webpack学习总结,包含了webpack开发环境与生产环境基本配置、优化配置以及其他更多的配置详情
Code in GitHub: webpack
npm初始化package.json
全局安装webpack

npm安装开发依赖(-D)

node找包原则
从当前包开始向上级目录找,找到为止
技巧:由于这个特性,我们可以把package.json放到最外面,免得每次创建demo都要初始化一次package.json,关键是他要是找不到这个package.json就用不了里面的包,所以这里我们干脆直接把package.json写最外面
运行指令进行打包
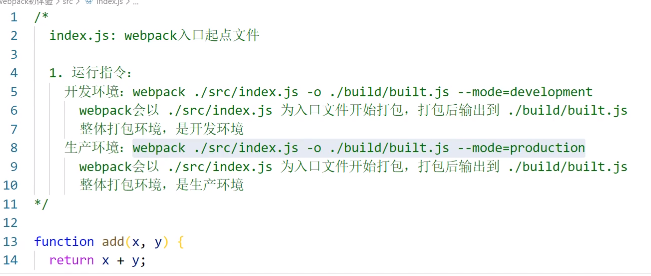
webpack ./src/index.js(入口文件) -o ./build/built.js(输出文件) –mode=production/development(环境)
开发环境和生产环境的区别就是生产环境代码经过了压缩
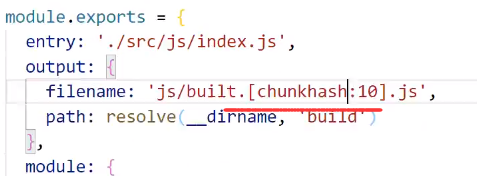
每次打包之后都会生成哈希值
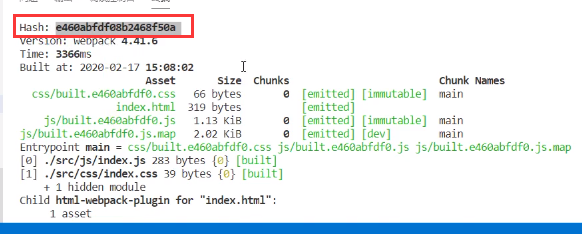
这个哈希值非常有用,在配置文件中可以通过使用 [hash] 或者 [hash:10]来使用这个hash值([hash:10]表示取hash值前十个字符)
引入打包后资源

webpack能处理的资源
经过尝试我们发现webpack能处理js和json,但是不能处理css和img等其他资源
生产环境和开发环境将ES6模块化编译成浏览器能识别的模块化

webpack.config.js
作用:

上面说了,css、img等无法被webpack处理,要借助loader,因此需要在配置文件配置loader,不仅是loader,很多其他的东西都得在这个配置文件里面配置
/*
webpack.config.js webpack的配置文件
作用: 指示 webpack 干哪些活(当你运行 webpack 指令时,会加载里面的配置)
所有构建工具都是基于nodejs平台运行的~模块化默认采用commonjs。
*/
// resolve用来拼接绝对路径的方法
const { resolve } = require('path');
module.exports = {
// webpack配置
// 入口起点
entry: './src/index.js',
// 输出
output: {
// 输出文件名
filename: 'built.js',
// 输出路径
// __dirname nodejs的变量,代表当前文件的目录绝对路径
path: resolve(__dirname, 'build')
},
// loader的配置
module: {
rules: [
// 详细loader配置
// 不同文件必须配置不同loader处理
{
// 匹配哪些文件
test: /\.css$/,
// 使用哪些loader进行处理
use: [
// use数组中loader执行顺序:从右到左,从下到上 依次执行
// 创建style标签,将js中的样式资源插入进行,添加到head中生效
'style-loader',
