The article contains cache, message, security, searching, actuator, deployment…
缓存
JSR107


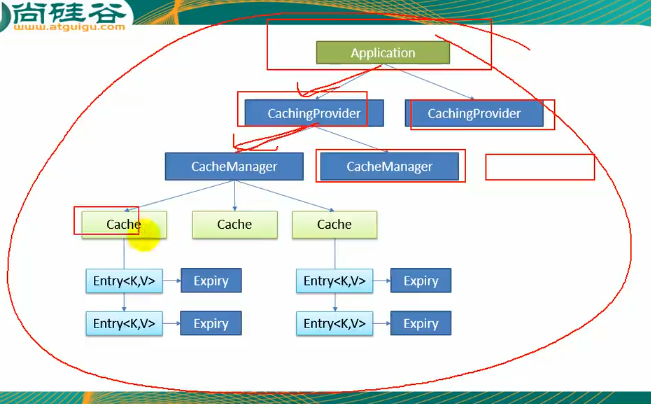
每一个cache缓存的内容是不一样的,可能第一个cache放的是员工的信息,第二个就是专门放商品的信息
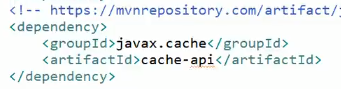
要使用JSR107我们需要引入下面的包:
Spring缓存抽象
JSR107复杂度高,因此一般用的都是Spring缓存抽象

重要概念与缓存注解

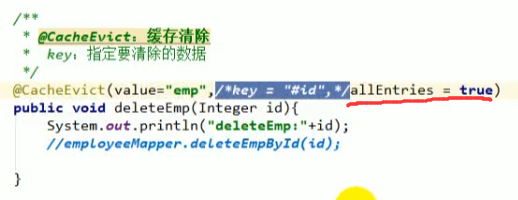
@CacheEvict
删除某用户之后,数据表中该用户就会被删除,按理来说缓存中也要删除这个用户,这个时候可以用这个注解
allEntries
这是@CacheEvict中的一个属性,默认为false,表示只删除相关的内容的缓存,如果设置为true表示将缓存中的所有数据全部删除:
beforeInvocation
默认为false,代表是否要在方法执行之前执行,有些时候方法执行可能会出错,出错之后程序就中断了,缓存中的删除就不会执行,这个时候我们可以指定beforeInvocation为true,就能实现即使我的方法执行中断了,但是我缓存中的数据还是成功删除了。

@CachePut
用户更新之后,缓存中也跟着更新。
该注解既能保证方法被调用,又可以使得结果被缓存,因此常用做缓存更新
@CachePut和@Cacheable的区别
@CachePut标注的方法一定会被调用,调用完之后的数据会被重新放入缓存中,而@Cacheable标注的方法不一定会调用,第一次的时候缓存中没有数据,那么会调用方法,而第二次缓存中有数据之后,该方法就不会调用了。
并且要注意两者的运行时机:

CachePut是先调用方法,并返回结果,再存入缓存
@EnableCaching
如果要使用上面的三个注解,我们必须使用@EnableCaching开启基于注解的缓存
而且缓存过程中会涉及两个问题:
-
keyGenerator,缓存数据时key的生成策略;
-
serialize,缓存数据时value序列化策略
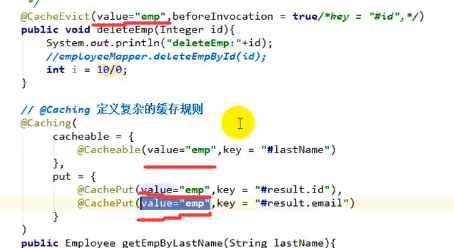
@Caching
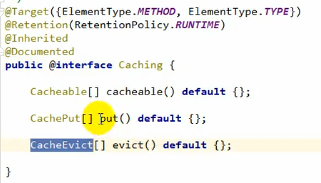
@Caching是@Cachable、@CachePut、@CacheEvict三个注解的集合体,当遇到复杂的缓存规则的时候就可以用@Caching,例如:

这里我们分别用id、email、参数中的lastName作为缓存的key
注意:这个时候如果我们用id、email去查数据,是可以直接从缓存取数据的,但是如果我们再用lastName去查(也就是上图的方法)的话,他还是会去数据库查一遍,原因是该方法的复杂注解里标明了@CachePut,会导致每一次调用该方法都会先去数据库查数据。
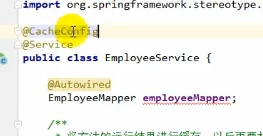
@CacheConfig
我们发现每一个cache注解里面都要写一遍value=“xxx”,太麻烦了,因此我们可以给这些方法所在的类上加一个@CacheConfig注解
这个是缓存配置
那么这个缓存配置里面有哪些可配置呢?
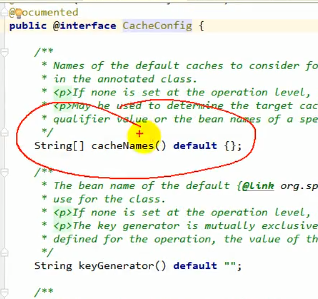
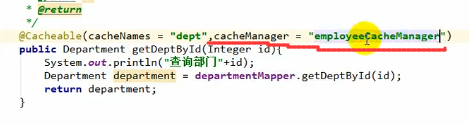
那么我们给它写上cacheNames=“emp”:

这样的话该类下面的方法只要想用这个名为emp的cache,都不需要再写value属性了:

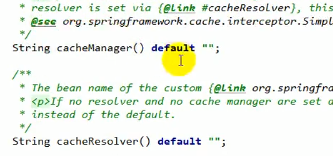
属性CacheManager
可以在@CacheConfig中配置,表示指定全局的CacheManager,也可以单独给每一个方法配置CacheManager
缓存注解中可以写的SpEL表达式

所以上上图注解中的key还可以写成这种形式:

指定同一数据多个缓存

这个时候key里面就可以写#root.cache[1].name来使得key获取第二个缓存的名字,使用#root.cache[0].name来获得第一个缓存的名字
#a0、#p0、#root.args[0]、#参数名以及不写key时的默认给定值
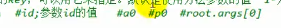
#a0、#p0、#root.args[0]中的 0 表示参数的索引,因此他们都表示第一个参数,所以#a0、#p0、#root.args[0]其实是同一个东西
另外,默认不写key的时候也是用传入的参数的值作为缓存的key
例如,上面我们有个案例,方法的形参传入为id值,因此缓存注解的key值用SpEL来获取的话#a0、#p0、#root.args[0]、#id以及默认不写key都能获取到传入的形参id的值。
#result
返回方法的返回值
原理
进入到CacheAutoConfigration.java

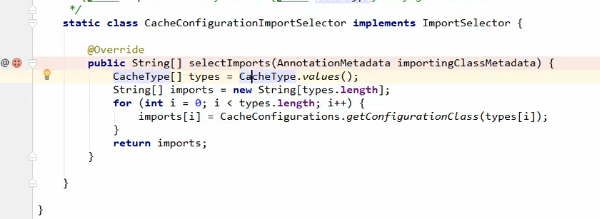
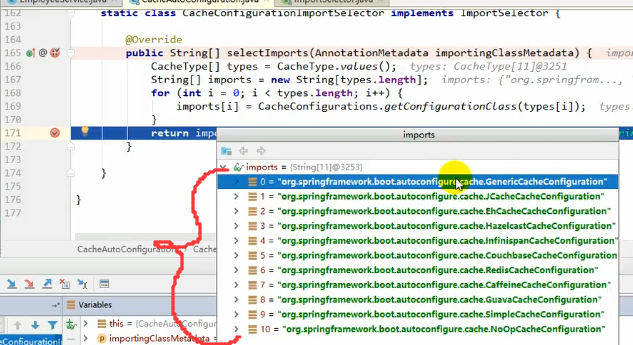
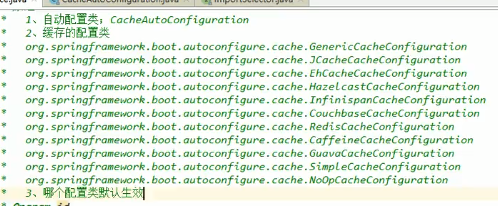


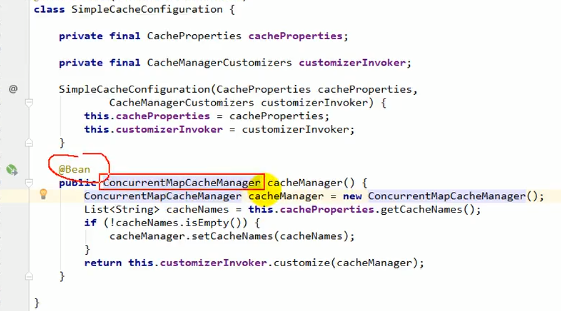
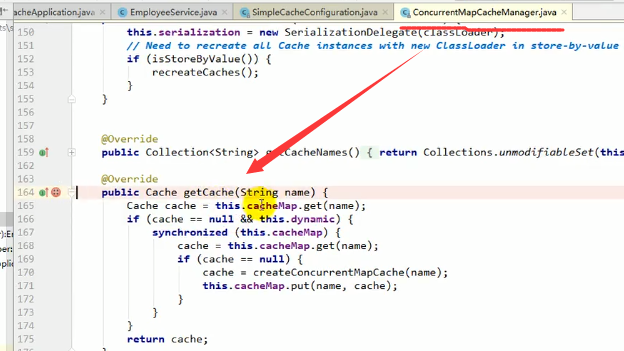
总的来讲就是:
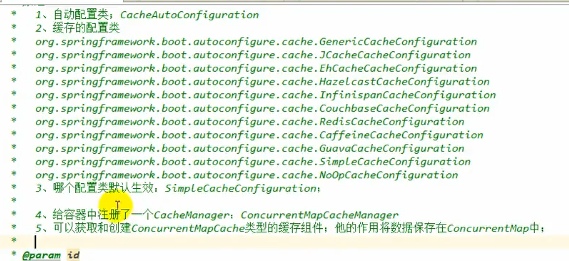
运行流程

案例
@Cacheable

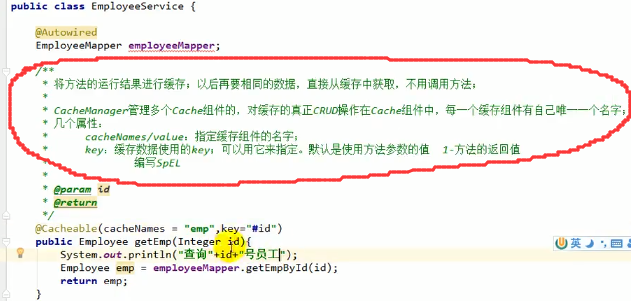


注意,这个key里面可以写SqEL表达式,如上图的@Cacheable注解中的key,上图这么写表示缓存的key/value中的key为传入的形参中的id
当然我们还可以将key设置为我们想要的格式:
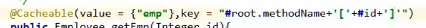
注意:当我们使用sync=true的时候表示开启异步,这个时候数据会被异步输入缓存,默认是同步的,异步会有一个问题就是unless会用不了
@CachePut

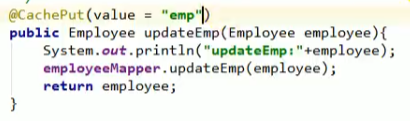
这里放入缓存的key默认是employee对象,而上面查询时放入缓存的key默认是id,这就会导致虽然数据在数据库中改了,但是缓存中没改,导致再次查询的时候显示的值没变
我们可以做出如下更改:
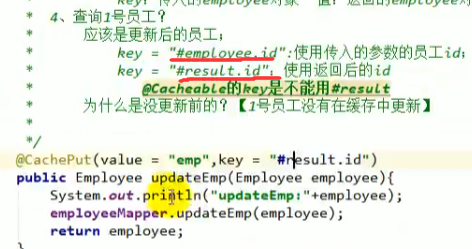
可以指定key为#employee.id,也可以指定key为#result.id
注意#result.id只有@CachePut里面可以用,@Cacheable不行,那是因为@CachePut先执行方法,获取返回值之后再将返回值放入缓存,因此他天然的有result,而@Cacheable在执行方法之前就要先去缓存中查找key,而此时并没有result。
@CacheEvict

