The article contains the basic knowledge of react…
Code in GitHub: react2021
注意,每一章的总结都在代码文件下的README中
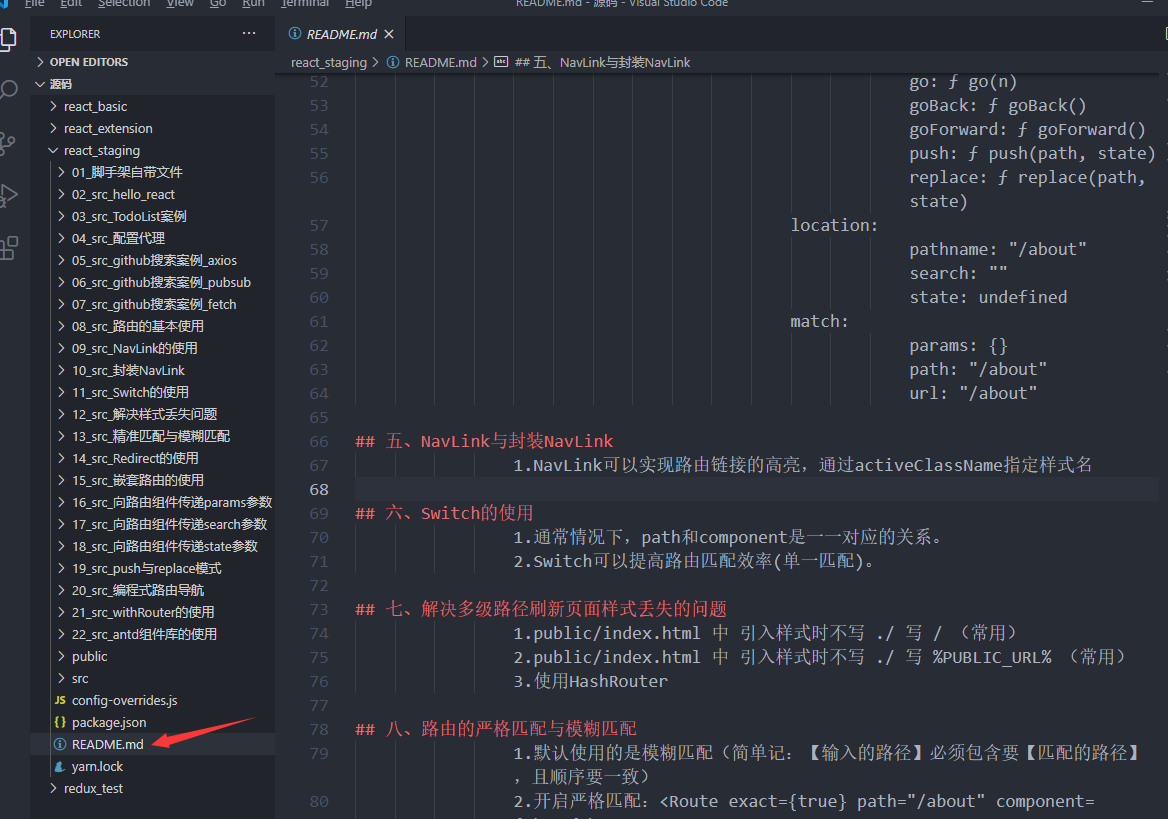
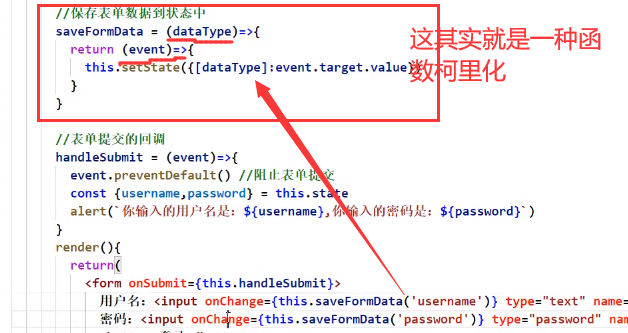
回调函数传参
回调函数里面直接这么写不会被当成回调函数,而会立即执行:
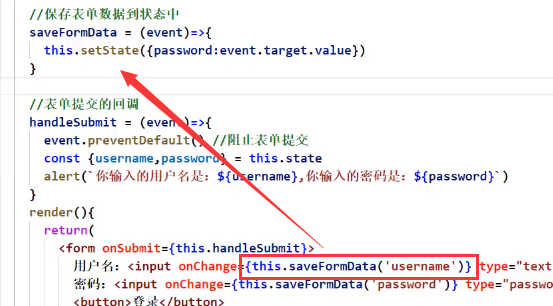
如果我们就想要这么写回调函数,那应该这么写:
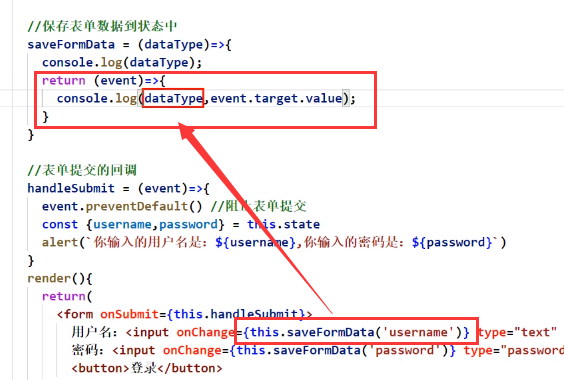
onChange调用的函数再返回一个函数
这样就能实现往回调函数传参了
函数的参数的值作为对象的key(多年以来的疑问)
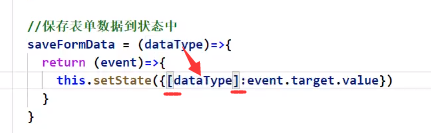
在js中由于没有 "" 来表示到底是变量还是字符串,所以如果想要把一个变量的值作为对象的key只能通过上述方法(在外面套一个 [] )
原理:
原先我们对象取值的时候除了用 . 还能用 [] :
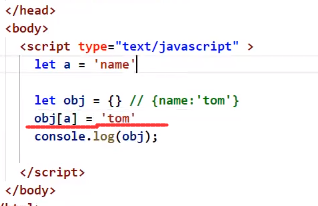
看到上图应该就能理解上上图的做法了
数组元素加和(reduce)
数组的方法,能对数组里面的元素进行加和
函数的柯里化
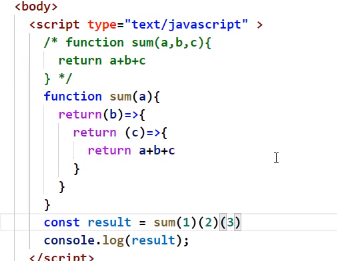
不使用柯里化完成上述操作
他要函数,直接给他函数就行了