// 将css文件变成commonjs模块加载js中,里面内容是样式字符串
'css-loader'
]
},
{
test: /\.less$/,
use: [
'style-loader',
'css-loader',
// 将less文件编译成css文件
// 需要下载 less-loader和less
'less-loader'
]
}
]
},
// plugins的配置
plugins: [
// 详细plugins的配置
],
// 模式
mode: 'development', // 开发模式
// mode: 'production'
}
上面展示了一个配置demo,还有很多其他的配置demo可以去代码里面查看
安装css-loader和style-loader
使用npm安装这两个包,之后再执行webpack打包:
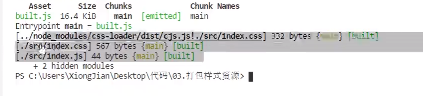
这个时候我们发现他多了一个css文件
实验:
把打包好的built.js引入,打开网页:
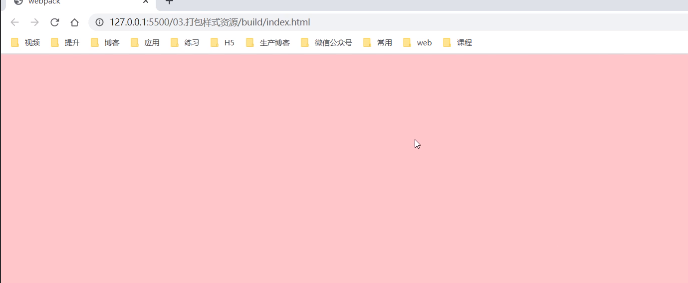
样式生效了
同理less文件的打包:

注意,use数组里面的东西执行顺序从下到上的,比方说上述执行顺序就是:1、less-loader;2、css-loader;3、style-loader
图片打包
具体配置见代码
优点:
打包的时候如果同一张图片我们引用了多次,比方说在less里用了一次,在html又用了一次,webpack都只会打包一次不会重复打包
webpack-dev-server
配置见代码
注意:
webpack-dev-server打包是在内存中打包,不像webpack直接在build文件夹生成打包后代码文件,一旦终止webpack-dev-server服务器,内存中的文件将被删除,最后在build文件夹下不会有任何打包后文件。
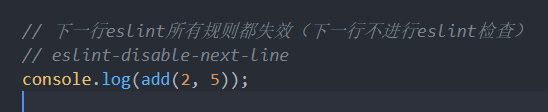
eslint-disable-next-line
取消eslint对于下面一行代码的审查:
生产环境中提取css为单独的文件(MiniCssExtractPlugin)
我们知道开发环境中打包后css是嵌在js文件中的,生产环境下我们需要使用MiniCssExtractPlugin插件把他单独拿出来
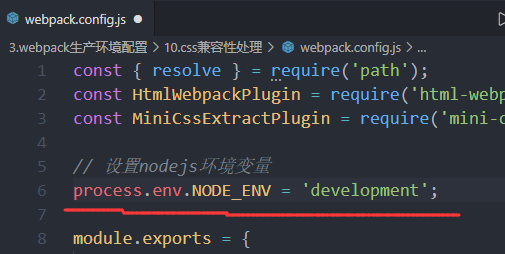
生产环境兼容性
注意,兼容性配置默认会去找生产环境的配置,跟配置文件中最后我们写的mode:development / production 没有任何关系
所以如果想要使用开发环境中的兼容性配置,需要在配置文件中写上nodejs的环境变量:
browserslist参数
具体配置见代码,这个参数可配置的东西远不止代码中的这些,更多配置去GitHub搜索
查看兼容性的网站(can i use)
比方说预加载这个共能兼容性比较差,具体的可以去can i use网站查看
语法检查eslint
GitHub上有个 “airbnb / javascript” 专门规范js的写法(教你怎么规范地写js)
我们想通过eslint使用这个 airbnb 帮我们检查js语法
那怎么操作呢?