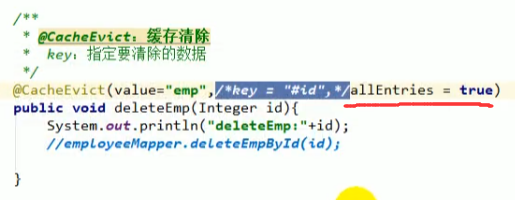
注意,@CacheEvict有一个属性叫allEntries默认时false,如果改为true表示把缓存中的数据全删了。
除此之外@CacheEvict还有一个beforeInvocation,上面介绍过,默认为false,设置为true的时候将指定缓存中的所有数据全删。
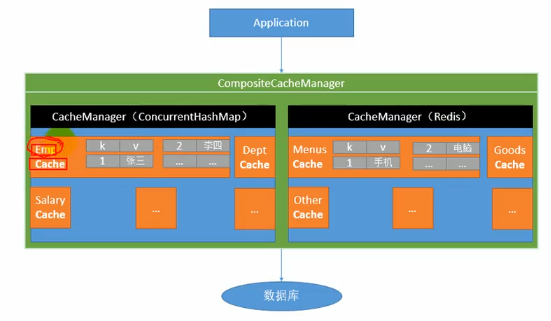
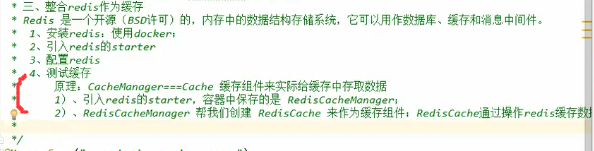
整合redis作为缓存


由于Springboot的缓存组件时按顺序加载的,并且有一条很重要的判断条件是如果容器中没有CacheManager时才能启动组件,因此当我们引入并配置了redis之后,容器中就有了RedisTemplate,导致RedisAutoConfigration起作用,而他其作用之后容器中就会new进去一个RedisCacheManager,从而导致之后的SimpleCacheConfiguration由于容器中已有CacheManager而不起作用了:
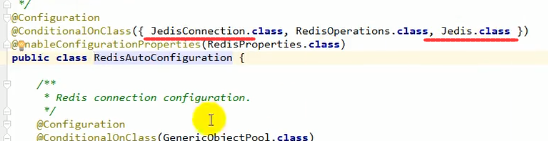
我们看该类的下面:
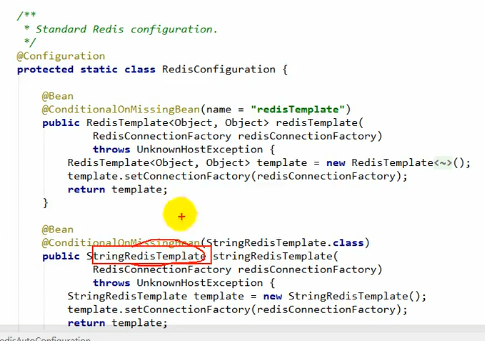
有两个template被加到组件里面了,他们两个就是用来操作redis的
其中RedisTemplate是obj:obj
而StringRedisTemplate是用来简化字符串操作的

要用redis缓存,直接引入上面那两个东西就好

StringRedisTemplate的操作如上所示,RedisTemplate的操作跟他是一样的,只不过上面说了,一个是obj:obj,一个是str:str
用法:
我们给员工实体类添加序列化功能:
然后测试保存对象:
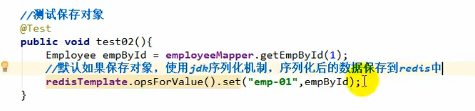
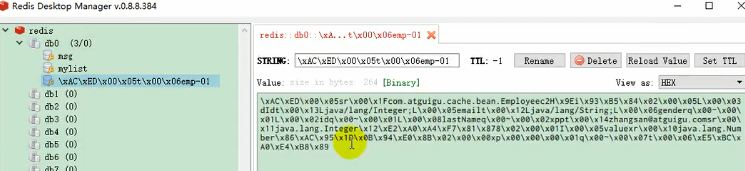
保存的都是jdk序列化机制序列化之后的数据
那么怎么才能保存我们想要的格式的数据呢?
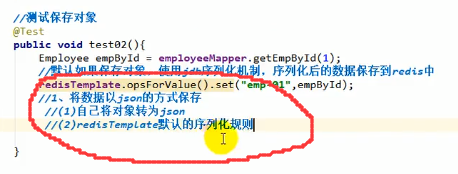
第一种方式不用多说,直接json转换(fastjson)
来看看第二种:
redisTemplate自带了一些序列化:
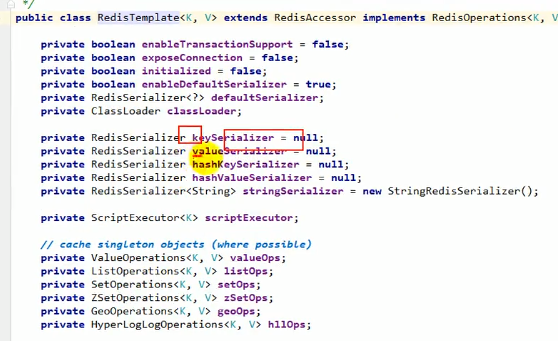
而他默认用的序列化器是jdk的序列化:
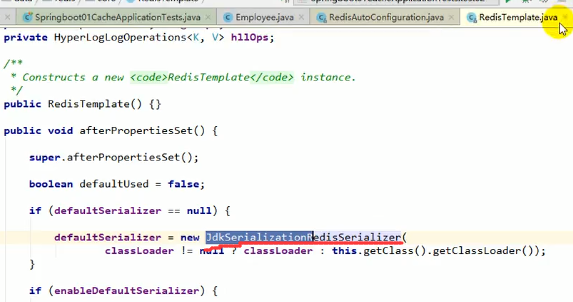
现在我们来自己写redisconfig,仔细看下面的图片步骤:

直接重写RedisTemplate
之后给template设置默认序列化器
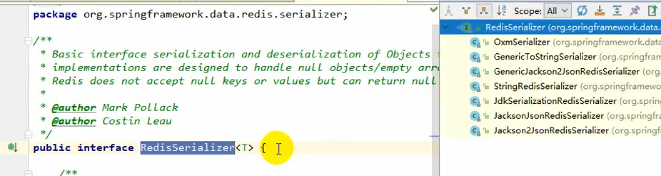
在确认了需要传入的序列化器为RedisSerializer的实现类之后,我们去找RedisSerializer,并ctrl+h,即可看到他所有的实现类,之后随便选一个传入template:
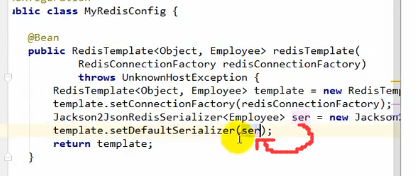
之后用的时候注入我们自己写的RedisTemplate:

测试缓存

定制RedisCacheManager:

当我们自己写了RedisCacheManager之后容器中就有了CacheManager,会导致RedisCacheConfiguration不会启动:
之后我们来看一下效果:
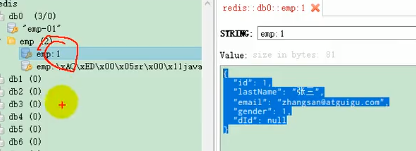
这里emp:1中的1是因为配置的@Cacheable里面的key我们没有指定,那就是默认传入的参数就为key,而参数就是id,所以他是1
可以发现这个key里面多了一个前缀 emp:
那是因为我们配置了使用前缀:
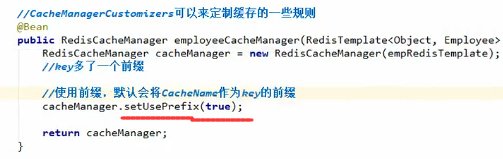
这样的话即时有多张表的内容需要缓存,key也不会冲突
现在再来测一个:

结果第一次查数据是没问题的,但是第二次就报错了,那是因为我们自己配置的RedisCacheManager里面第二个类型指定的是Employee

所以就很离奇了,他能存入缓存,但是不能将缓存中的内容反序列化回来
解决方法就是:


给department实体也写一个template和manager
指定使用哪个CacheManager
我们在每个实体的service层分别指定CacheManager
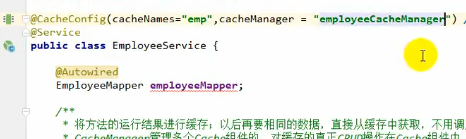
属性CacheManager
当然,除了上述的@CacheConfig配置之外,我们还可以单独给每一个方法配置CacheManager
@Primary(在多个CacheManager情况下指定主CacheManager或者叫默认缓存管理器)
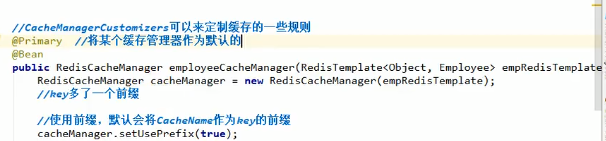
这里我们指定employee的这个CacheManager为主CacheManager,不设置的话会报错
注意,由于设置了默认的缓存管理器(employee的),因此在EmployeeService中我们就可以不指定他的缓存管理器了,因为默认就会去用employee的缓存管理器:

当然,实际情况下我们应该将系统自带的,也就是那个obj:obj的缓存管理器作为默认缓存管理器,因为这个管理器更加通用
自己操作更加细粒度的缓存数据的存放与读取
有时候我们不希望直接在方法上面加一个注解来让系统给我们自动处理缓存,我们希望在方法内部的某一个位置,我要存一下数据或者读一下数据,这个时候就需要我们自己操作RedisCacheManager了
首先我们需要拿到RedisCacheManager(可以是系统自带的也可以是自己配的):
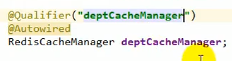
我们将他注入,注意这个变量名就是之前创建的RedisCacheManager的变量名:

另外,我们可以用@Qualifier注解明确表明我们选用的RedisCacheManager是这么多的RedisCacheManager中的哪一个,如上图所示
用CacheManager获取指定Cache
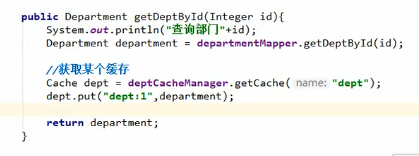
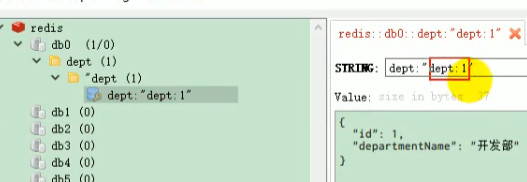
上图的第一个 “dept:”是之前设置的前缀,第二个“dept:”则是上上图中我们自己指定的
Spring Boot与消息


应用场景
异步处理
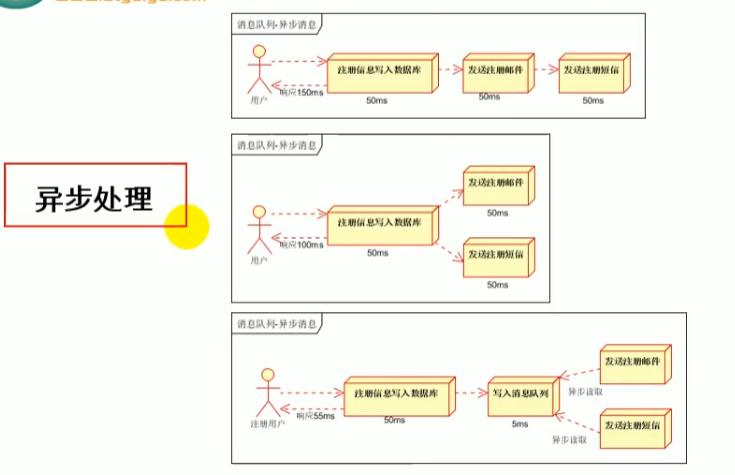
上图第三种是使用消息队列的,相当于注册信息写入数据库就直接写入消息队列之后就直接反馈给用户了,后续再来发送邮件和注册短信
应用解耦
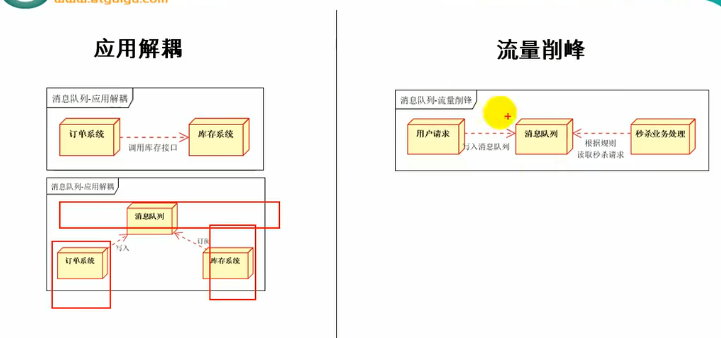
应用解耦相当于将订单系统和库存系统分开,订单以来就到消息队列里去,库存系统一看到消息队列有订单就进行处理
流量削峰
流量削峰:我有1000个商品,有100000个人来买,那就可以设置消息队列只收取1000个用户,1000个用户谁快谁先进队,超过1000个就直接抛弃请求,取消响应,之后业务处理模块再慢慢地从消息队列里面取出请求并处理
概述

两种模式
点对点式

点对点式就是发送者A发送请求到队列,接收者B从队列中取出请求
要理解只有唯一的发送者和接受者,但并非只有一个接收者这句话,意思是发送者确实只有A一个,但是我可以有B、C、D多个接收者等着取队列中的数据,但是最终这个数据只能被B或者C或者D中的一个取走。
发布/订阅式