新钩子getSnapshotBeforeUpdate以及getDerivedStateFromProps
getSnapshotBeforeUpdate:
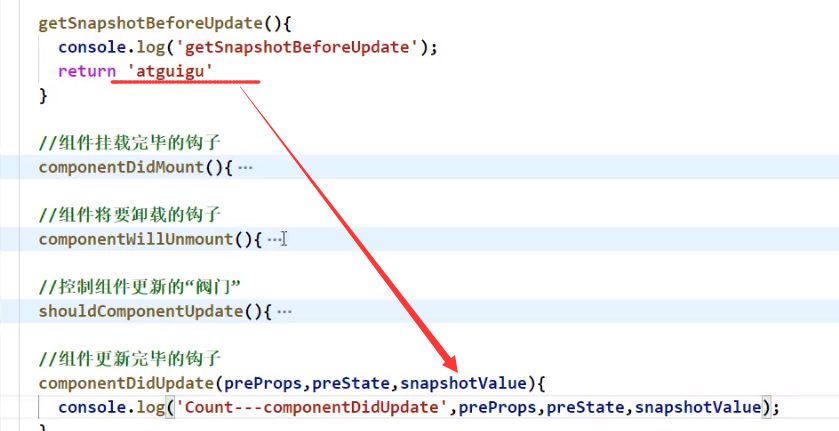
使用场景:

新闻每隔一秒生成一条,下面的新闻会被新的新闻挤下去,导致观看体验不好(没看完就被挤下去了)
这个时候我们就可以使用这个钩子了
我们可以利用element.scrollHeight和element.scrollTop来控制页面从开始有滚动条的时候就不要再将新闻挤下去,同时新的新闻也是在不断加进去的

getDerivedStateFromProps:
参考博客:https://www.jianshu.com/p/50fe3fb9f7c3、https://blog.csdn.net/weixin_43905830/article/details/108760828(getDerivedStateFromProps填坑,包括如何在该静态函数里面使用this等问题的解决方案)
render中使用index为key的问题

点击添加一个小王之后:
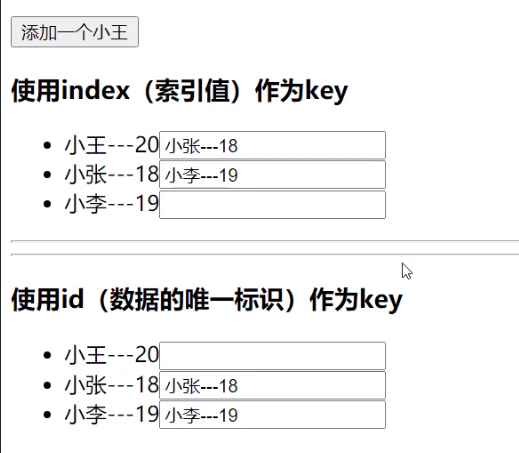
顺序错乱了
原因:
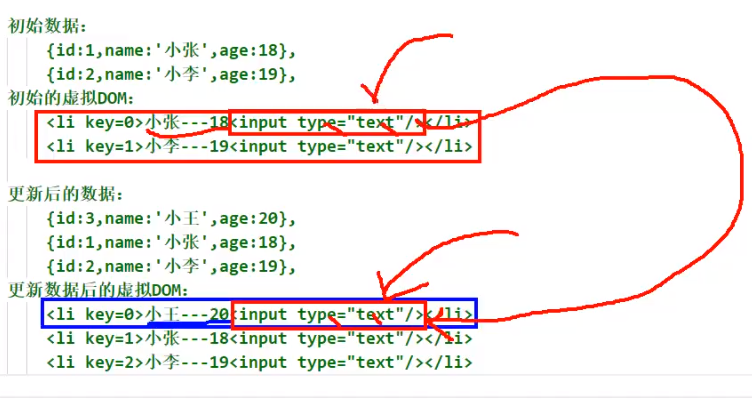
比方说key为0的,里面的文字有变化,会引发虚拟DOM更新,但是文字后面的input框,乍一看属性什么的都一样,看不出有什么变化,因此对于这个input框,虚拟DOM不会更新,但其实他残留了用户输入的信息,这就是问题出现的原因
所以render中遍历的时候key最好不要使用index,最好用唯一标识
react脚手架
public文件解读
index.html:
%PUBLIC_URL%