去npm搜索eslint
之后看说明下载就行了
生产环境自动压缩js
当我们设置模式为生产环境之后,他会自动加载很多插件,其中包括这个插件:
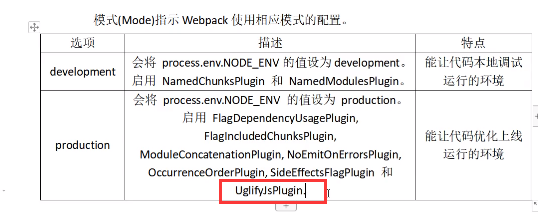
UglifyJsPlugin
他会帮我们自动压缩js代码
HMR
问题:使用热部署的时候每次改东西都刷新了页面,明明只改了css,js也跟着重新加载了一遍
,反过来js也一样,简言之我修改了一个模块,其他所有模块全部重新加载

对于样式文件,HMR正常起效;对于html文件,由于HMR解决的是一个模块变化后需要刷新,其余模块不跟着刷新,但是html自始至终都只有1个文件,也就是说html一旦变化了,也就他自己一个文件刷新,因此html并不需要HMR优化;对于js,HMR默认也是不起效的,需要添加额外代码来让他起效:
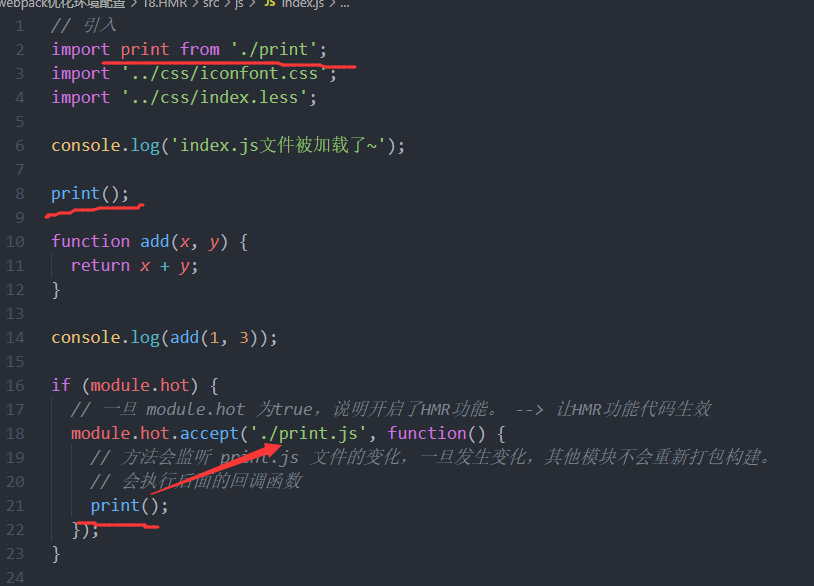
全局找module变量,如果存在且module.hot为true,说明开启了HMR,此时监听print.js(我们自己随便写的一个用来测试的函数),如果print.js这一块发生变化,就重新构建这一块,而其他模块不会跟着重新打包更新
注意:
-
HMR对入口文件(index.js)是无效的,因为index.js一旦变化,就要重新加载,势必也会重新加载那些被引入到index.js文件的js模块,这是无法阻止的
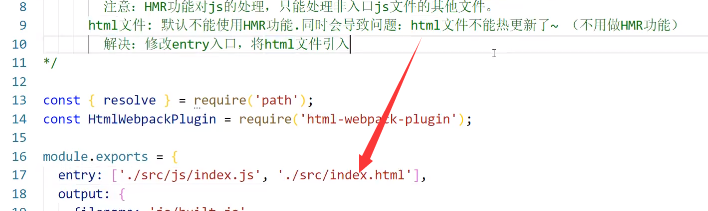
-
html代码不能使用HMR,同时会导致一个问题:html文件不能热更新了,解决方法就是在entry中将html文件也加进去:
source-map
devtool: ‘eval-source-map’
总结下来开发环境推荐用:
–> eval-source-map / eval-cheap-module-souce-map
生产环境用:
–> source-map / cheap-module-souce-map
oneOf
配置文件中有许多loader,但并不是每一个模块都会用到每一个loader,比方说js的,他是不会去用css和less的loader的,但是由于我们都把他们写到一起了,所以他还是会去用,用过后不合适才会跳过,使用oneOf之后,我们可以让他只匹配oneOf中的一个,比方说还是js,他只用两个loader:eslint和babel,而且eslint是需要先使用的,那我们就把eslint单独拎到oneOf外面,其他的一堆包括css、less、babel…的都放在oneOf里面,这样的话eslint一定会执行,而oneOf中的loader只会执行其中之一,显然这里就只会执行babel,大大提高了效率
缓存
主要是babel(因为js模块多,结构和样式的模块不会太多,就算多了,处理的东西也不会太多)和整体的资源这两点
问题:
如果有100个js模块,我改动1个js,其余的99个应该不要重新编译,这跟之前的HMR很像,但是HMR是需要依赖devServer的,在生产环境下没法用
这里我们就要开启babel的缓存(babel的缓存很简单,直接添加代码:cacheDirectory: true即可),他先把100个js模块编译后的代码进行缓存,之后如果发现文件没有变的话就直接使用缓存中的东西了
文件资源强制缓存的问题
当我们的代码发生改变的时候由于被强制缓存了,他在第二次是不会去访问服务器的,而是使用本地的缓存,这就导致更新的代码无法被使用
那怎么解决这个问题呢?