上面的点对点是只有一个接收者最终能获得消息,现在这个发布/订阅式指的是当发送者A发出消息之后,B、C、D等接收者都能收到消息
消息代理规范
JMS

AMQP

JMS和AMQP对比
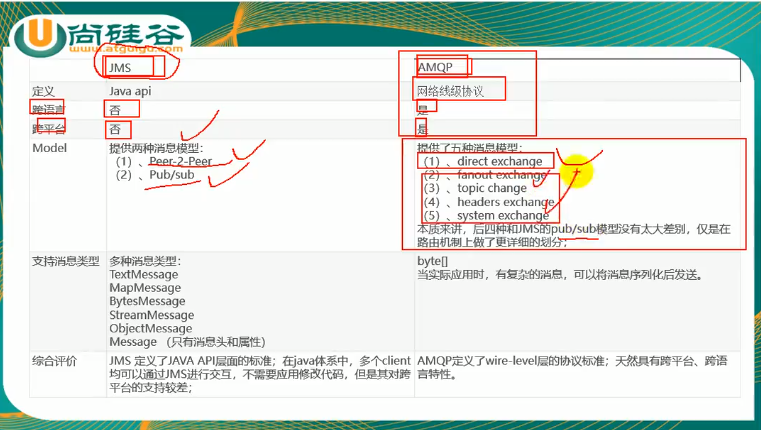
由于JMS是Java api,所以只有Java能用,但是AMQP是网络协议,所以跨平台

RabbitMQ


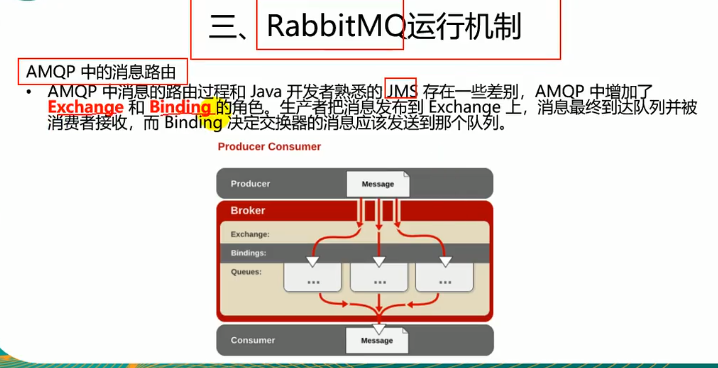
原理就是Publisher生成消息到消息服务器内的exchange,exchange通过binding与多个queue绑定,因此由exchange做消息的分发将消息分发到队列中去
注意,一个exchange可以绑定多个队列,一个队列也可以绑定多个exchange,如果一个队列绑定了多个交换机,那这些交换机都能往这个队列里面发数据
Channel:信道,如果每去一个队列里面去一次数据就要建立一次tcp连接那是非常耗费资源的,因此一般情况下是建立一条tcp连接,在这个连接中建立多个Channel通道,并由这些通道做真正的消息收发
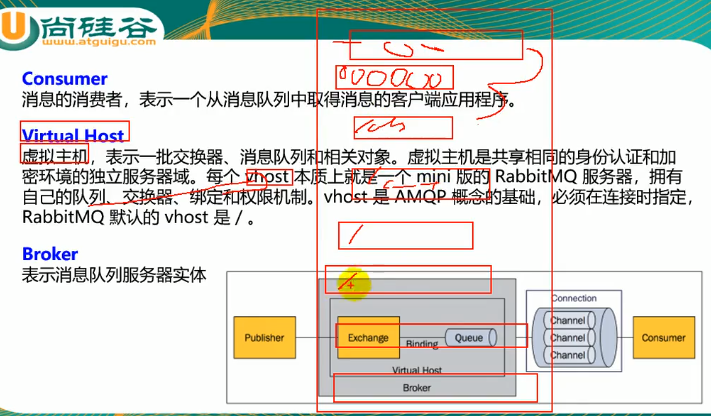
Virtual Host:相当于再RabbitMQ服务器里面建立多个虚拟的mini版RabbitMQ服务器,且他们之间相对隔离,每一个虚拟服务器都有自己的交换机、权限、身份加密信息、路由规则等等。连接RabbitMQ的时候必须指定虚拟主机,虚拟主机默认是按照路径来划分,可以是/ab,可以是/cd等等
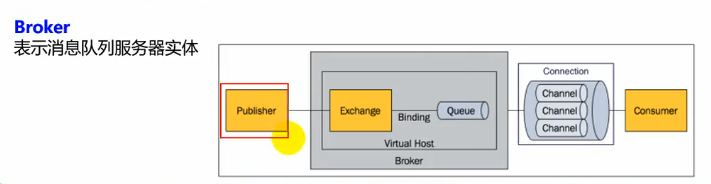
Broker
他就是我们的服务器实体
RabbitMQ运行机制
核心就是交换器和绑定的规则,这两个不同,消息的派发结果就不一样
Exchange类型

headers几乎不用了,不介绍
Direct Exchange(单播模式)

消息中由路由键,当路由键跟绑定的队列中的键名一样的时候就会分发给这个队列
注意它是两个键名严格一致的时候才会进行分发,比方说我们要发dog,两个键名都是dog的时候就会发,而dog.go、dog.wang都不会进行分发
Fanout Exchange(广播模式)
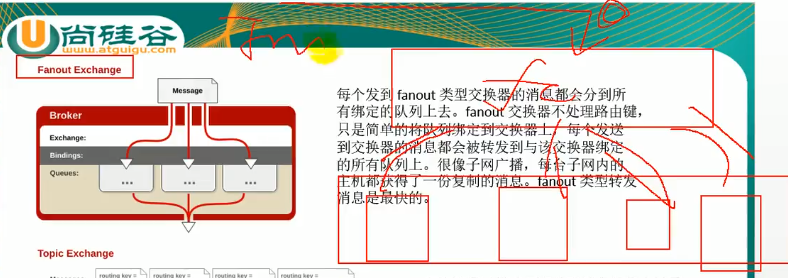
将收到的信息发送给所有绑定的队列,不处理路由键,速度最快
Topic Exchange(选择性广播模式)
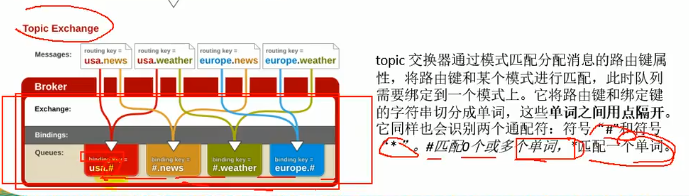
通过通配符模糊匹配键名进行分发
RabbitMQ整合

用docker run一个rabbitmq,注意pull一个带management的版本,这些版本带web管理界面
启动镜像:

5672端口是rabbit本身的,15672是管理界面的
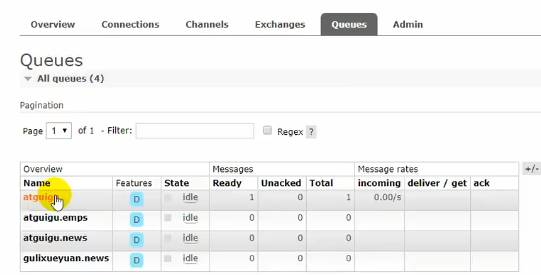
测试
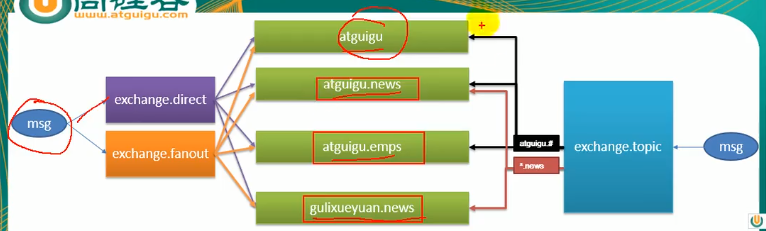
这里有四个队列,他们的队列名最终就是绑定的路由键的名称,我们看看消息到不同的交换机之后他们会被分发到哪
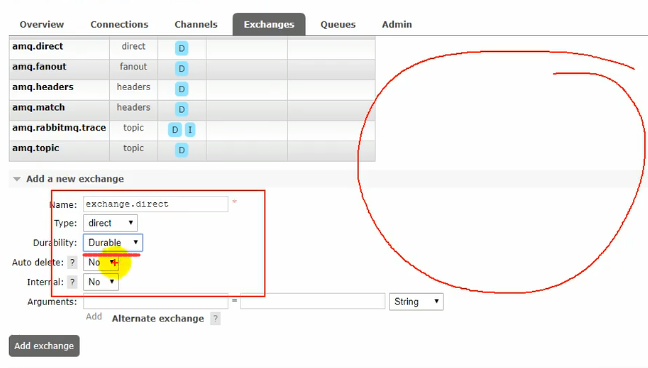
首先创建自己的交换机,这里的Durability是持久化的意思,开启之后就算关闭了RabbitMQ,下次开启的时候这个交换机还在
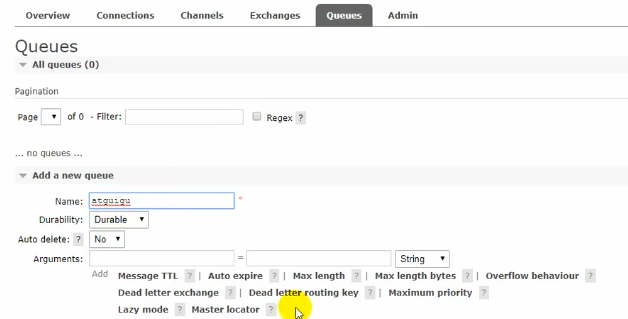
然后创建队列
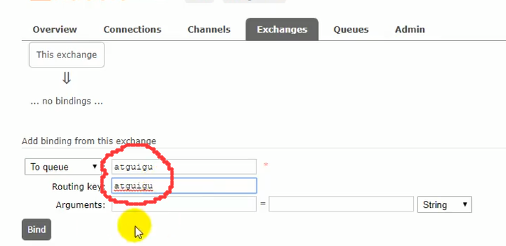
点击之前创建的交换器,进入页面后绑定队列
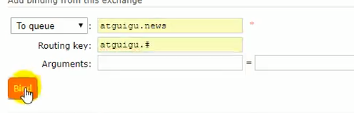
当然在绑定topic交换器的时候路由键应该写上通配符

之后开始发送消息进行测试
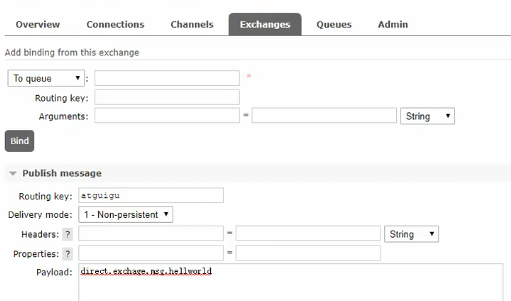
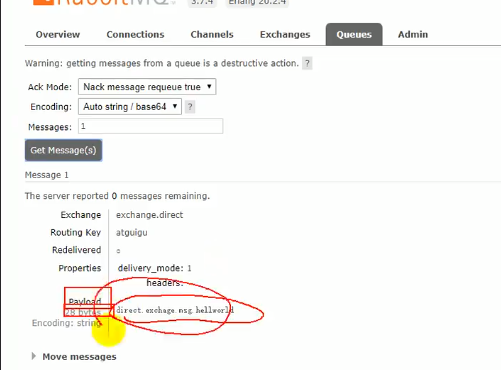
direct交换器发:
点对点,路由键完全匹配的队列才会受到数据
fanout交换器发:
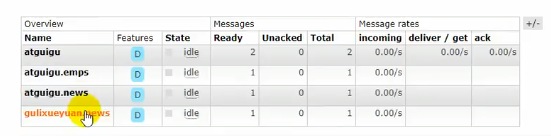
我们发现每一个队列都收到了
topic交换器发:
匹配到的会接收
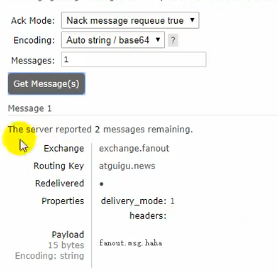
当我们到某个queue中去查看获取到的数据的时候,可以用上图的get message
我们发现每次获取的都是fanout发来的那个message,那是因为选择的ack mode不对,这个时候我们上图的第一行ack mode可以改成应答的模式,让queue每获取一个message就进行应答,这样的话就会把这个message给删了,我们也就能获取到后面的message了:
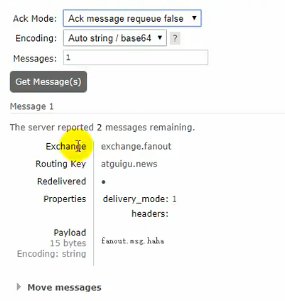
这个模式下我们可以获取后面的几个message
将rabbitMQ配置到springboot

