,585,824 part_tab#P#p9.MYD
2008-05-24 09:26 8,159,232 part_tab#P#p9.MYI
2008-05-24 09:25 8,608 part_tab.frm
2008-05-24 09:25 68 part_tab.par
再次测试性能发现分区的表执行了0.86秒,未分区的执行了2.42秒
增加未索引字段查询之后分区的表执行了0.75秒,未分区的执行了11.5秒
结论
初步结论
- 分区和未分区占用文件空间大致相同(数据和索引文件)
- 如果查询语句中有未建立索引字段,分区时间远远优于未分区时间
- 如果查询语句中字段建立了索引,分区和未分区的差别缩小,分区略优于未分区
最终结论
- 对于大数据量,建议使用分区功能
- 应去除不必要的字段
- 根据手册,增加myisam_max_sort_file_size(MySQL重建索引时允许使用的临时文件最大大小)会增加分区的性能
分区命令详解
RANGE类型
CREATE TABLE users (
uid INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(30) NOT NULL DEFAULT '',
email VARCHAR(30) NOT NULL DEFAULT ''
)
PARTITION BY RANGE (uid) (
PARTITION p0 VALUES LESS THAN (3000000)
DATA DIRECTORY = '/data0/data'
INDEX DIRECTORY = '/data1/idx',
PARTITION p1 VALUES LESS THAN (6000000)
DATA DIRECTORY = '/data2/data'
INDEX DIRECTORY = '/data3/idx',
PARTITION p2 VALUES LESS THAN (9000000)
DATA DIRECTORY = '/data4/data'
INDEX DIRECTORY = '/data5/idx',
PARTITION p3 VALUES LESS THAN MAXVALUE
DATA DIRECTORY = '/data6/data'
INDEX DIRECTORY = '/data7/idx'
);
在这里,将用户表分成4个分区,以每300万条记录为界限,每个分区都有自己独立的数据、索引文件的存放目录,与此同时,这些目录所在的物理磁盘分区可能也都是完全独立的,可以提高磁盘IO吞吐量
LIST类型
CREATE TABLE category (
cid INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(30) NOT NULL DEFAULT ''
)
PARTITION BY LIST (cid) (
PARTITION p0 VALUES IN (0,4,8,12)
DATA DIRECTORY = '/data0/data'
INDEX DIRECTORY = '/data1/idx',
PARTITION p1 VALUES IN (1,5,9,13)
DATA DIRECTORY = '/data2/data'
INDEX DIRECTORY = '/data3/idx',
PARTITION p2 VALUES IN (2,6,10,14)
DATA DIRECTORY = '/data4/data'
INDEX DIRECTORY = '/data5/idx',
PARTITION p3 VALUES IN (3,7,11,15)
DATA DIRECTORY = '/data6/data'
INDEX DIRECTORY = '/data7/idx'
);
分成4个区,数据文件和索引文件单独存放
HASH类型
CREATE TABLE users (
uid INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(30) NOT NULL DEFAULT '',
email VARCHAR(30) NOT NULL DEFAULT ''
)
PARTITION BY HASH (uid) PARTITIONS 4 (
PARTITION p0
DATA DIRECTORY = '/data0/data'
INDEX DIRECTORY = '/data1/idx',
PARTITION p1
DATA DIRECTORY = '/data2/data'
INDEX DIRECTORY = '/data3/idx',
PARTITION p2
DATA DIRECTORY = '/data4/data'
INDEX DIRECTORY = '/data5/idx',
PARTITION p3
DATA DIRECTORY = '/data6/data'
INDEX DIRECTORY = '/data7/idx'
);
KEY类型
CREATE TABLE users (
uid INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(30) NOT NULL DEFAULT '',