我们打算给代码文件名加个后缀哈希值,这样由于文件名变了,他肯定会重新加载的
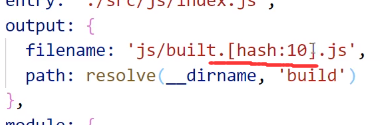
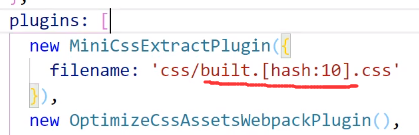
这样构建之后的文件文件名就带上哈希值后缀了:
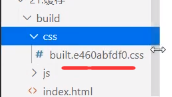
这个时候强制缓存也没办法了,因为每次打包都会生成不一样的hash值,所以文件名是肯定不一样的,意味着页面肯定会重新加载
问题来了:js和css用的同一个hash值,导致就算只有一个文件变动了,所有缓存也会失效,怎么解决这个问题呢?
使用contenthash
contenthash
根据文件内容生成hash值
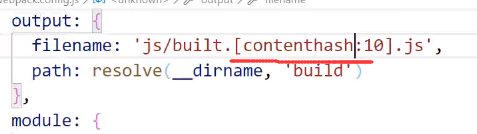
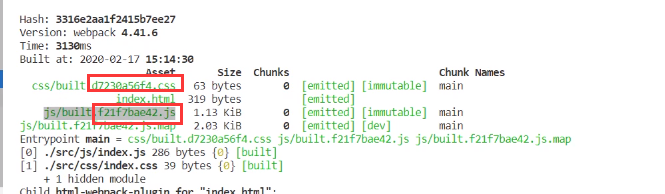
我们发现js和css的hash总算不一样了,这个时候我们修改js代码,第二次访问网页的时候css还是走的缓存,js就得重新刷新了
chunkhash
根据chunk生成的hash值,如果打包来源于同一个chunk,那么hash值就一样
什么叫做chunk呢?
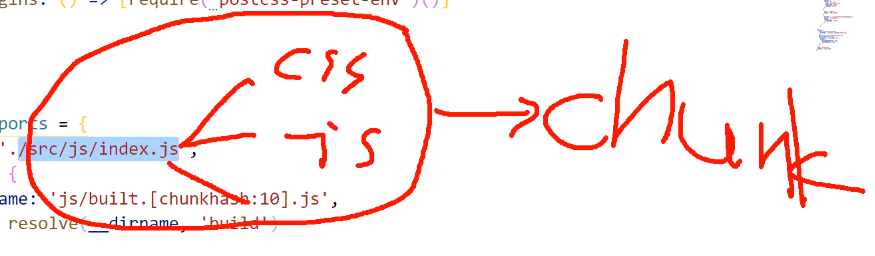
入口文件index.js中需要引入css、js等依赖,这些依赖最终会随着入口文件形成一个文件,他就是一个chunk
注意:
由于js和css还是在同一个入口文件,所以使用chunkhash最终js和css还是同一个hash
sideEffects
在package.json中写入 “sideEffects”: false 表示所有代码都没有副作用(都可以进行tree shaking)
在tree shaking的时候的问题:

tree shaking的时候可能会把css / @babel/polyfill的文件干掉
解决方法:
sideEffects中把css后缀的文件包含进来:
package.json中写入:
“sideEffects”: ["*.css"]
code split
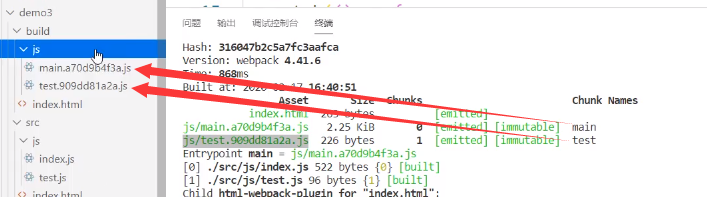
将原本打包后的一份文件拆成3份
使用场景:
- 并行加载,加快加载速度
- 按需加载,我需要了才去加载
使用方法:
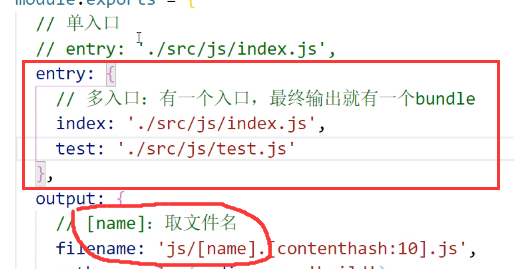
为了分辨生成的两个build,我们可以使用[name]进行分辨,[name]表示取文件名
单页面应用配置:整个应用程序只有一个页面,对应的是单入口
多页面应用配置:整个应用程序有多个页面,对应的是多入口
像上面这种code split有一个问题:可能会频繁修改页面的个数,今天单页面,明天多页面,这样的话我们的配置代码也得跟着变,非常的麻烦
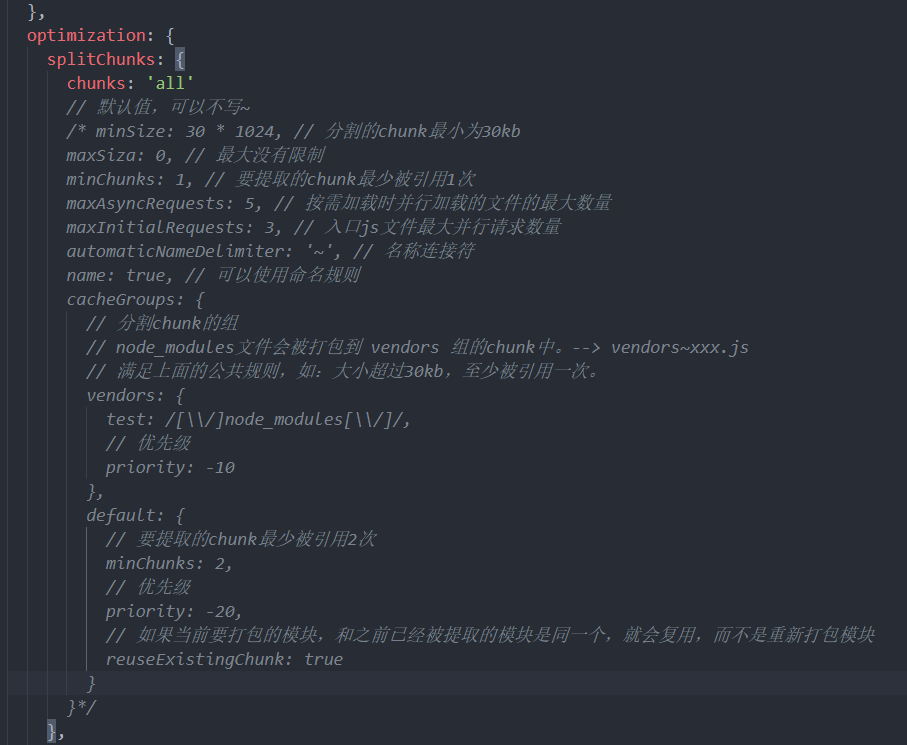
splitChunks