具体怎么配看Properties文件
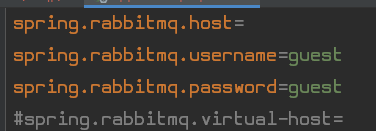
我们之前说一定要指定virtual-host,这里不指定是因为它默认就会给你一个virtual-host
使用RabbitTemplate发送和接受消息
发送数据

注意,当使用fanout模式的时候不需要指定路由键:

####### send
需要自己构造一个Message将消息序列化
####### convertAndSend
如果不牵扯到复杂的自定义,比方说自定义消息头什么的就可以直接用该方法
他只需要传入发送的对象,会自动序列化发送给rabbitmq

接收数据
注意,一旦接收了队列中的数据,该数据在队列中就不复存在了
####### receive
该方法可以获取指定队列的数据,并返回Message
####### receiveAndConvert
该方法可直接将数据以对象形式返回

如何将数据转为json发送到队列
之前发到队列里面的数据是一对乱码,原因是使用了默认消息转换器
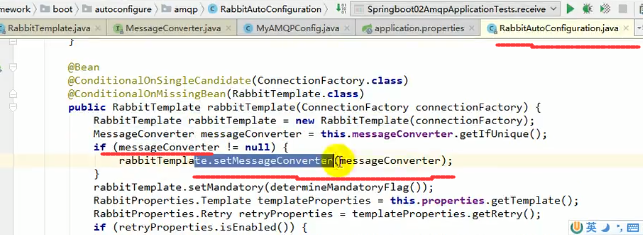
我们再看RabbitAutoConfiguration,如果有自己定义的MessageConverter,他也会把他加载进来,如上图
定制自己的MessageConverter
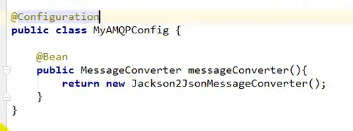
这里的Jackson2JsonMessageConverter是MessageConverter的实现类,fastjson的也有
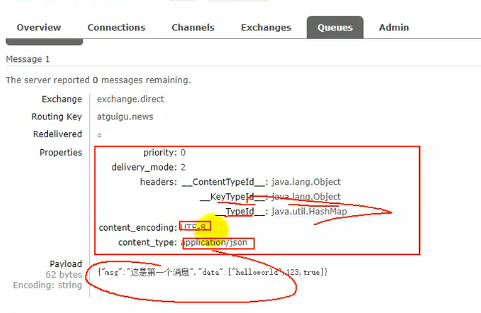
结果如上图,我们发现还有消息头
监听注解
之前说了订单库存模型,库存要一直监听消息队列,一旦有订单就处理,Springboot为了简化开发,引入了监听注解
@EnableRabbit
首先要用到RabbitMQ的注解,因此要再启动类加一个@EnableRabbit表示开启基于注解的RabbitMQ模式
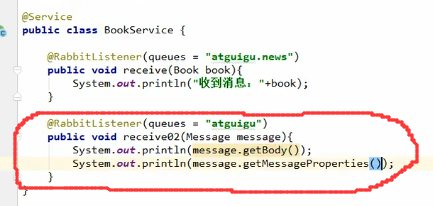
@RabbitListener

里面指定队列,注意可以是数组的形式,上图表示当atguigu.news队列中有book的消息就进行处理。
当然,我们还可以获取消息的头信息和主体信息:
AmqpAdmin
上面我们的RabbitMQ中的队列,交换器什么的都是手动配置的,那如何自动配置呢?要用到AmqpAdmin
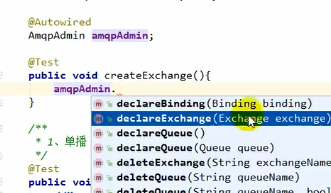
declare开头的都是用于创建交换器、队列等组件的,相应的有delete
在创建交换器的时候我们发现要传入一个Exchange对象:
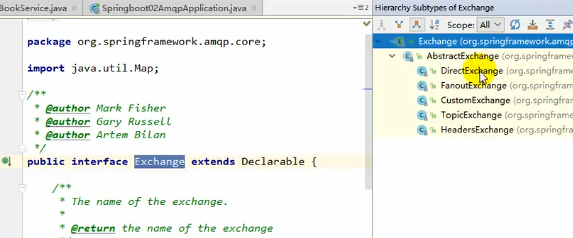
我们发现他是一个接口,有很多实现,而这些实现正是上面讲的几种模式,还多了一个自定义

创建队列也一样

注意,交换器和队列的初始化方式不只传name这一种,具体的点进去看构造器
创建Binding也一样,具体的看Binding构造器

有创建就有删除,删除的基本一样的操作
Springboot与检索


由于es由Java编写,启动的时候会默认占用2G的内存,因此我们在run docker的时候可以添加-e ES_JAVA_OPTS=“-Xms 265m -Xmx256m”参数来限制启动时Java占用的内存(该参数表示初始化占用内存256兆,最大占用内存256兆):


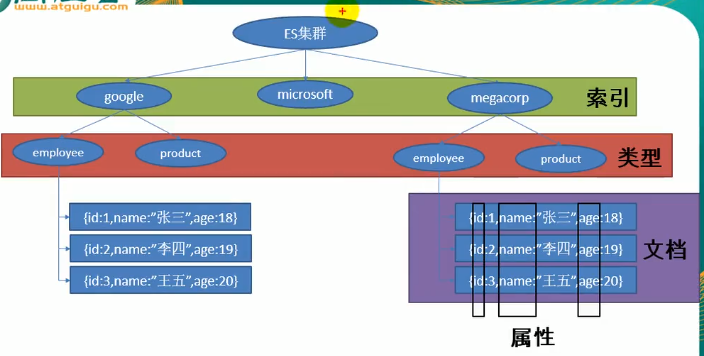
测试
在存入一些数据之后哦我们去查找数据
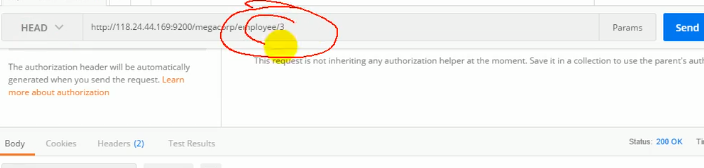
可以使用HEAD请求,表示判断es中是否有该数据,有跟没有都不会返回内容只会返回状态码,找得到就是200ok,找不到就是404not found
搜索全部数据:

搜索last_name为Smith的数据:

还可以这样查询:


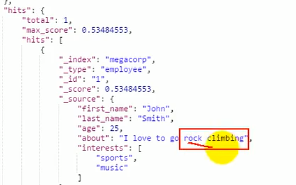
查数据所有属性中可能有rock climbing这两个字段的数据:
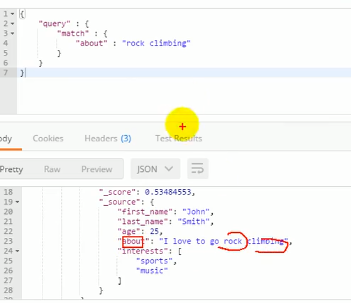
可以看到上图的_score有0.53+
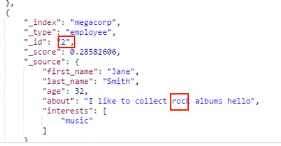
而2号员工只匹配到了一个rock,所以他的_score只有0.28+
上面模式是match,会将短语拆分成两个单词,使用match_phrase之后就可以不拆分匹配整个短语:
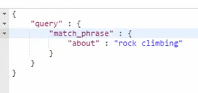
结果:
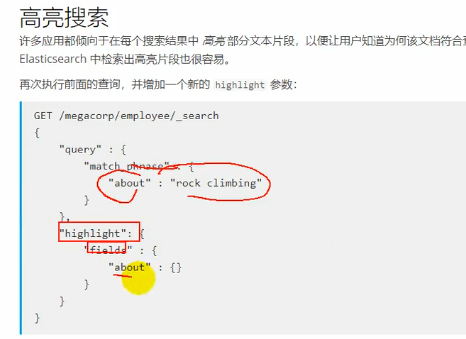
高亮搜索:
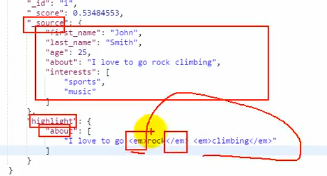
高亮部分用em标签包裹起来了
spring boot整合elasticsearch

点进去看一下:
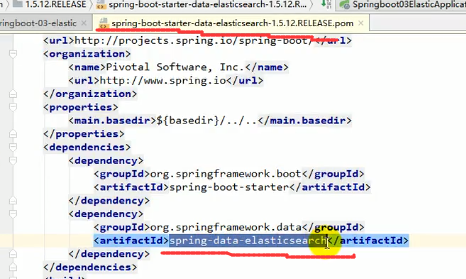
SpringBoot默认支持两种技术来和ES交互

其中Jest是通过http请求来和es交互,就相当于我们上面测试的时候用postman发送请求那样来交互,但是看Jest的自动配置类我们发现他需要配置一个JestClient之后Jest的自动配置才会生效
Jest
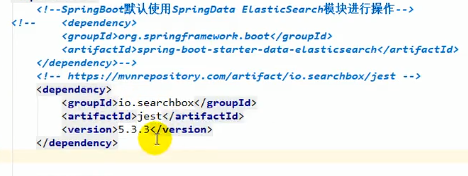
由于es版本是569的:
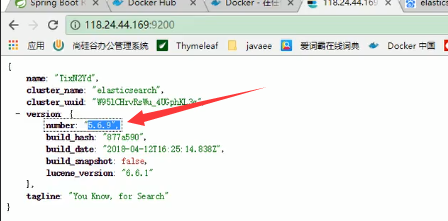
所以jest也要是5版本的:
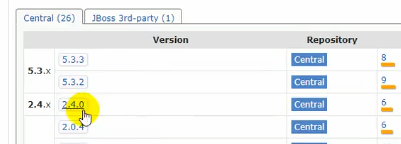
导入jest模块并注释掉spring data的es:
之后还是老套路,去找jest的自动配置类里面的properties,里面有各种配置信息

我们要配url:

之后注入jestClient就能用了:

@JestId
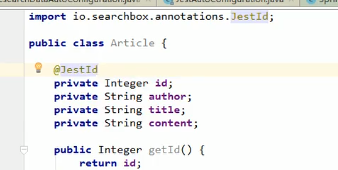
告诉es这个是主键
创建索引

搜索
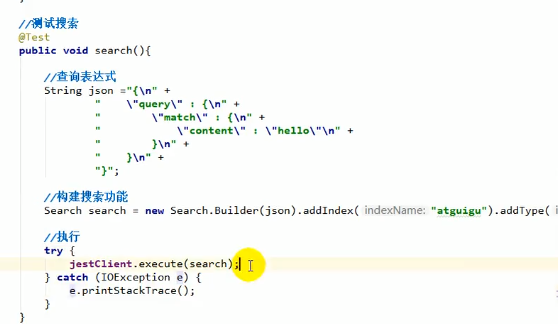
上图遮住的部分:

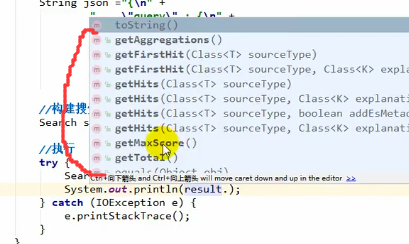
能从查出来的返回值中获取命中、最大分值、总记录数等很多东西,如上图

我们这里就拿一个返回结果的json字符串
更多操作去GitHub查看:
SpringData ElasticSearch


注意,这个nodes不是用9200来通信的,而是用9300
name你懂的,就是集群名称
解决es和springboot的es版本不匹配问题
启动之后报错了,原因是springdata的es版本跟es版本不符
解决方法:
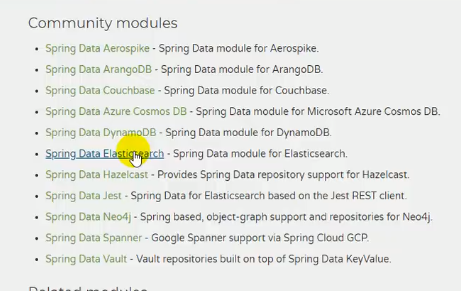
找springboot官网中的spring data:
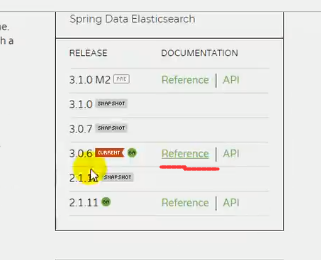