theme-color

apple-touch-icon

这个东西什么用处呢?看下图和下下图的淘宝图标就是他的用处:
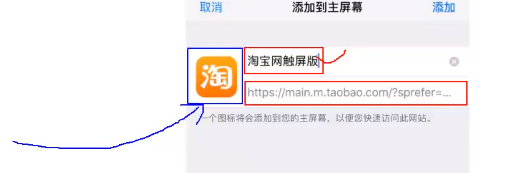

应用加壳
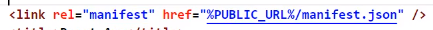
什么是应用加壳呢?
比方说我写好的web页面,套一个安卓的壳,就伪装成了一个安卓应用,生成的就是一个apk文件:
同理ios的壳
这其实是一种跨平台技术,我开发了 web端网页 ,加个壳就变成了跟手机app差不多的一个东西,虽然点击这个app打开的实质上还是网页,只不过伪装了,把它弄得像一个手机app
manifest.json
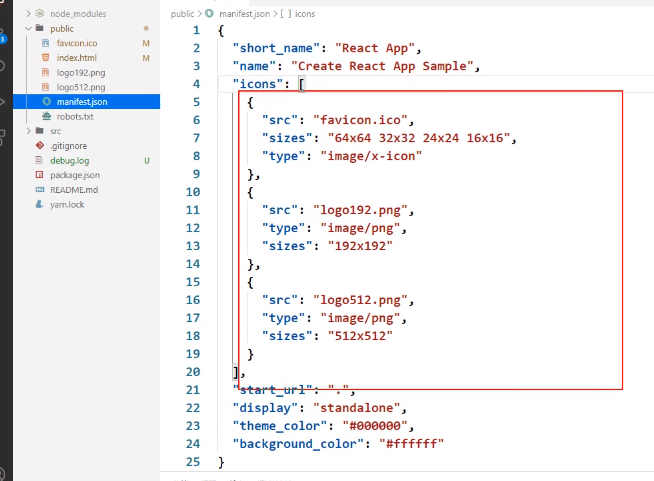
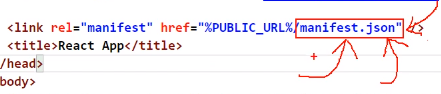
如果要做应用加壳,那手机里面的类似于打开一个新的app弹出你是否要给予xxx权限给该app 这种东西,反正就是所有手机里关于该app所涉及的文字、图片等都需要通过这个manifest.json文件来配置,当然如果不做应用加壳,这个文件是没用的
noscript标签

robots.txt
规定爬虫哪些东西能爬哪些不能爬
src文件解读
React.StrictMode

包裹了这个东西之后能帮我们检查代码里面有哪些语法不对的地方,比方说我们写了一个 ref = “”,这个语法都要弃用了,那他就会警告我们
reportWebVitals
记录网页性能

setupTests
做组件测试的
配置代理
方式一:
直接在package.json中配置:
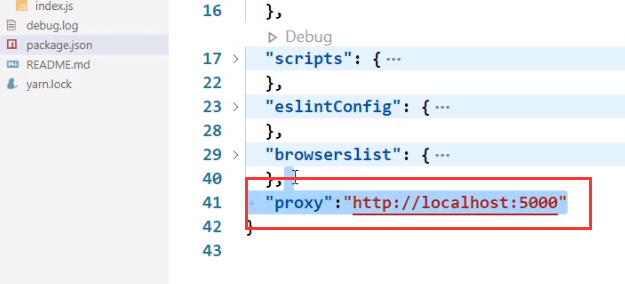
这样配置假设我们的react端口是3000,那他通过3000端口发送的东西会被转发到5000端口
方式二★:
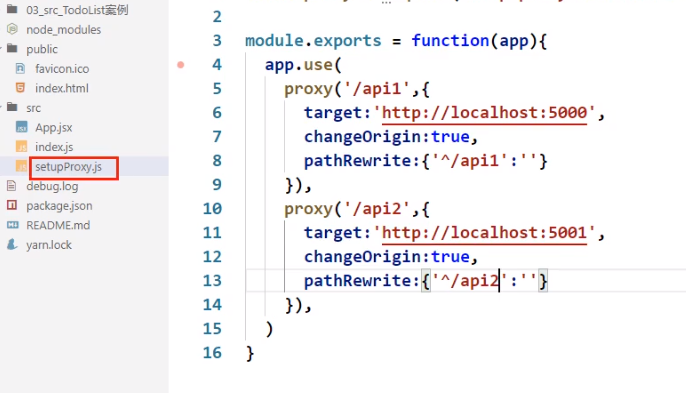
建立一个setupProxy
解释一下这个/api1:
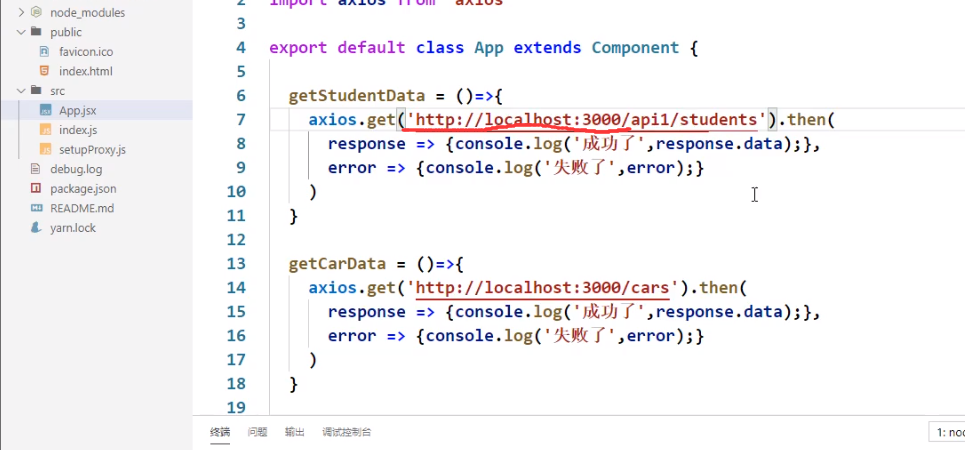
首先请求的时候http://localhost:3000这个前缀其实就是本机,所以如果请求http://localhost:3000/students,他会先去本机当前项目中的public文件夹(根目录)找students,如果有就不会发送请求,直接返回本机数据,但如果没有,才会去发送数据。
其次,setupProxy中配置/api1的意义是当请求的前缀是/api1的时候就转发到5000端口,因此我们必须这么请求:http://localhost:3000/api1/students,这样才能符合要求,但是真正的请求是http://localhost:3000/students(服务器上写的接口url是 /students),所以这才有了setupProxy中的pathRewrite属性,他将请求中的/api1替换成空字符串了,这下它既能匹配到/api1,又能在服务器端请求/students,一下就解决了这个问题
跨域问题
如果我们希望网站被别人访问而不发生跨域问题,可以通过在后端加上特殊的响应头 cors 就可以了
fetch
fetch关注分离(将过程细化)
一般来讲我们请求数据如果路径不合法就会直接报错,但是fetch不会,因为它遵循关注分离,对于fetch来讲请求数据跟连上服务器是两码事
所以fetch的第一个.then是去连服务器的,先告诉你连没连上
第二个.then才去取数据
所以使用fetch可能会发生:
路径不合法也会告诉你连上服务器了,之后再告诉你404请求数据失败
给箭头函数加async
直接加就行了