email VARCHAR(30) NOT NULL DEFAULT ''
)
PARTITION BY KEY (uid) PARTITIONS 4 (
PARTITION p0
DATA DIRECTORY = '/data0/data'
INDEX DIRECTORY = '/data1/idx',
PARTITION p1
DATA DIRECTORY = '/data2/data'
INDEX DIRECTORY = '/data3/idx',
PARTITION p2
DATA DIRECTORY = '/data4/data'
INDEX DIRECTORY = '/data5/idx',
PARTITION p3
DATA DIRECTORY = '/data6/data'
INDEX DIRECTORY = '/data7/idx'
);
分成4个区,数据文件和索引文件单独存放
子分区
子分区是针对RANGE/LIST类型的分区表中每个分区的再次分割。再次分割可以是HASH/KEY等类型。
对RANGE分区再次进行子分区划分,子分区采用HASH类型:
CREATE TABLE users (
uid INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(30) NOT NULL DEFAULT '',
email VARCHAR(30) NOT NULL DEFAULT ''
)
PARTITION BY RANGE (uid) SUBPARTITION BY HASH (uid % 4) SUBPARTITIONS 2(
PARTITION p0 VALUES LESS THAN (3000000)
DATA DIRECTORY = '/data0/data'
INDEX DIRECTORY = '/data1/idx',
PARTITION p1 VALUES LESS THAN (6000000)
DATA DIRECTORY = '/data2/data'
INDEX DIRECTORY = '/data3/idx'
);
或者
对RANGE分区再次进行子分区划分,子分区采用KEY类型:
CREATE TABLE users (
uid INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(30) NOT NULL DEFAULT '',
email VARCHAR(30) NOT NULL DEFAULT ''
)
PARTITION BY RANGE (uid) SUBPARTITION BY KEY(uid) SUBPARTITIONS 2(
PARTITION p0 VALUES LESS THAN (3000000)
DATA DIRECTORY = '/data0/data'
INDEX DIRECTORY = '/data1/idx',
PARTITION p1 VALUES LESS THAN (6000000)
DATA DIRECTORY = '/data2/data'
INDEX DIRECTORY = '/data3/idx'
);
分区管理
获取分区信息
MySQL可以通过如下方式来获取分区表的信息:
show create table tbl_name; -- 表详细结构 --
show table status; -- 表的各种参数状态 --
select * from information_schema.partitions; -- 通过数据字典来查看表的分区信息 --
explain select * from tbl_name; -- 通过此语句查到若干信息,里面有一个partitions能显示扫描哪些分区,结合其他字段我们能知道它们的使用情况 --
删除分区
ALTER TABLE tbl_name DROP PARTITION p0; #删除分区 p0
删除所有分区
ALTER TABLE tbl_name REMOVE PARTITIONING;
重建分区
-
RANGE分区重建
ALTER TABLE users REORGANIZE PARTITION p0,p1 INTO (PARTITION p0 VALUES LESS THAN (6000000)); #将原来的 p0,p1 分区合并起来,放到新的 p0 分区中。 -
LIST分区重建
ALTER TABLE users REORGANIZE PARTITION p0,p1 INTO (PARTITION p0 VALUES IN(0,1,4,5,8,9,12,13));#将原来的 p0,p1 分区合并起来,放到新的 p0 分区中。 -
HASH/KEY分区重建
ALTER TABLE users REORGANIZE PARTITION COALESCE PARTITION 2; #用 REORGANIZE 方式重建分区的数量变成2,在这里数量只能减少不能增加。想要增加可以用 ADD PARTITION 方法。
新增分区
-
新增RANGE分区
#新增一个RANGE分区 ALTER TABLE category ADD PARTITION (PARTITION p4 VALUES IN (16,17,18,19) DATA DIRECTORY = '/data8/data' INDEX DIRECTORY = '/data9/idx'); -