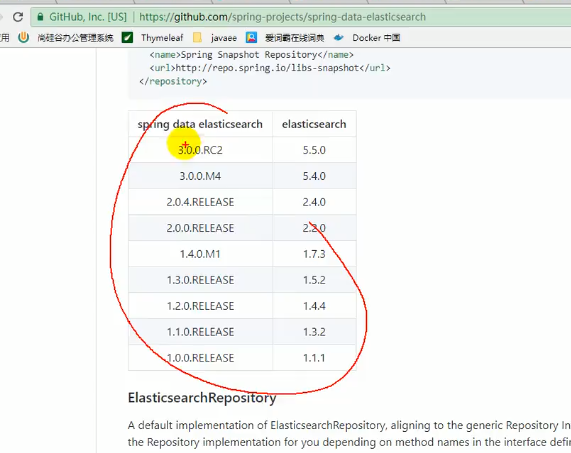
上图就是es对应springboot的es版本
上面说了,有两种方法来解决版本不匹配问题,一种是修改springboot版本,一种是修改es版本,由于修改springboot版本可能会牵扯到其他组件的版本适配,因此我们修改es版本
重新run一个es:

之后就不会报错了

而且显示添加到了节点9301
使用方法
参照GitHub上的文档
####### 第一种用ElasticsearchRepository
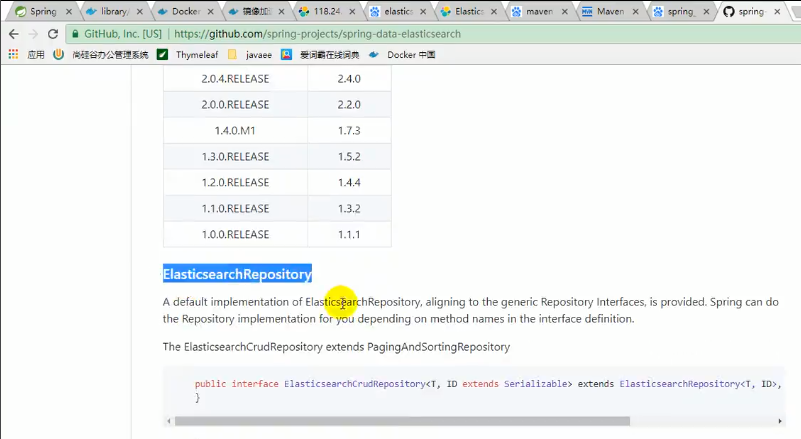
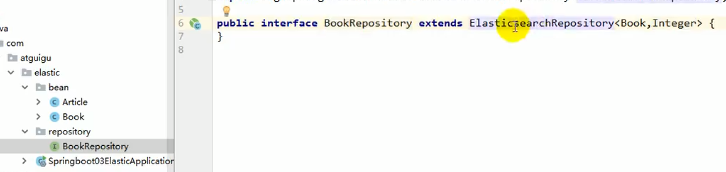
用法跟jpa完全一样,继承接口之后指定泛型即可,泛型中的第一个参数是实体类类型,第二个参数是实体类主键的类型,如上图
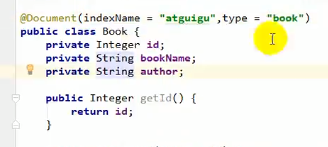
之后在实体类用@Document(这是es的注解)指定索引和类型:
然后测试:


扩展查询接口

可以在Repository中写自己想要的接口,如上图
注意这个接口不用实现,spring-es自动会实现接口的查找方法(这里有点迷,为什么能自动实现呢?他怎么确定是精准查询还是模糊查询呢?下面有解答)
下面来使用该接口:

扩展方法可以参照上上图的那个网址

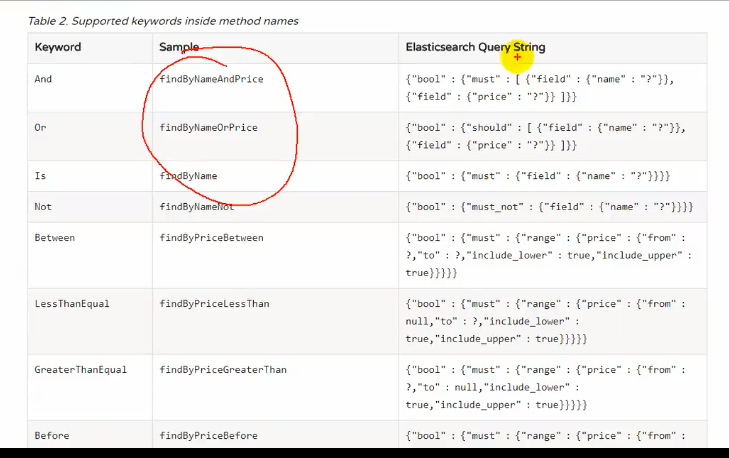
这里我们明白了为什么可以这么用,这其实是官方定义好的接口的命名规则
@Query标注扩展接口的查询方法
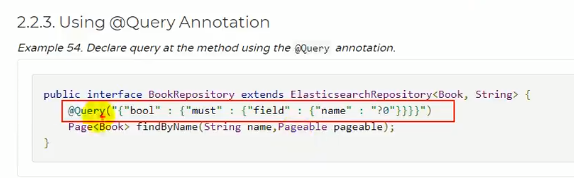
除了上面的那种方法,我们还可以给接口标注@Query注解来表明该接口的查询方法
####### 第二种用ElasticsearchTemplate
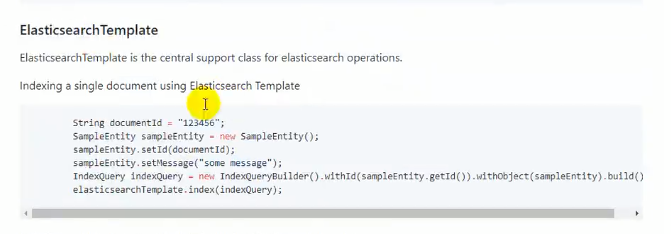
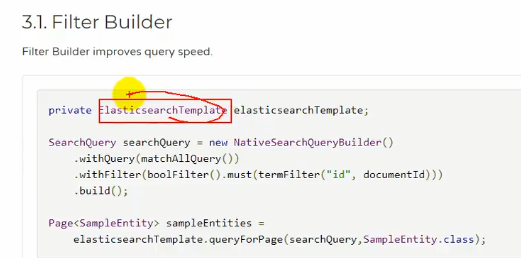
具体使用去看官方文档
Springboot与任务

异步任务
先来模拟一个需要很久时间的任务:
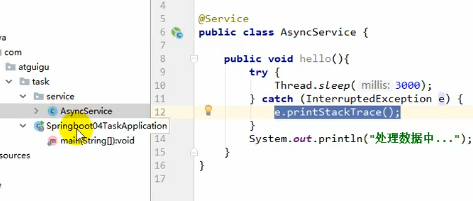
之后调用:

在同步的方法之下每次都要等很长时间用户才能拿到数据
当然我们可以用多线程的方式手动改写该任务,但是这样太麻烦
@Async
告诉Springboot这是一个异步方法,Spring就会自己调用线程池来异步执行该方法

@EnableAsync
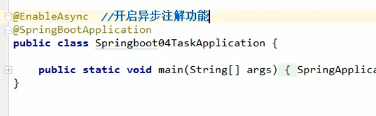
要使用上面的异步注解,我们就需要标注@EnableAsync
定时任务

@Scheduled
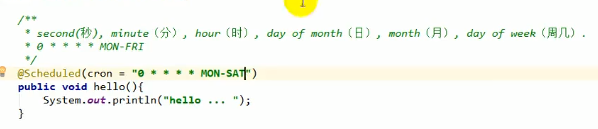
跟linux的crontab很像,只不过多了一个秒
上图的cron表示周一到周六每一分钟的0秒的时候都执行一次任务
@EnableScheduling
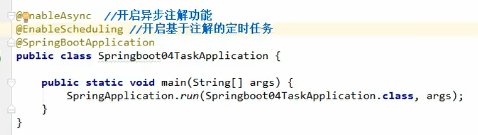
cron表达式

枚举
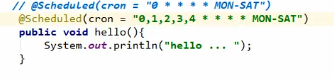
区间
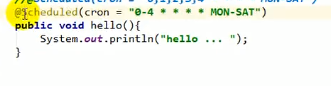
步长
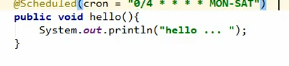
上图的意思就是每4秒执行一下任务
其他的表达式

解释一下 ? :
比方说我们写了一个 0 15 10 * * 1-6 这串表达式的意思本来想表达的是每个月的周一至周六10:15份执行一次任务,但是会有歧义,上面日的位置我们写了 * ,但是后面又写1-6表示周一至周六,这就有问题了,并不是每一天都是周一至周六的,可能有一天是周日,这个时候日这个位置就不确定了,因此我们的 ? 就要发挥作用了,他表示不确定,见上图
解释一下 L :
表示最后的意思,见上图
解释一下 W :
表示工作日
解释一下 ## :
比方说表达式 0 0 2-4 ? * 2#3 表示每个月的第三个周二的凌晨2点到4点,每个整点执行一次任务
解释一下 C :
C 表示与Java的calender联系后计算过的值
表达式连写
比方说 LW 就表示最后一个工作日
SchedulingConfigurer
基于注解 @Scheduled 能实现简单定时器,那么如何实现高级定制(比如实现动态定时任务)呢?
这个时候就要用到SchedulingConfigurer接口了
参考:https://blog.csdn.net/u013998466/article/details/90373811(SpringBoot 实现定时任务的两种方式:基于注解(@Scheduled)的简单定时器、基于接口SchedulingConfigurer的动态定时任务)
邮件任务

JavaMailSenderImpl就是用来发送邮件的:
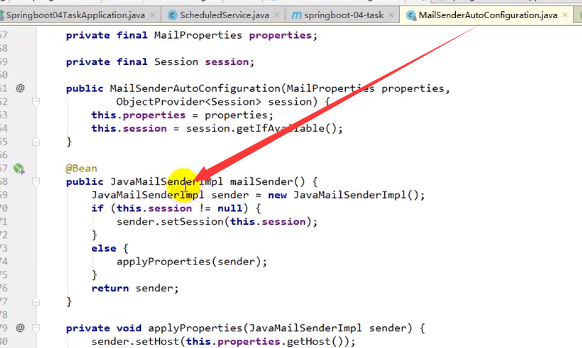
还是在Properties里面配置属性:
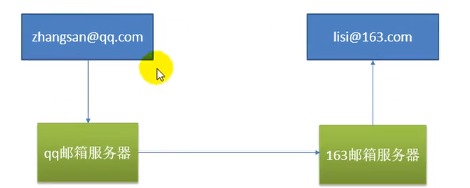
我们发邮件不是直接发给对方的,而是去找自己的所处邮箱服务器,邮箱服务器之间互相发送,之后再由邮箱服务器发给对方:
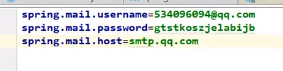
所以我们除了要配置发件人的用户密码之外,还需要配置所在的邮箱服务器
其次,为了安全,配置的密码也是授权码(跟之前Django写过的邮件服务一样)

最后配置完成:
注意,qq邮箱需要额外配置ssl:
复杂邮件
简单邮件我们用的SimpleMailMessage
复杂邮件我们需要用到MimeMessage,但是MimeMessage没有setSubject、setText这些方法,
因此还需要借助MimeMessageHelper,传入的第一个参数是mimeMessage,第二个参数是multipart,当我们需要传输文件的时候就需要设置multipart为true
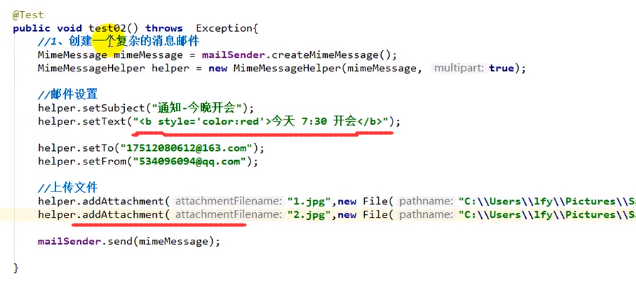
复杂邮件的setText里可以写html代码,而且可以发送附件,其中这个文件可以是一个文件也可以是一个文件流
发送之后我们发现html文本没有被解析,那是因为setText里面有个参数要设置为true,表示解析html代码:

Springboot与安全
身份认证、权限控制、漏洞攻击等

市面上有两个比较好用框架,一个叫shiro,一个就是Spring的Security


认证是指用户输入用户名密码登录
而授权的意思是当用户调用接口的时候是否有权限访问该接口
两者是不一样的
Spring Security

如何配置要去看官网

官方就有例子
配置权限,不用的接口对于不同的角色有着不同的访问权限:
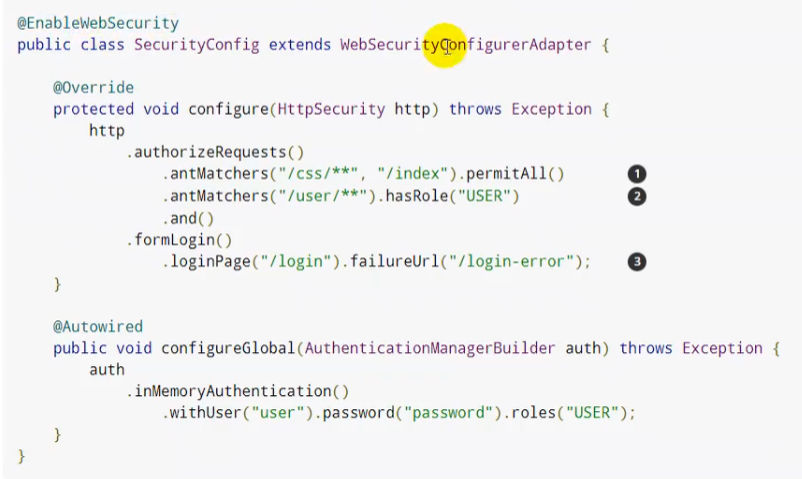
由于@EnableWebSecurity里面自带了@Configuration,因此我们就不必再在他的配置类上面加@Configuration了
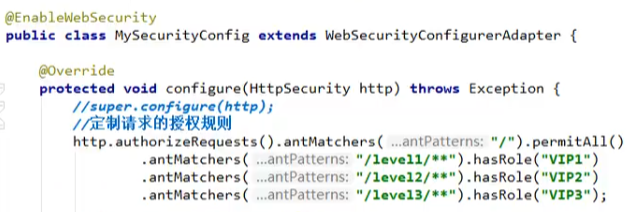
这里/level1/** 是指url,其中的两个*是level1里面不管嵌套了几层都会被影响到,如果是一个*那就只是level1下的层级会被影响到
之后再开启自动配置的登录功能:

注意,这个登录页面是spring默认的,那么怎么让他跳转到我们自己指定的页面呢?