history
浏览器中的history的API不好用,可以去下一个包:https://cdn.bootcss.com/history/4.7.2/history.js
里面有两个方法:
-
createBrowserHistory()
该方法使用H5推出的history上的API

-
createHashHistory()
该方法使用hash值,类似于锚点跳转(跳转后浏览器有记录,但不刷新页面,而且节点前面都带一个 # ):


这两个方法都可以使用push、replace等api跳转页面(注意页面是不会发生刷新的)
监听
使用history.listen监听,如果页面发生跳转就会被监听到

router
参考:https://blog.csdn.net/qq_45677671/article/details/116168250(【React】路由详解)
BrowserRouter与HashRouter
react中有两个router:
-
BrowserRouter
事实上这个router就对应了上面history中的createBrowserHistory()
-
HashRouter
事实上这个router就对应了上面history中的createHashHistory()
区别:

跟history的createBrowserHistory()和createHashHistory()一样,HashRouter多一个#:
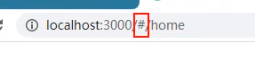
注意:#后面的资源都不发送给服务器
比方说上图,后面这个/home就不会发送给服务器
navlink
比起link,navlink有activeClassName属性,点击哪个标签,哪个标签就加上某个属性高亮
navlink包住的value其实也是某种意义上的props:

效果:
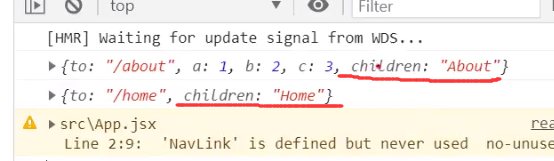
我们可以看到它自带一个children属性
因此我们也可以给他指定children来指定他的标签文本内容:

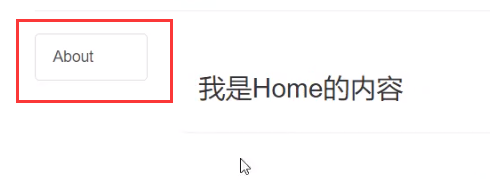
switch
匹配到一个路由之后就不会再往下匹配了,提高了效率
路由模糊匹配
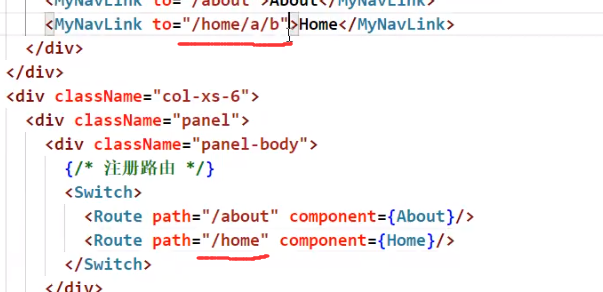
route中路径少了没问题,这是模糊匹配,如上图
但是如果反过来route多了那就不行了
精准匹配
给route添加exact属性:
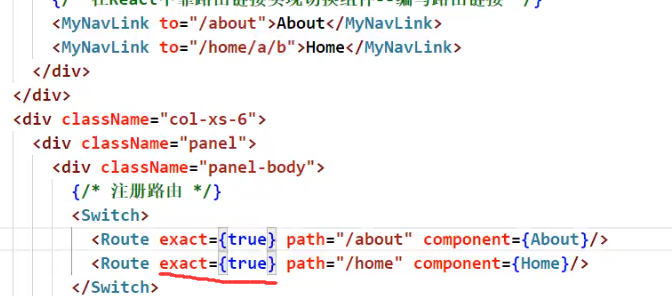
也可以省略{true}:
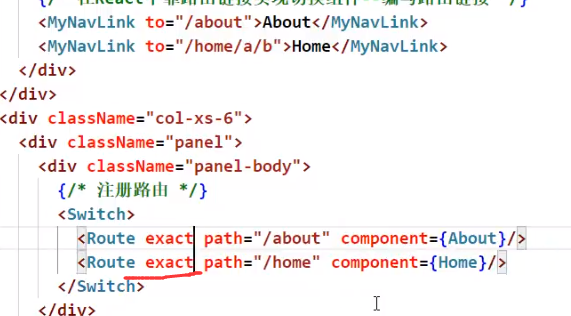
模糊匹配和精准匹配使用原则
能用模糊就用模糊,只有模糊出问题了(比方说好多东西都往一个页面跳),再去使用精准匹配
其他路由参数
除了exact,还有很多其他路由参数,比如:sensitive、strict等,具体请参考:https://segmentfault.com/a/1190000014294604
嵌套路由
注意下图两块高亮的地方:

为什么点击了 “Message”按钮 “Home”还是高亮呢?
首先Message是在Home下的二级路由,我们点击Message,触发的路由路径是:

路由的匹配是按照注册顺序来的
所以他会去父亲那里找/home/message,由于是模糊匹配,父亲的/home被匹配到了:

这次匹配就是下面这两块东西没丢的原因:

然后由于/home匹配到了,react挂载了Home组件,又会开启Home下的路由匹配:
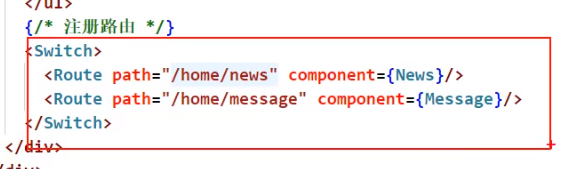
这回匹配到的就是/home/message了,因此Message会高亮
精准匹配的问题(嵌套的二级路由失效)
这就引出了精准匹配存在的问题:
如果是精准匹配的话在第一次匹配的时候由于路径都不符合,相当于匹配不到,就不会再往下匹配了,导致了这种效果:
点击Message之后页面变这样了:
跳转到Redirect的页面上去了,这里我们设置的Redirect中to指向的是"/about",因此他由于精准匹配的原因什么都没匹配到就走到/about页面去了
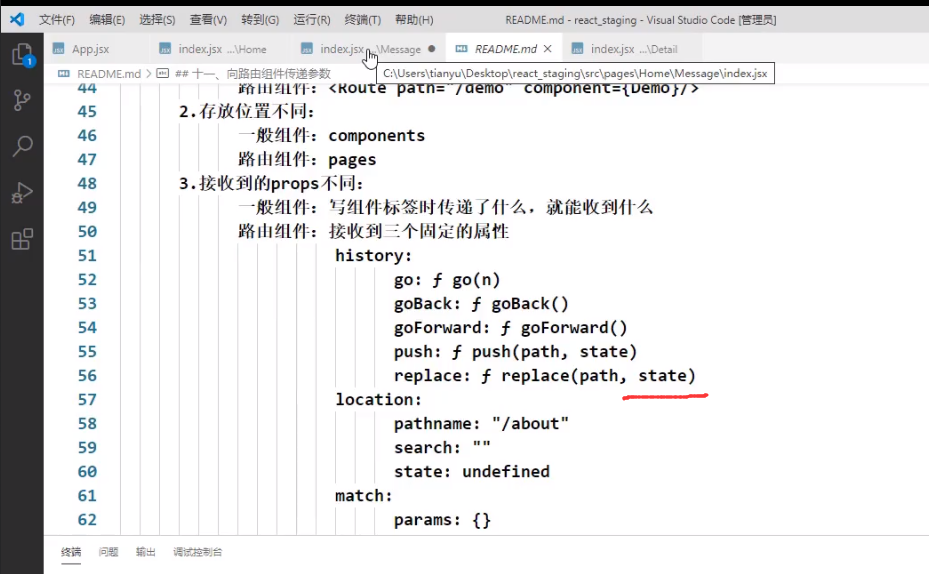
路由组件传递参数
首先route自动传递了一些props:

路由组件传递参数的三种方法:
- params(match对象)
- search(location对象)
- state(location对象)
具体的去看代码总结
要注意的是只有state传的参数不会体现在url后面
那就有一个问题了:刷新页面state传的参数会消失吗?
答案是不会,因为我们用的是BrowserRouter,他有某个API :history.xxx会维护history,而state是保存在location中的,而location又是保存在history中的,因此刷新页面参数不会丢
但是当我们把历史记录清了,再次刷新页面他就不行了:
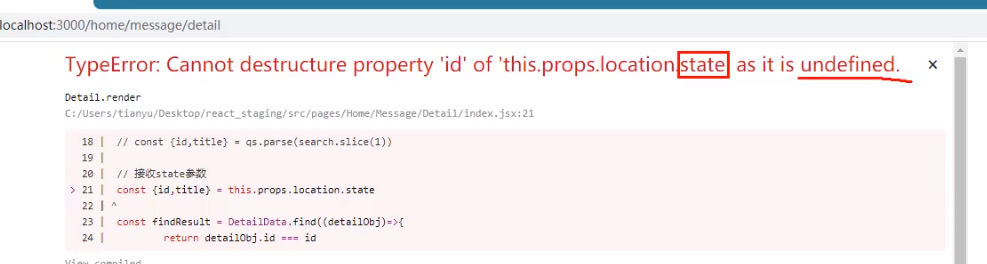
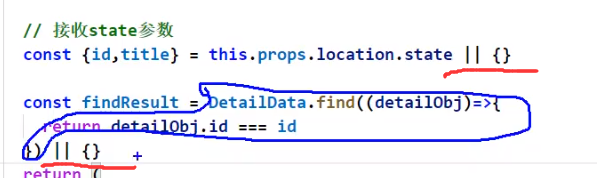
那至少让他不报错呗:
withRouter
哪个一般组件需要使用路由组件函数就在哪个组件下引入并使用withRouter
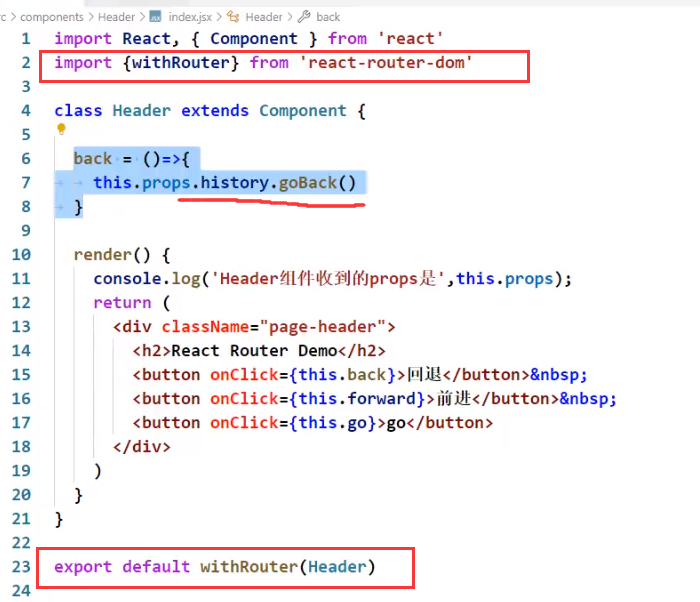
withRouter包裹一般组件,往一般组件身上加上了history、location、match这三个属性
注意,被withRouter包裹之后返回的是一个新组件
编程式路由导航
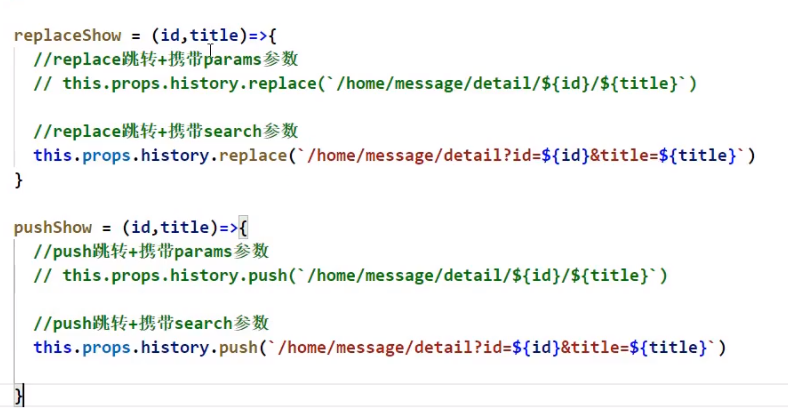
利用history完成路由跳转
注意上图这边这么写之后最好看看Link和Route那边需不需要对应的修改,尤其是Route
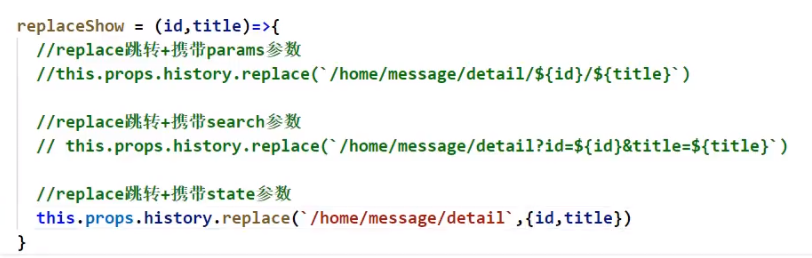
那么怎么用编程式路由导航实现state传参呢?
其实history上的API都已经给我们准备好了,如上图
注意:
只有路由组件的props里面才有history、location、match这几个对象,一般组件中是没有的
所以在一般组件中无法调用诸如replace、go、push等只有在history中才有的函数
vue中就没有这些顾虑了,没有什么一般组件和路由组件之分,因此都是可以使用history中的东西的
那react中如何使用路由组件才有的函数呢?
用react-router-dom中的withRouter
link如何开启history的replace模式
link跳转的时候默认是history的push模式
那怎么开始replace模式呢?
添加replace={true}

也可以直接写replace:

多级路径下解决样式丢失问题

我们给path加个前缀 /atguigu
第一次访问页面没问题,第二次访问页面bootstrap样式请求错误
原因就在于请求bootstrap资源的路径里面也给加上了/atguigu前缀:
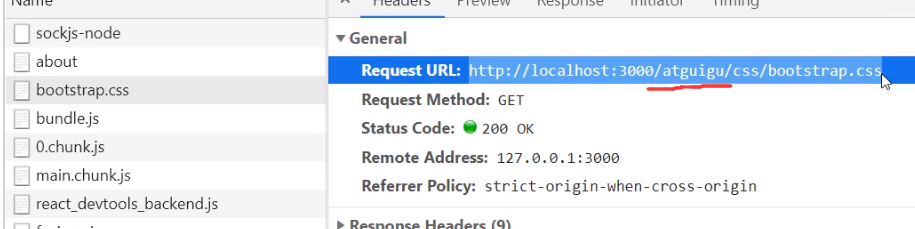
解决方法:
-
修改index.html中样式link中href的相对路径的写法
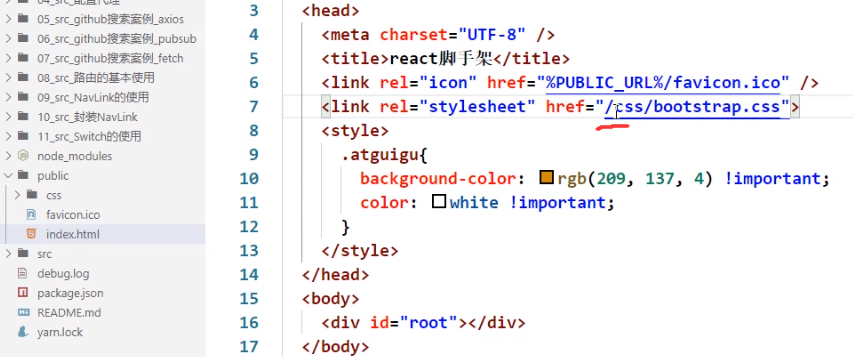
去掉了前面的 ‘.’
-
写%PUBLIC_URL%前缀
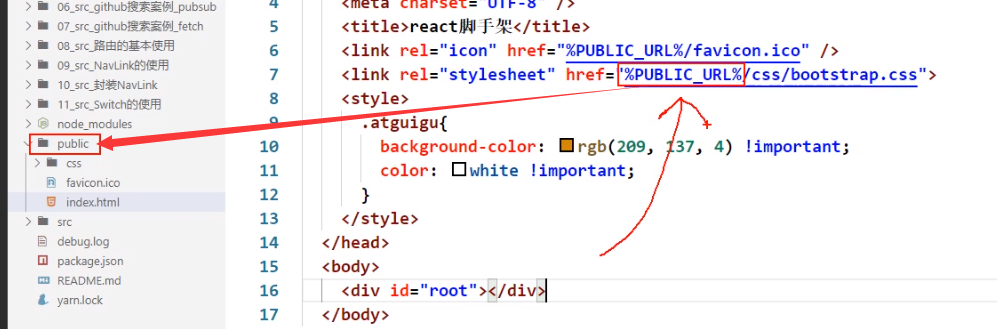
-
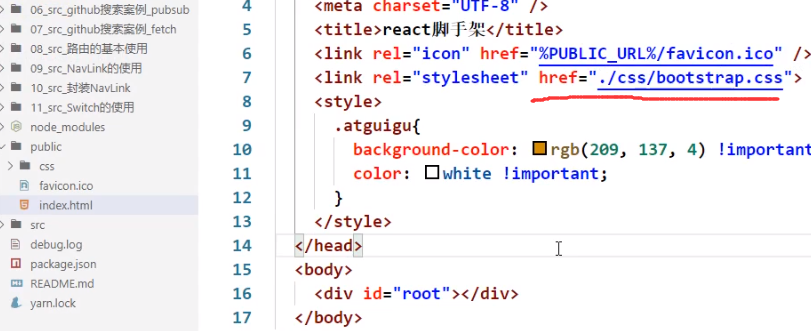
我就想写./css/bootstrap.css这种相对路径的写法
那就要到入口文件中把BrowserRouter改成HashRouter:
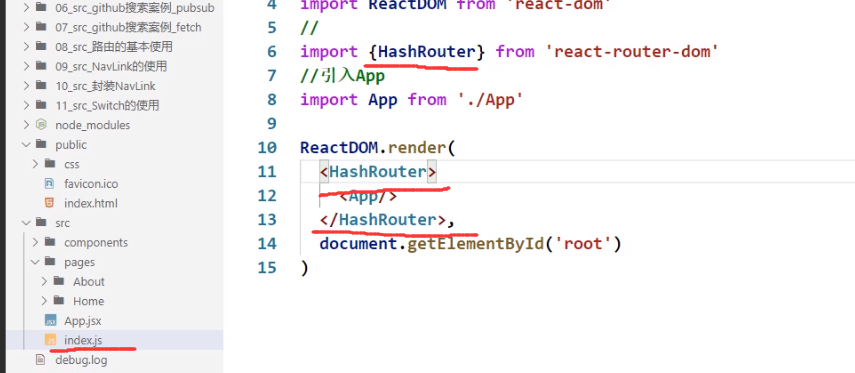
原理:
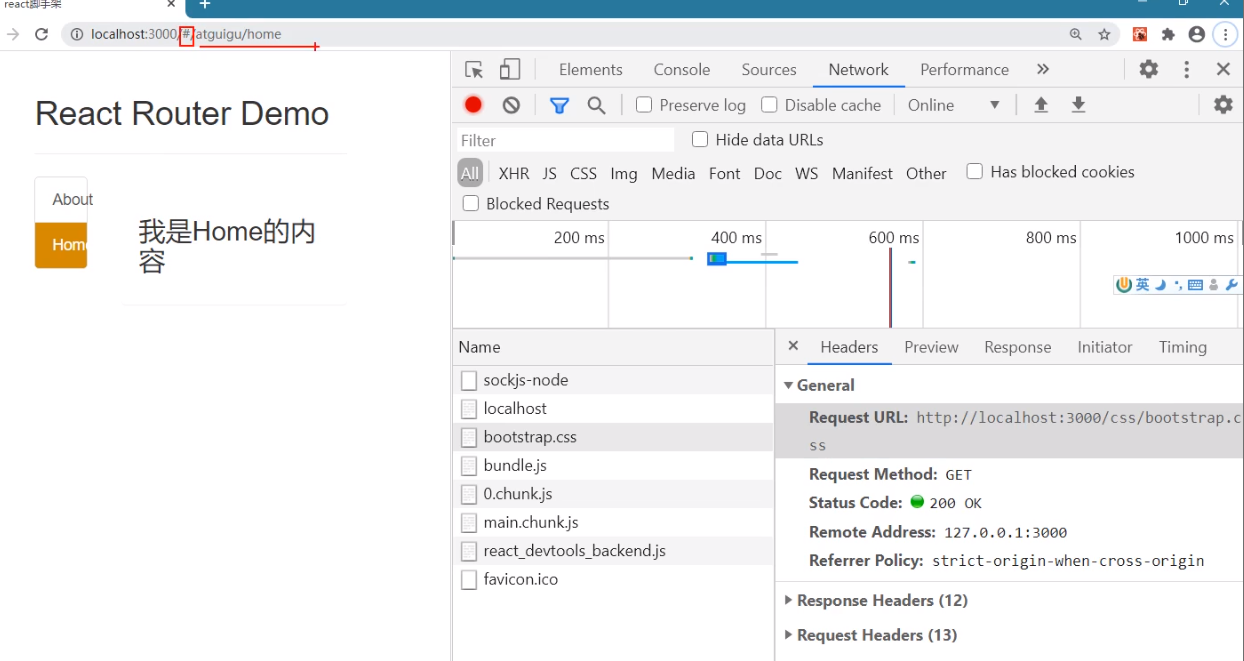
hashrouter我们说过会带一个 “#”,而“#”后面的东西都不会发给服务器(自动忽略了,他会认为“#”后面的是前端的资源)
所以不管传了什么路径,他都无视,直接请求 “#”前面的,在这里也就是localhost:3000
模板字符串在render中报错的原因
因为模板字符串是js的东西,所以要在外面加一个大括号:

暴露核心配置(eject)
在执行了create-react-app命令之后
执行yarn eject

纯函数

纯函数特征之一:传入同样的参数,必定得到同样的输出,比方说函数demo(3)返回2,那下次再传入3,demo(3)的返回一定还是2
纯函数特征之二:不能修改传入参数的值
纯函数特征之三:不能发送网络请求、输入输出设备等不靠谱的东西(返回的东西说没就没的那种)
纯函数特征之四:不能调用第一次调用和第二次调用返回的值不一样的东西,例如Date、random等
redux中的reducers中不可以直接改preState的值,那是因为他底层有个浅比较,比较preState的地址,如果地址一样就不进行更新,所以如果preState是一个数组,而我们直接通过插入元素的方式修改preState:
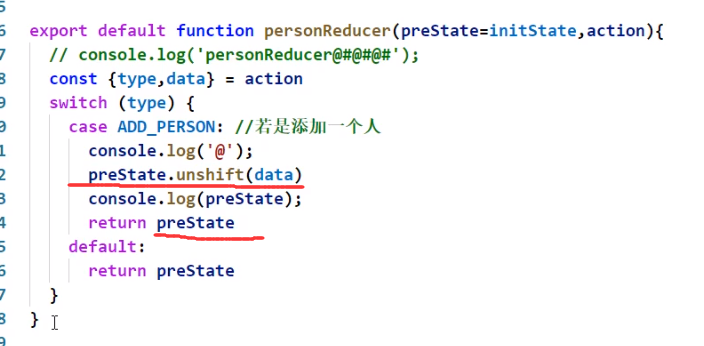
这个时候preState的地址是没变的,意味着他不会进行更新,但是preState里面的值确实变了
而且上述写法也使得reducers不再是一个纯函数了
所以不要直接修改preState
正确写法:

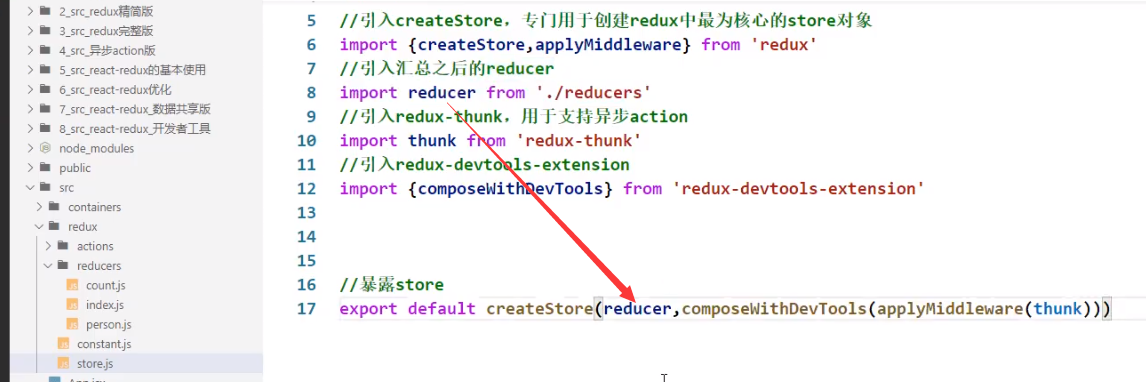
Redux DevTools
在浏览器下载这个插件之后再使用yarn下载redux-devtools-extension

如何使用:
去redux的store中:
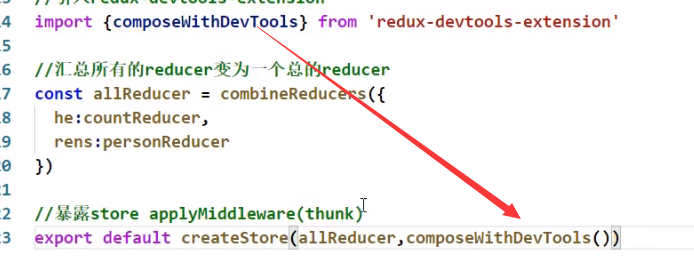
如果我们有其他异步组件就这么写:
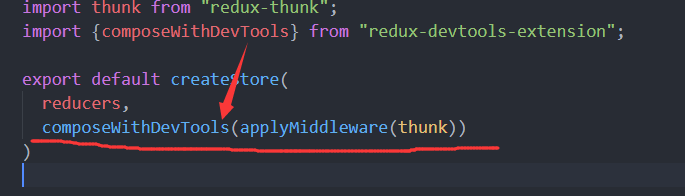
在App外面包一层<Provider store={store}><\Provider>的原因
是为了让App的所有后代组件(包括App)都能直接收到redux的store
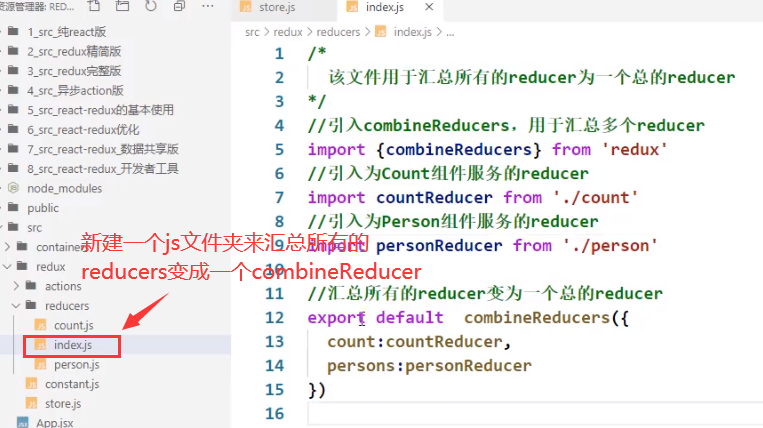
优化
redux的store里面不单独引入reducers,只单独引入combineReducer,为此我们需要建立一个新的js文件来将所有的reducers汇总成一个combineReducer:
部署
运行npm run build,将生成的build文件放到后端,指定spring的静态资源路径,然后配置nginx即可