新增HASH/KEY分区
ALTER TABLE users ADD PARTITION PARTITIONS 8; #将分区总数扩展到8个。 -
给已有的表加上分区
alter table results partition by RANGE (month(ttime)) (PARTITION p0 VALUES LESS THAN (1) , PARTITION p1 VALUES LESS THAN (2) , PARTITION p2 VALUES LESS THAN (3) , PARTITION p3 VALUES LESS THAN (4) , PARTITION p4 VALUES LESS THAN (5) , PARTITION p5 VALUES LESS THAN (6) , PARTITION p6 VALUES LESS THAN (7) , PARTITION p7 VALUES LESS THAN (8) , PARTITION p8 VALUES LESS THAN (9) , PARTITION p9 VALUES LESS THAN (10) , PARTITION p10 VALUES LESS THAN (11), PARTITION p11 VALUES LESS THAN (12), PARTITION P12 VALUES LESS THAN (13));
默认分区限制分区字段必须是主键(PRIMARY KEY)的一部分,为了除去此限制:
-
方法一
使用ID:
mysql> ALTER TABLE np_pk -> PARTITION BY HASH( TO_DAYS(added) ) -> PARTITIONS 4; #ERROR 1503 (HY000): A PRIMARY KEY must include all columns in the table's partitioning function mysql> ALTER TABLE np_pk -> PARTITION BY HASH(id) -> PARTITIONS 4; Query OK, 0 rows affected (0.11 sec) Records: 0 Duplicates: 0 Warnings: 0 -
方法二
将原有pk去掉生成新的pk:
alter table results drop PRIMARY KEY; alter table results add PRIMARY KEY(id, ttime);
分区维护
对于分区表,MySQL不支持命令CHECK TABLE,OPTIMIZE TABLE,ANALYZE TABLE,或REPAIR TABLE。作为替代,可以使用ALTER TABLE 的许多扩展来在一个或多个分区上直接地执行这些操作,如下面列出的那样:
重建分区
ALTER TABLE t1 REBUILD PARTITION (p0, p1);
优化分区:如果从分区中删除了大量的行,或者对一个带有可变长度的行(也就是说,有VARCHAR,BLOB,或TEXT类型的列)作了许多修改,可以使用“ALTER TABLE … OPTIMIZE PARTITION”来收回没有使用的空间,并整理分区数据文件的碎片
优化分区
#在一个给定的分区表上使用“OPTIMIZE PARTITION”等同于在那个分区上运行CHECK PARTITION,ANALYZE PARTITION,和REPAIR PARTITION。
ALTER TABLE t1 OPTIMIZE PARTITION (p0, p1);
分析分区
#读取并保存分区的键分布
ALTER TABLE t1 ANALYZE PARTITION (p3);
修补分区
#修补被破坏的分区。
ALTER TABLE t1 REPAIR PARTITION (p0,p1);
检查分区
#可以使用几乎与对非分区表使用CHECK TABLE 相同的方式检查分区
#这个命令可以告诉你表t1的分区p1中的数据或索引是否已经被破坏。如果发生了这种情况,使用“ALTER TABLE ... REPAIR PARTITION”来修补该分区
ALTER TABLE t1 CHECK PARTITION (p1);
#还可以使用mysqlcheck或myisamchk 应用程序,在对表进行分区时所产生的、单独的MYI文件上进行操作,来完成这些任务。
MYSIAM支持的并发插入
在一定条件下,MYSIAM表也支持查询和插入操作的并发进行
MYSIAM存储引擎有一个系统变量concurrent_insert,专门用以控制其并发插入的行为,其值可以为0、1、2
- 0:不允许并发插入
- 1:如果mysiam表中没有空洞(即表的中间没有被删除的行),mysiam允许在一个进程读表的同时,另一个进程从表尾插入记录,这也是mysiam的默认设置,如果有空洞的话虽然不能很好地并发,但是mysql还是可以使用insert delayed来提升插入性能(仅适用于mysiam、memory、archive引擎)
- 2:无论mysiam表中是否有空洞,都允许在表尾并发插入记录,这时MySQL允许insert和select语句在中间没有空数据块的mysiam表中并行运行