后面加个loginPage()就行了
另外默认post形式的/login代表处理登录,而登录是要带用户名和密码的,所以我们用usernameParameter()和passwordParameter()来将前端的form表单里面的属性name为user和pwd的input中的内容传过来:

这里要说一下:

一旦定制loginPage(),那么loginPage()的post请求就是登录,我们也可以用上图的loginProcessingUrl()来表明用那个网页来处理登录请求,当然如果不指定loginProcessingUrl()的话那默认就是用loginPage()中的那个网页来处理登录请求。
全局配置用户名和密码:
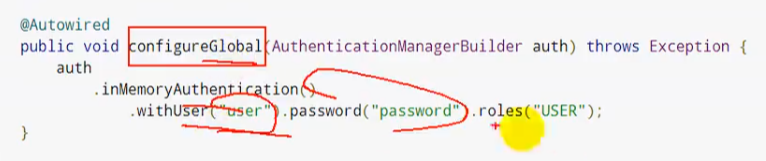
注意这些配置是在内存里面的
定义认证规则:
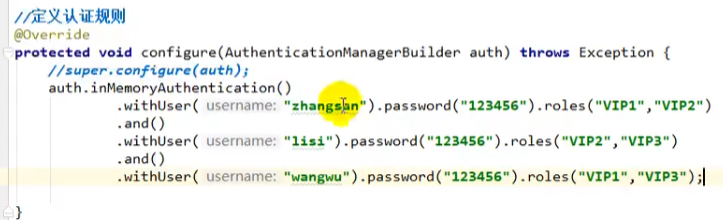
注意,后面的roles里面可以写多个角色,例如:roles(“vip1”,“vip2”)
开启自动配置的注销功能:

注意,如果logout()后面不写logoutSuccessUrl()默认是回到登录页面,写logoutSuccessUrl()就是为了注销之后来到某个指定的页面
开启记住我功能:

这样退出浏览器之后再次访问就不用登录了
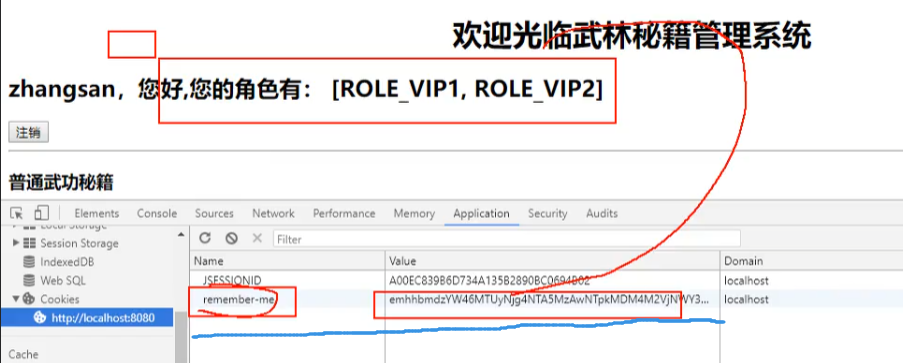
原理就是加了一个有过期时间的cookie,再次访问的时候如果找到了这个cookie就不必登录了,点击注销之后cookie就不见了:

那么为什么点击注销之后cookie就没有了呢?
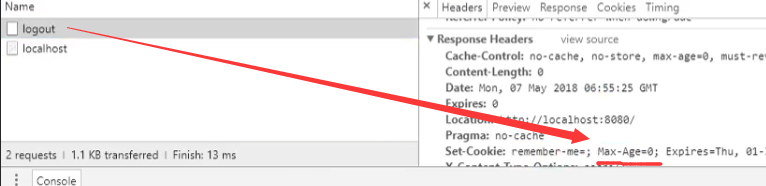
那是因为点击注销之后发送了一个删除cookie的请求(Max-Age=0)
我们也可以用rememberMeParameter()指定哪个前端元素中的内容可以来决定是否要启用rememberMe()这个功能,比方说我们前端来个checkbox,name设置为“remember”,那么rememberMeParameter()中的参数就写“remember”,这样就能关联上了,只要前端checkbox打勾了,就会启用rememberMe(),如下:


Springboot与分布式


比方说我们有一堆用户服务器,一堆订单服务器,当用户服务器想要去调用订单服务器的时候,我们就需要一个RPC框架(分布式服务框架),这个框架spring cloud可以做,dubbo也可以做
但是呢,还有个问题牵扯到注册中心,比方我们用户模块想要使用订单模块的东西,但是订单模块有好几台机器,那么究竟用哪一台机器的呢?这个时候就可以有一个注册中心,里面保存了订单模块都在哪些服务器里面,用户想要用订单模块的时候先来问一下注册中心,我要的订单模块哪些服务器里面有,订单模块告诉他1号、2号服务器里面有,那用户模块就直接去1号或2号服务器里面调用这些订单模块。其实注册中心就类似于一个中介。
Zookeeper和Dubbo

Zookeeper就用来做注册中心,而Dubbo用来做分布式框架,他来负责A模块和B模块的远程调用:

但是B在哪呢?我们用注册中心保存B的地址,A访问注册中心,找到B的地址以后进行远程调用
dubbo架构
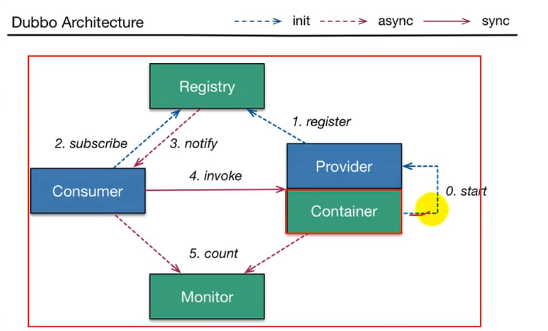
Container是dubbo的服务容器,他在启动的时候负责启动运行Provider(服务提供者),Provider会将自己能提供的服务信息注册到注册中心Registry里面,Consumer启动的时候会从Registry里面订阅需要的这些服务,之后registry将这些服务的地址列表全部返回给Consumer,而如果服务有变更,Registry也可以使用基于长连接的方式将更新后的服务推送给Consumer,相当于Consumer手中持有一份实时更新的Provider名单,如果Consumer想要调用某个Provider,可以从提供者Provider的地址列表中基于负载均衡机制找到某个Provider的位置来调用它的服务,如果调用失败可以从地址列表中找到另外一个Provider来继续调用他的服务直到调用成功
dubbo还有监控机制Monitor,我们可以将调用信息、调用时间每隔一定时间给监控中心Monitor发送一次来做到一系列的监控
安装zookeeper
用docker安装即可
使用镜像加速:

开启镜像
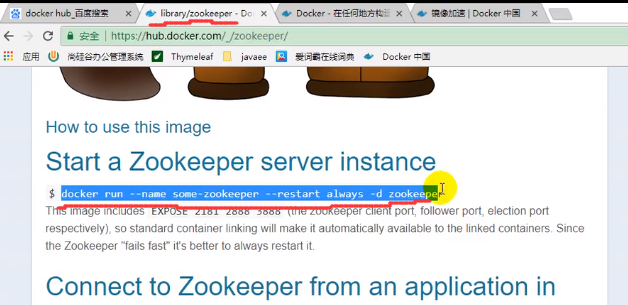
上图的EXPOSE 2181是zookeeper服务交互的端口,后面两个2888是集群,3888是选举

测试
首先要有一个生产者一个消费者
对于生产者:

对于消费者:

首先创建一个空工程
然后在里面创建一个spring初始化工程
然后在里面制作service
之后再创建一个spring初始化工程,用于模拟Consumer
现在我们Consumer内部想要用之前创建的那个工程的service服务,这个时候就要用到dubbo了
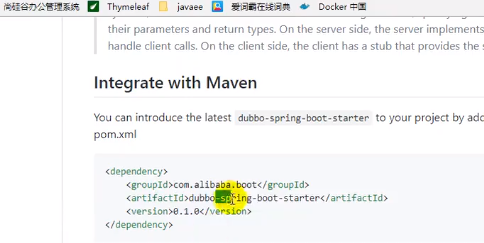
引入dubbo
找到dubbo官网的maven配置
zkclient
之后我们要用到zookeeper的客户端工具叫做zkclient
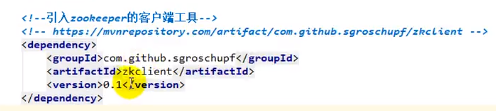
配置dubbo
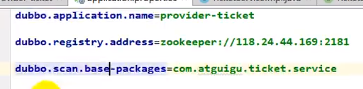
首先指定名称,之后指定注册中心的地址,再指定扫描服务所在包
之后在Service类上加上@Service注解,注意这个Service是dubbo的service
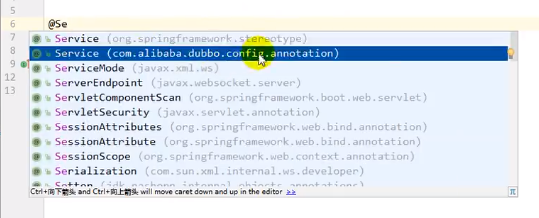
之后再用@Component将这个服务加到容器里面

接下来我们配置消费者:


全类名匹配
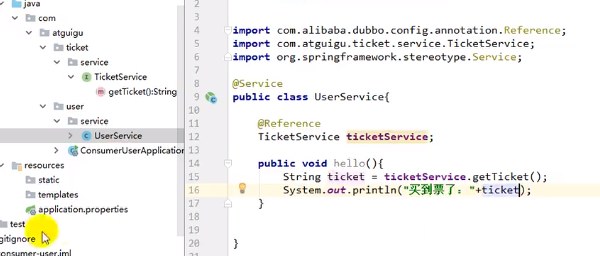
之后在消费者中创建与生产者注册的类名一模一样的类,而且实现就不需要了
注意,一定要全类名相同,因为之前发布的时候就是按照全类名进行注册的,他去注册中心找的时候也是按照全类名匹配
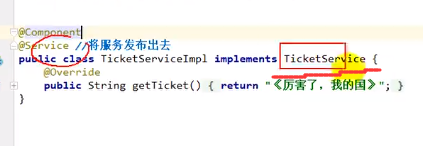
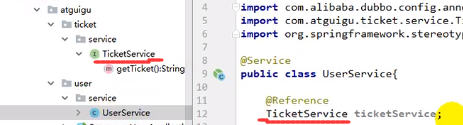
@Reference
使用@Reference远程链接服务,如上图
这个时候我们的TicketService就可以链到生产者所提供的那个TicketService服务了
这个时候就能用了:
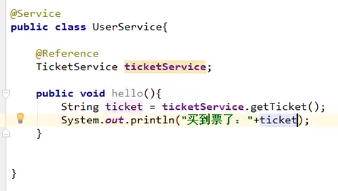
注意这里的@Service还是springboot的service,因为它是消费者不是生产者
注意消费者服务使用的时候生产者服务不能关
Spring Cloud

