The article contains the knowledge of Scrapy…
Code in GitHub: scrapy

crawlSpider


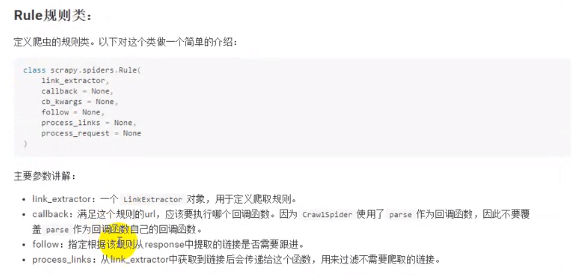
注意follow只会跟进当前显示页面符合规则的网页,如果当前显示页面下面的页码只有1、2、3、4这四页,那么他就只会跟进这四页而不会跟到第五页
Scrapy shell

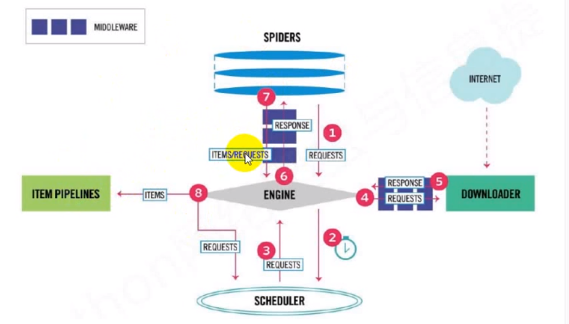
Request

Response


模拟登录
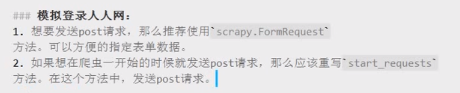
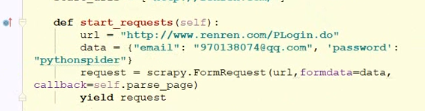
豆瓣登录模拟
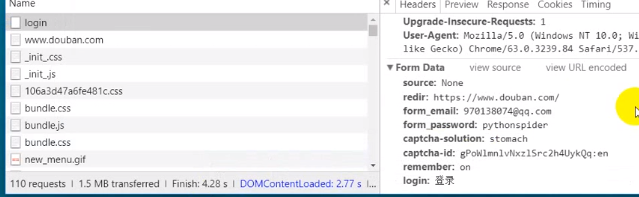
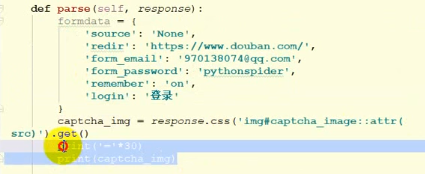
图形验证码识别平台

根据验证码平台的提示制作formdata
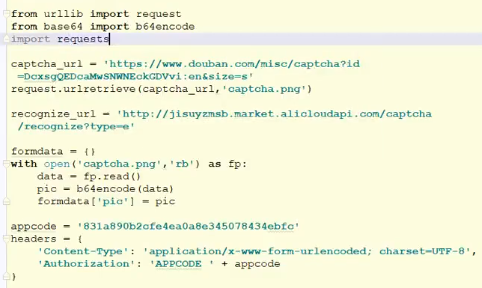

为formdata指定空返回函数

使用scrapy下载图片
Files pipeline和images pipeline



下载器中间件

注意,如果process_request返回的是response,那么它将直接执行process_response而不执行下一个中间件
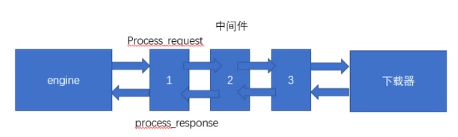

注意,如果process_response返回一个request,那么它将转给下载器下载
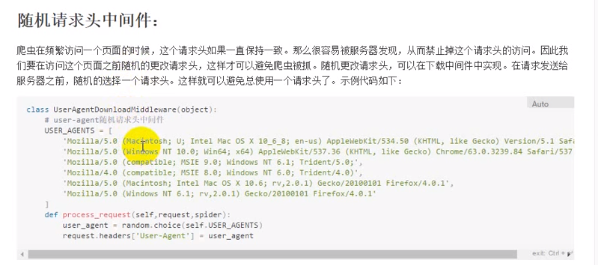
随机请求头
购买ip代理池

私密代理设置

分布式爬虫
参考:https://blog.csdn.net/weixin_42622084/article/details/81434854(scrapy-redis实现分布式爬取:原理,实战案例(虚拟机))、https://www.jianshu.com/p/6e3eb50fe2b8(网络爬虫)、https://blog.csdn.net/zwq912318834/article/details/78854571(scrapy-redis分布式爬虫的搭建过程(理论篇))、https://segmentfault.com/a/1190000014333162?utm_source=channel-hottest(scrapy-redis分布式爬虫框架详解)

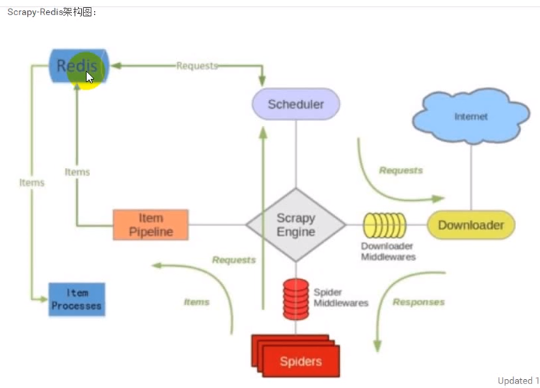
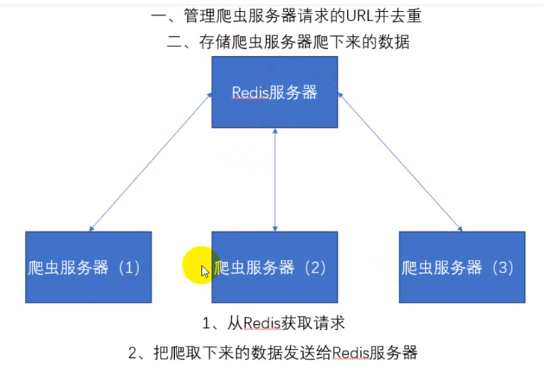
Redis不仅有URL去重还有存储爬下来的数据的功能
虚拟机下载必要文件

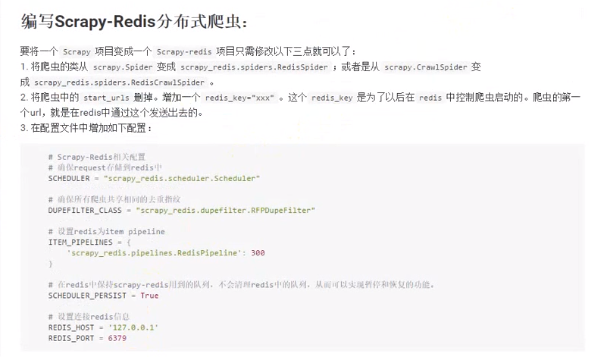
开始分布式爬虫

Virtualenvwrapper指定python版本
有时候我们使用pip install -r requirements.txt命令时会因为python版本不对导致下载失败,当我们确定python3的目录之后使用virtualenvwrapper 的mkvirtualenv -p /usr/bin/python3 GP1即可创建python3的虚拟环境,之后再进行安装即可
Yield时通过meta传递参数