MySQL InnoDB行记录模式(ROW_FORMAT)
行模式主要分为compressed、dynamic、Compact、Redundant等,区别主要体现在硬件层面的存储方式,具体请查阅网络资料(参考:https://www.cnblogs.com/wilburxu/p/9435818.html)
引擎
MEMORY引擎
内存表,一般用于存放临时数据,关闭数据库服务之后数据全部丢失
可通过ma_heap_table_size(默认16MB)控制Memory表的大小
函数
group_concat()
语法:
group_concat([DISTINCT] 要连接的字段 [Order BY 排序字段 ASC/DESC] [Spearator ‘分隔符’])
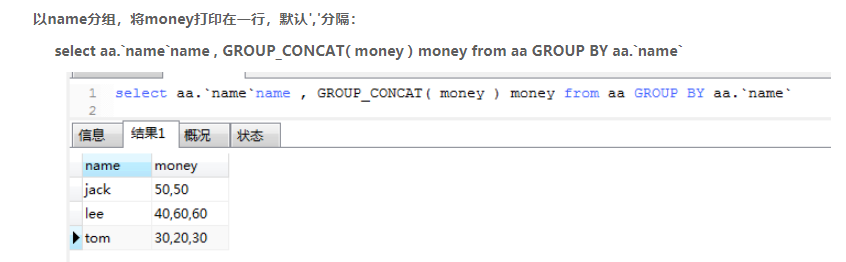
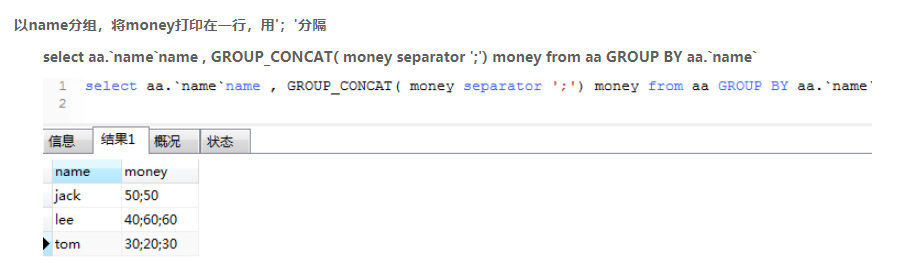
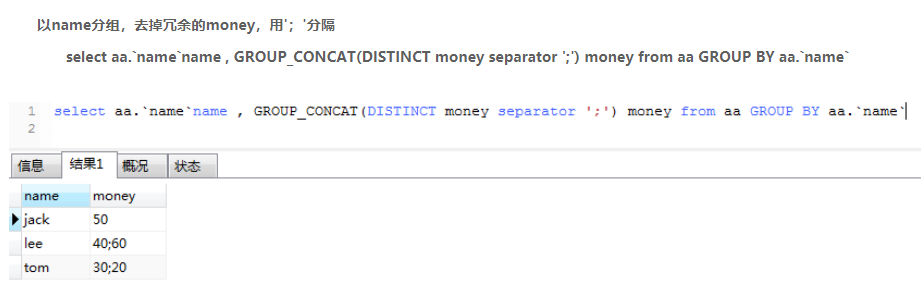
案例:
group_concat()和substring_index()函数连用可解决 group by 后 order by 失效问题(还有一种替代方案是使用max()函数配合 group by 实现与 group by 后 order by 同样的效果),参考:钱依峰app-service项目
参数设置与限制说明
查看服务器中的设置
show variables like '%group_concat%';
结果:

以上设置说明当前是默认长度1kb
改变参数值
法一:修改配置文件中参数,新增group_concat_max_len = 10240
法二:在会话中实现,全局或当前session中:
SET GLOBAL group_concat_max_len = 10240;
SET SESSION group_concat_max_len = 10240;
DEFAULT()
DEFAULT()函数返回表列的默认值
列的DEFAULT值实在没有用户指定的情况下使用的值
为了使用该函数,应该为该列分配一个DEFAULT值,否则会产生错误
用法:
SELECT DEFAULT(col_name) FROM tbl_name;
LAST_INSERT_ID()
LAST_INSERT_ID()、LAST_INSERT_ID(expr)
自动返回最后一个INSERT或 UPDATE 问询为 AUTO_INCREMENT列设置的第一个 发生的值。
mysql> SELECT LAST_INSERT_ID();
-> 195
产生的ID 每次连接后保存在服务器中。这意味着函数向一个给定客户端返回的值是该客户端产生对影响AUTO_INCREMENT列的最新语句第一个 AUTO_INCREMENT值的。这个值不能被其它客户端影响,即使它们产生它们自己的AUTO_INCREMENT值。这个行为保证了你能够找回自己的 ID 而不用担心其它客户端的活动,而且不需要加锁或处理。(因为last_insert_id是针对connection的)
假如你使用一个非“magic”值来更新某一行的AUTO_INCREMENT 列,则LAST_INSERT_ID() 的值不会变化(换言之, 一个不是 NULL也不是 0的值)。
重点: 假如你使用单INSERT语句插入多个行, LAST_INSERT_ID() 只返回插入的第一行产生的值。其原因是这使依靠其它服务器复制同样的 INSERT语句变得简单。
例如:
mysql> USE test;
Database changed
mysql> CREATE TABLE t (
-> id INT AUTO_INCREMENT NOT NULL PRIMARY KEY,
-> name VARCHAR(10) NOT NULL
-> );
mysql> INSERT INTO t VALUES (NULL, 'Bob');
mysql> SELECT * FROM t;
+----+------+| id | name |
+----+------+| 1 | Bob |
mysql> SELECT LAST_INSERT_ID();
-> 1;
mysql> INSERT INTO t VALUES (NULL, 'Mary'), (NULL, 'Jane'), (NULL, 'Lisa');
mysql> SELECT * FROM t;
+----+------+
| id | name |
| 1 | Bob |
| 2 | Mary |
| 3 | Jane |
| 4 | Lisa |
+----+------+
mysql> SELECT LAST_INSERT_ID();
->2;
虽然第二个问询将3 个新行插入 t, 对这些行的第一行产生的 ID 为 2, 这也是 LAST_INSERT_ID()返回的值。
假如你使用 INSERT IGNORE而记录被忽略,则AUTO_INCREMENT 计数器不会增量,而 LAST_INSERT_ID() 返回0, 这反映出没有插入任何记录。
常用用法
若给出作为到LAST_INSERT_ID()的参数expr ,则参数的值被函数返回,并作为被LAST_INSERT_ID()返回的下一个值而被记忆。这可用于模拟序列:
创建一个表,用来控制顺序计数器并使其初始化:
mysql> CREATE TABLE sequence (id INT NOT NULL);
mysql> INSERT INTO sequence VALUES (0);
使用该表产生这样的序列数 :
mysql> UPDATE sequence SET id=LAST_INSERT_ID(id+1);
mysql> SELECT LAST_INSERT_ID();
->1;
UPDATE 语句会增加顺序计数器并引发向LAST_INSERT_ID() 的下一次调用,用来返回升级后的值。 SELECT 语句会检索这个值。 mysql_insert_id()、C API函数也可用于获取这个值。
你可以不用调用LAST_INSERT_ID()而产生序列,但这样使用这个函数的效用在于 ID值被保存在服务器中,作为自动产生的值。它适用于多个用户,原因是多个用户均可使用 UPDATE语句并用SELECT语句(或mysql_insert_id()),得到他们自己的序列值,而不会影响其它产生他们自己的序列值的客户端或被其它产生他们自己的序列值的客户端所影响。
注意: mysql_insert_id() 仅会在INSERT 和UPDATE语句后面被升级, 因此你不能在执行了其它诸如SELECT或 SET 这样的SQL语句后使用 C API 函数来找回 LAST_INSERT_ID(expr) 对应的值。
ROW_NUMBER()和RANK()和DENSE_RANK()
参考:https://developer.aliyun.com/article/593698(mysql8.0窗口函数:rank,dense_rank,row_number 使用上的区别)、https://blog.csdn.net/weixin_40869022/article/details/120275001(ROW_NUMBER和RANK和DENSE_RANK的区别)
SUBSTRING_INDEX()
参考:https://blog.csdn.net/weixin_50853979/article/details/124669207
CAST()
参考:https://blog.csdn.net/Hudas/article/details/124399908
TIMESTAMPDIFF()
时间差函数
语法:TIMESTAMPDIFF(unit, begin, end)
参考:https://blog.csdn.net/qq_16470351/article/details/103686956
属性
@@identity
跟函数last_insert_id()的返回值一样,@@identity表示的是最近一次向具有identity属性(即自增列)的表插入数据时对应的自增列的值,是系统定义的全局变量。
NAMES
MySQL中SET NAMES charset_name 相当于设置了3个session变量:
SET character_set_client = charset_name;
SET character_set_results = charset_name;
SET character_set_connection = charset_name;
参考:https://blog.csdn.net/czh500/article/details/86665509(MySQL SET NAMES)
FOREIGN_KEY_CHECKS
禁用外码约束:
SET FOREIGN_KEY_CHECKS=0;
启动外码约束:
SET FOREIGN_KEY_CHECKS=1;
查看当前FOREIGN_KEY_CHECKS的值可用如下命令:
SELECT @@FOREIGN_KEY_CHECKS;
Canal和Binlog
MySQL Binlog 是一种实时的数据流,用于主从节点之间的数据复制,我们可以利用它来进行数据抽取。
Canal 能够非常便捷地将 MySQL 中的数据抽取到任意目标存储中,使用Canal能做很多很灵活的事情,包括不规则表结构的数据迁移等。
参考:https://blog.csdn.net/zjerryj/article/details/77152226(使用 Binlog 和 Canal 从 MySQL 抽取数据)、https://blog.csdn.net/singgel/article/details/86166154(canal实现mysql实时数据binlog同步)、https://blog.csdn.net/qq_36724582/article/details/124267612(Canal使用流程、部署安装文档)
环形多主多从部署
参考:https://lostphp.com/blog/623.html(关于mysql主从复制(单向、双向、环状))、https://blog.csdn.net/rockyzhuo2014/article/details/82316619(Mysql主从复制、双向同步、环形同步实现)、https://blog.csdn.net/weixin_45742032/article/details/117554233(MYSQL多主多从)
读写分离
参考:https://blog.csdn.net/FateZRK/article/details/125526077(MySQL读写分离)