Eureka:zookeeper对应的就是Eureka
Ribbon:比方说A服务要调用B服务,而B服务有多台机器,这个时候可以有Ribbon实现负载均衡来确定到底是调用B服务的哪台机器
Hystrix:当A调用B,B又要调用C,C又要调用D,D又要调用E的时候,如果C出现了故障,导致C后面的路线走不完,这个时候将会有漫长的等待,这个时候我们可以用断路器Hystrix在B服务调用了几次C服务失败之后快速的响应失败,不让用户等待太久
Zuul:服务网关,A服务调用B服务之前先通过服务网关过滤请求
Spring Cloud Config:用于A服务、B服务的配置
测试
还是开启一个空工程
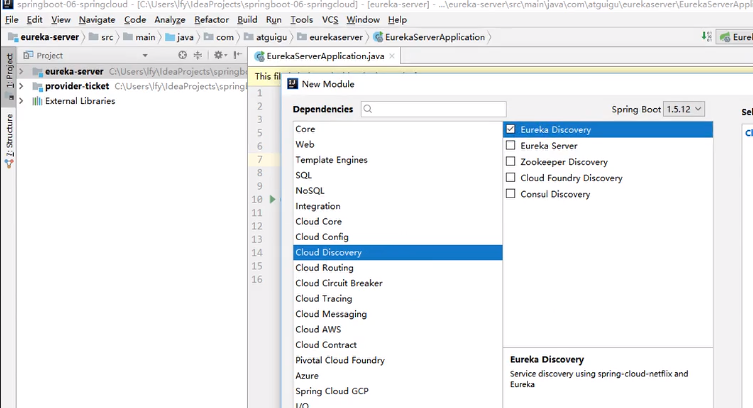
首先搭建Eureka Server:
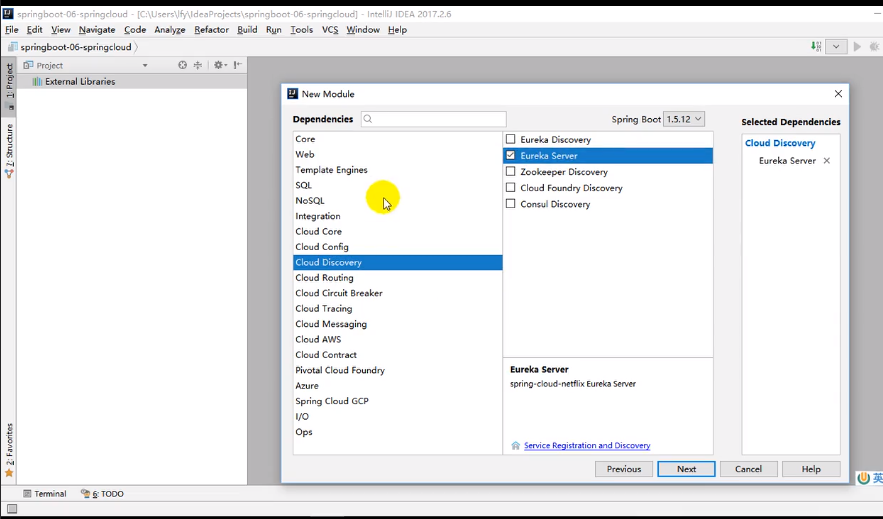
再开启服务提供者,注意不管是服务提供者还是消费者都是在注册中心里面的,因此是Eureka Discovery而不是Eureka Server(可以理解为服务提供者要在注册中心注册自己,而服务消费者要去注册中心找服务提供者)
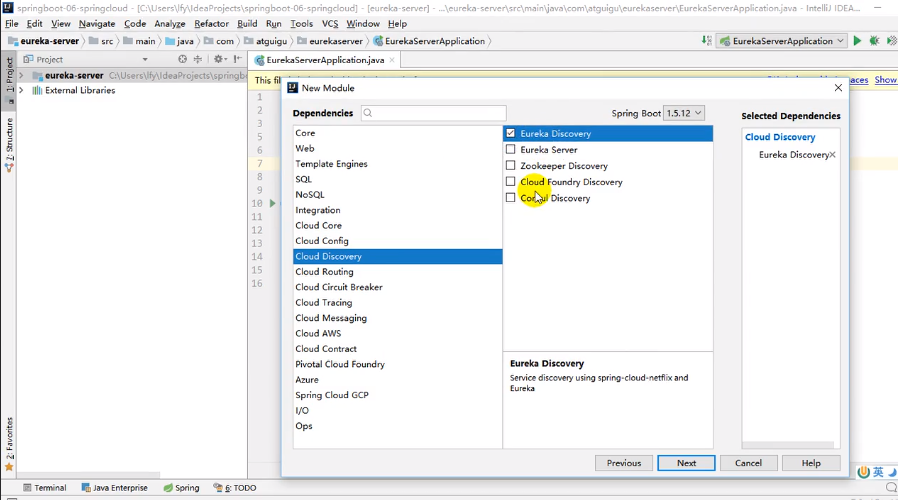
再创建一个服务消费者,上面说了我们的消费者也要去注册中心找服务提供者,因此也需要Eureka Discovery
配置
在上面创建的server工程中先进行如下配置:
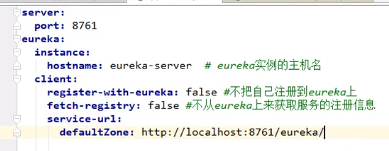
注意这个register-with-eureka再不做高可用的情况下不需要,因为它会将自己注册到rureka上;fetch-registry是从eureka上获取服务的注册信息,我们这里也不要;service-url可以点进去看一看如何定制,这里我们按照规则写了一个自己的defaultZone
@EnableEurekaServer

在provider提供者中编写服务:
Spring cloud在整合微服务的时候是使用轻量级http进行通信的,所以我们要将这个接口暴露出来:
在 provider提供者中进行配置:
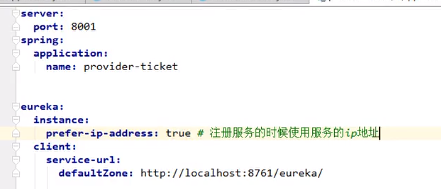
注意,在用provider和consumer的时候server不要关。
注意,这里的spring: application: name: xxx最终会到eureka的application这边:

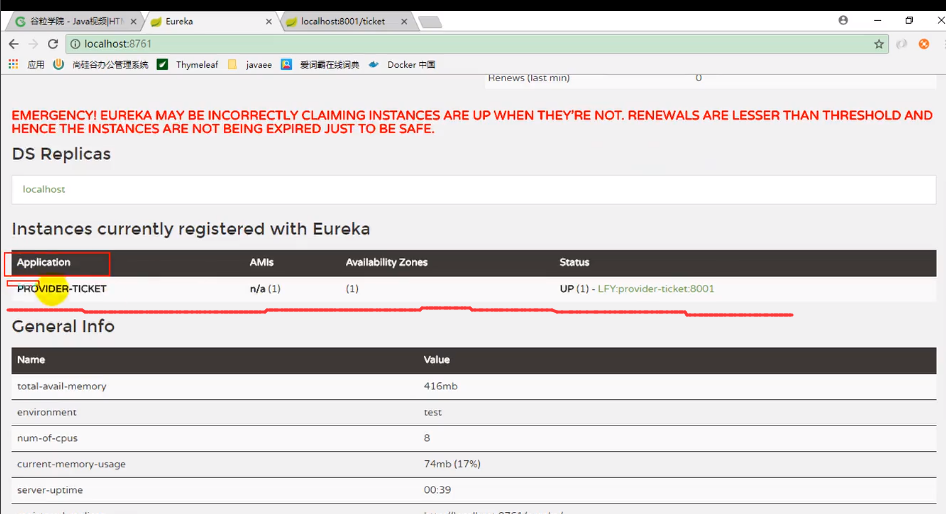
之后我们调用上上图的接口,发现是可以正常显示数据的,再来看Eureka:
之后我们将provider进行打包:
上图这个provider端口是8001的,现在我们换一个端口8002再打包:
现在我们就有两个jar包了:

现在演示如何将同一个应用在注册中心注册多个
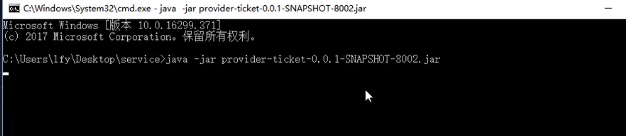
我们用cmd将这两个jar运行起来
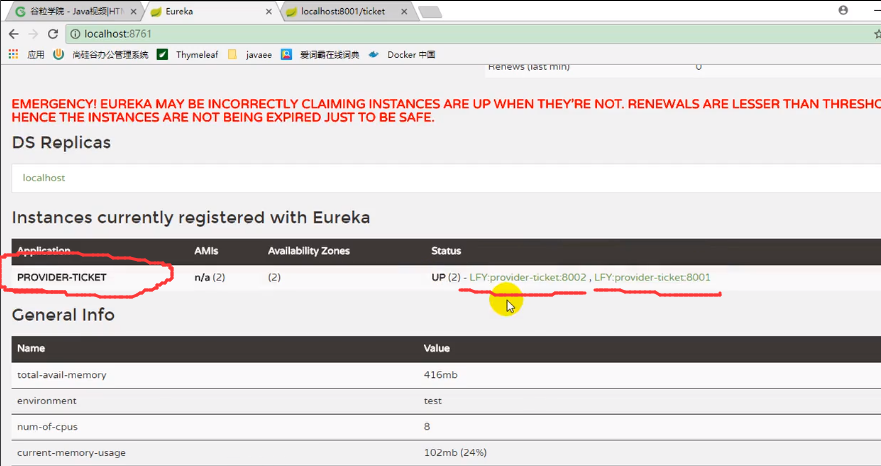
我们会发现同一个应用的两个实例就被注册到注册中心了
在Consumer中配置:
将自己注册进eureka中,并从中发现服务提供者:
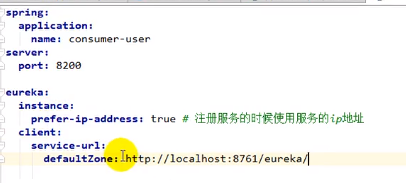
@EnableDiscoveryClient
开启发现服务功能

RestTemplate
那么如何调用提供者的服务呢?要结合RestTemplate,他是来帮我们发http请求的

@LoadBalanced
使用负载均衡机制
在Consumer中编写服务调用provider:
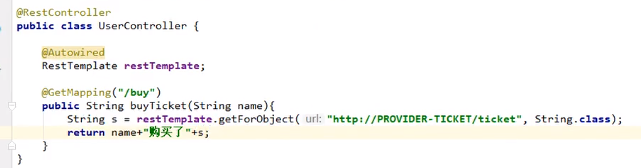
首先将上面的RestTemplate注入进来
我们用restTemplate的getForObject()来发送一个http请求来获取数据
注意getForObject()这个方法的第一个参数,是一个url,他之所以写成http://PROVIDER-TICKET/ticket,是因为我们给provider的发票服务配的就是/ticket,如果要调用该方法就需要发送http请求,且url就是http://192.168.1.183/ticket,中间的这个PROVIDER-TICET事实上是application-name,从eureka的application那里也可以获得(eureka的application里面的name实际上就是我们写配置文件时写上去的spring: application: xxx,所以从根源上来讲这个url中间的这一串字符就是配置的时候我们自己写上去的那个name),这里用这个name替换掉了192.168.1.183,后面的/ticket不变。
我们来看看eureka的application:
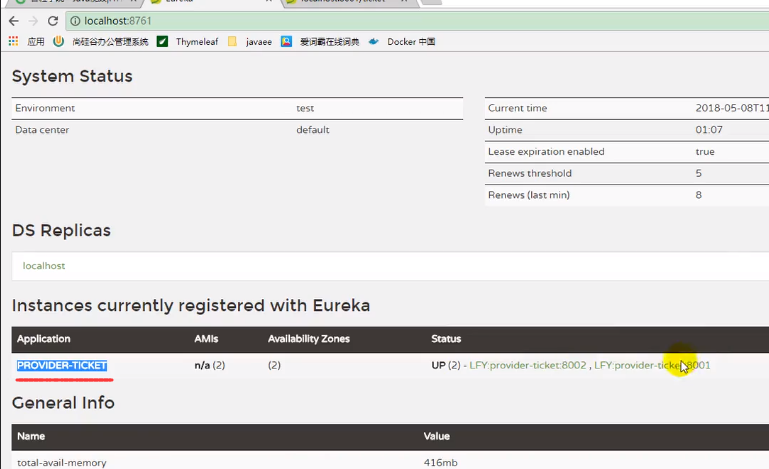
调用consumer的这个方法之后,我们会发现eureka里面consumer也注册进来了:
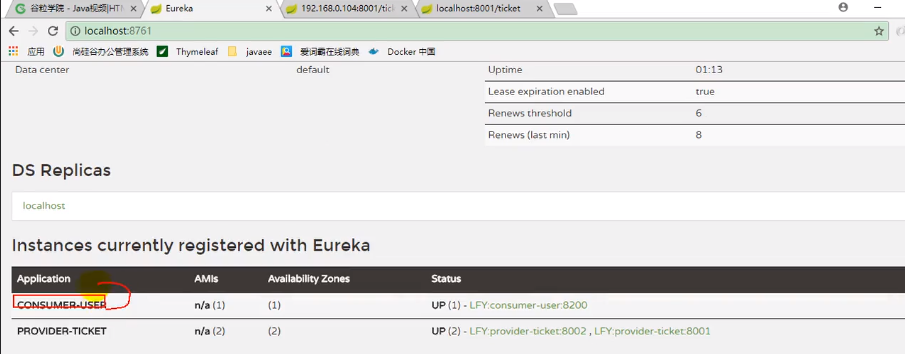
之后直接调用consumer的接口就能获取数据了,而且是有负载均衡机制的:
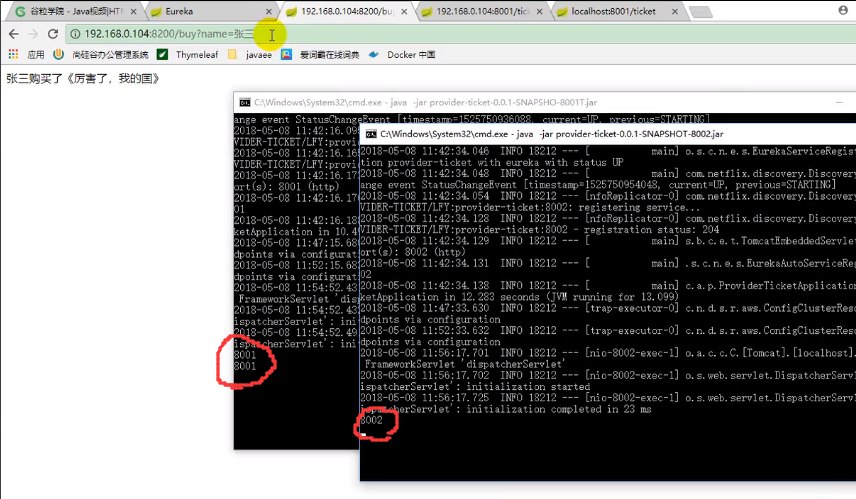
我们之前用同一个应用配置了不同端口并根据端口在注册中心注册了两个实例,上图就是在负载均衡的影响下两个实例的调用情况
这里的负载均衡其实是一个轮询的机制,即下一次访问另外一个。
springboot与开发热部署



之所以无法热部署,那是因为Java文件执行前被编码为.class文件,我们在target里面可以找到:
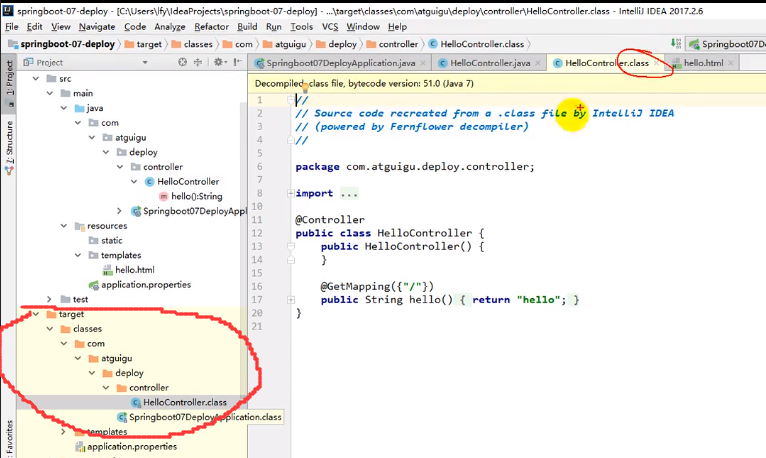
这个时候我们按下ctrl F9,发现编译后的.class文件确实变化了,注意此时服务器还没关,但是我们发现在访问的时候还是没有任何改变,这是因为实时编译的.class文件并不能应用到工程上
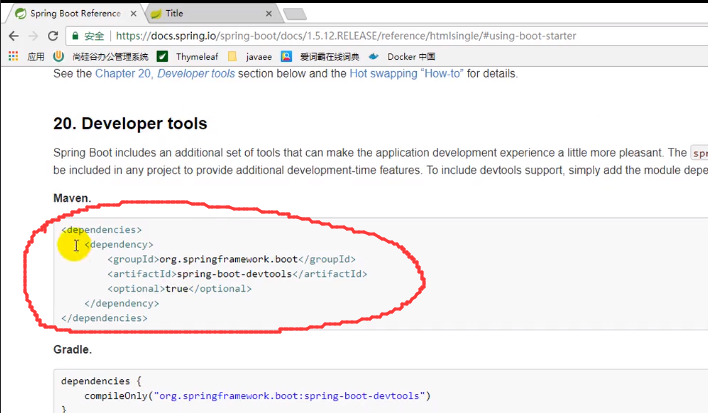
现在我们来引入Dev tools
之后就可以热部署了,在每次做出改变后按下ctrl F9就可以不用重启服务器也能看到我们做出的改变了
eclipse就更方便了,直接ctrl s保存就行了
spring boot与监控管理

测试
创建工程:
勾选actuator
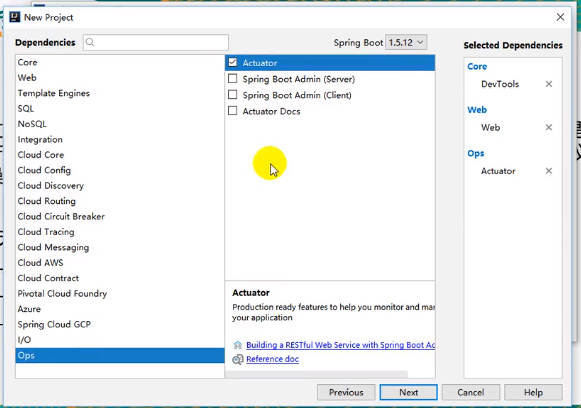
可以再勾上热部署和web方便测试
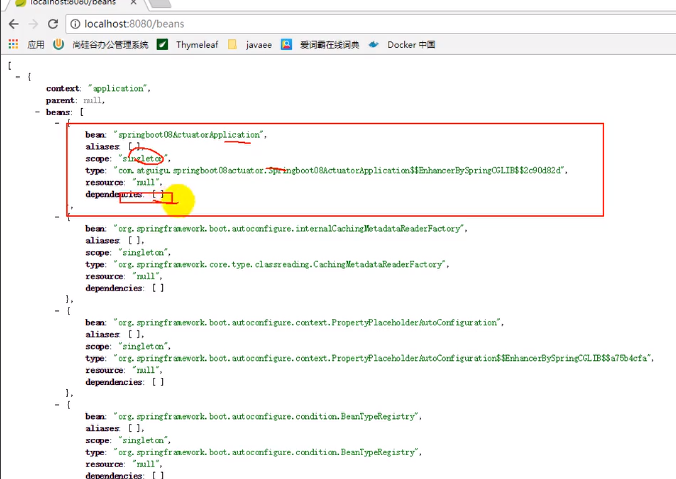
启动之后控制台会打印非常多的配置信息,我们可以看到后面的/xxx ,说明这些都可以通过url地址进行访问
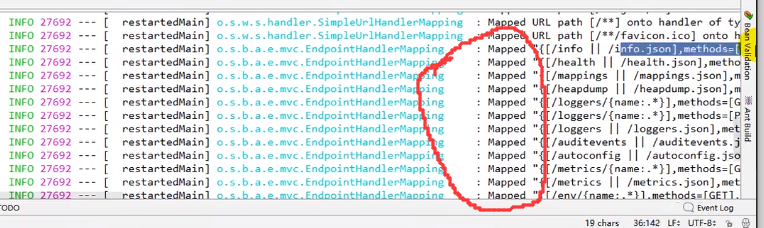
这是引入了actuator之后才会有的
之后我们尝试访问上述匹配信息中的/xxx,会发现无法访问:
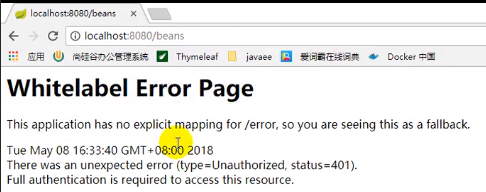
将保护关闭:

就能访问了:
监控和管理端点
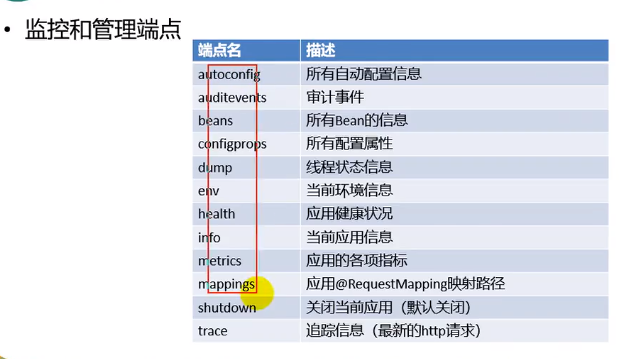
这些都是可以访问信息的端点
info
当我们在配置文件写了info开头的配置之后:
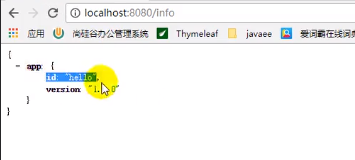
访问info端点就能得到信息
配置git.properties将代码托管到git
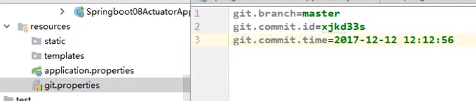
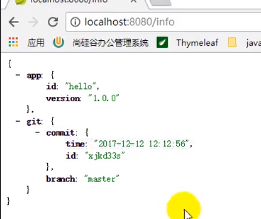
由于GitProperty继承InfoProperties,所以git开头的配置也能被info端点检测到:
heapdump
将内存快照下载过来,根据内存快照定位应用的一些问题

configprops
所有配置的属性

我们就可以从这里看到属性的前缀名以及他能配置的一些信息,从而来进行配置:

这样的话我们的/metrics就不能访问了
shutdown
用于配置远程是否能关闭应用

然后发一个post请求:
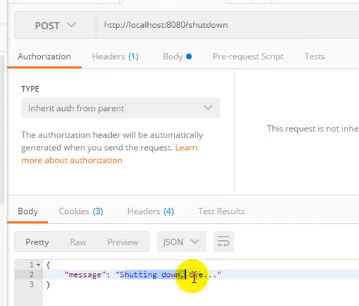
应用就关闭了:
定制端点

定义端点id或访问路径
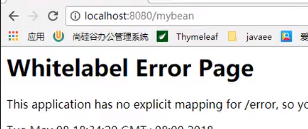
比方说要自定义endpoints.beans.id:


这个时候以前的beans就不能访问了,这个时候应该用mybean来访问
我们也可以修改beans的访问路径:

这个时候mybean也不能访问了,要用/bean来访问
其他的都一样,比如dump:

开启或关闭端点
上面是定制端点访问路径的,我们还可以开启或者关闭某个端点:

现在这个beans端点就不能访问了
开启或关闭所有端点

我们也可以关闭所有端点之后开启某个端点:

不建议用这个
定制端点访问根路径

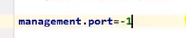
定制端点访问端口
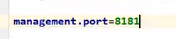
如果我们把端口改为-1那他就什么都访问不到了
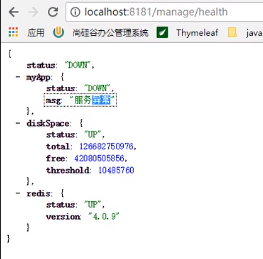
自定义health indicator
健康状态默认只给了一个diskSpace的健康状态

当然我们还可以定制更多的健康状态,Springboot里面就有很多默认配置好的健康状态
都在actuator包下:
这里有非常多的健康状态组件,比方说redis的,何时生效呢?在有了redis相应的starter之后自然就会生效
我们引入redis:

配置一个错误的redis信息:

此时我们本机没有redis,这样配肯定错
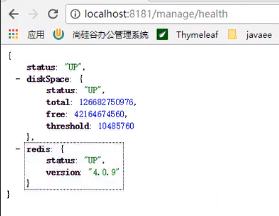
健康指标显示:

当配置正确的时候:

我们想实现类似这样的指示器,而且想要自定义实现

首先要继承HealthIndicator:
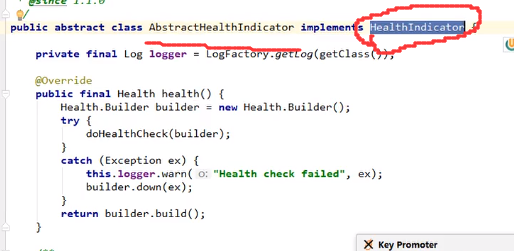
其次,其名称的时候一定要是xxxHealthIndicator,这个是有规定的
最后加到容器中即可
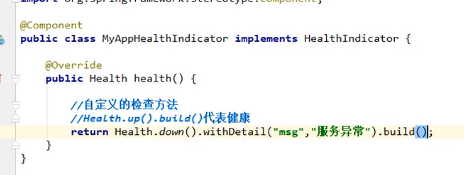
健康的时候返回Health.up().build()
失败的时候如上图