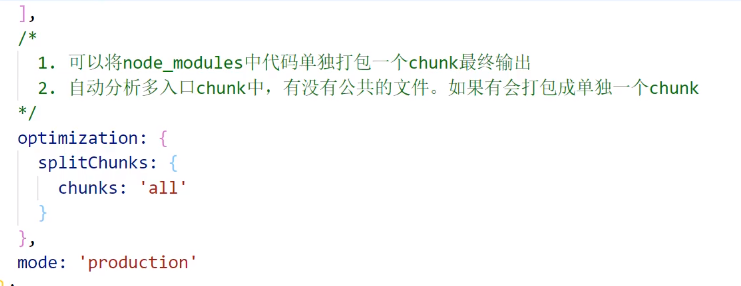
将node_modules中代码单独打包成一个chunk没啥好说的
我们看看下面那条:他会自动分析chunk中是否有公共的文件,如果有则会打包成单独的一个chunk
解释:
假设我们现在是多入口,在两个入口文件index.js和test.js中都引用了jQuery,现在打包,理想状态下我们希望生成test、index和一个jQuery的打包文件,但是事实上jQuery是会被打包成两个built文件的(重复打包)
但是当我们使用了splitChunk之后就不会出现重复打包的情况了
除了上面两点之外,还有一点:
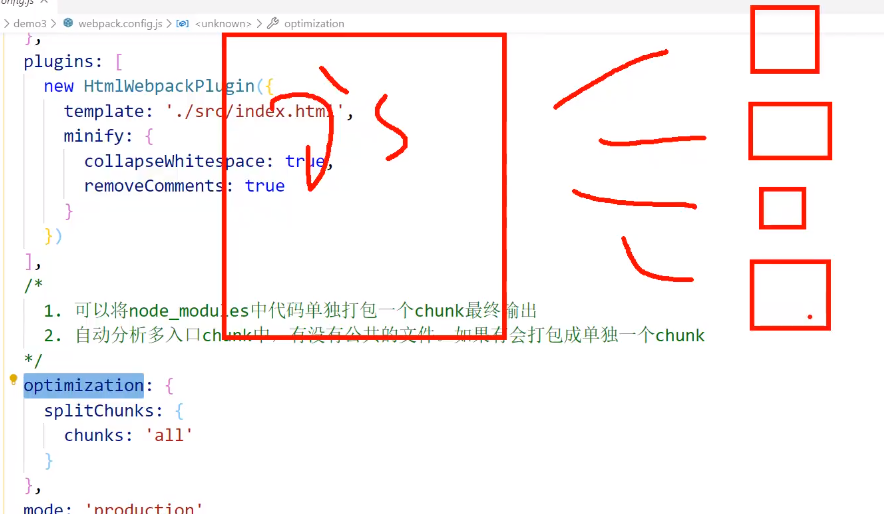
当我们是单入口文件时,有一个test.js和一个index.js,这个时候我们将test引入index,打包势必只会生成一个built文件,但是我们希望将index里面的test单独打包
这个时候需要借助js代码:
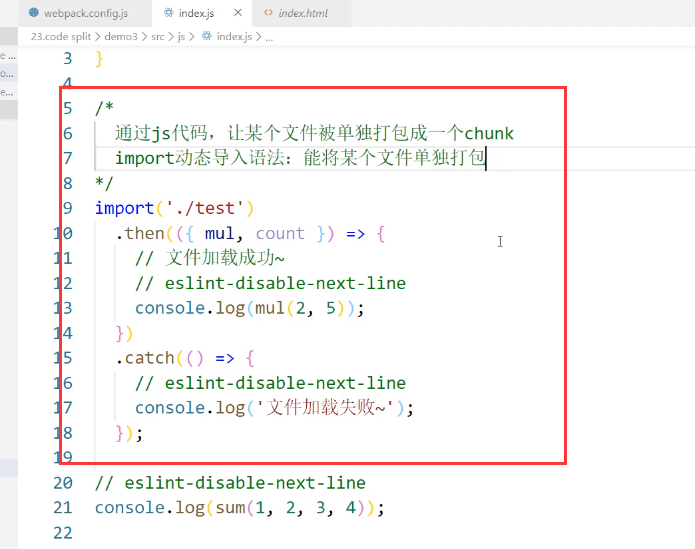
当我们使用了import动态导入语法之后test.js就会被单独打包了
有个问题:
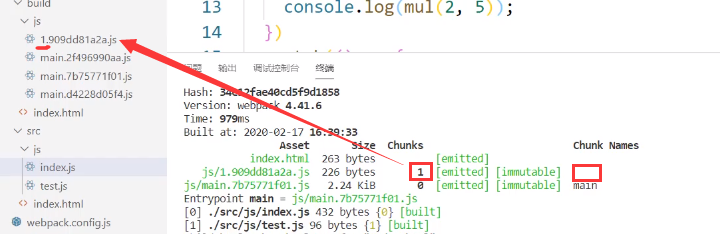
Chunks这里每次打包都会生成一个id,而且随着文件数量递增,这个id可能会变,这不太好,我们希望他是一个固定的名称而不是id
解决方法:
import里面参数前面加一段注释:
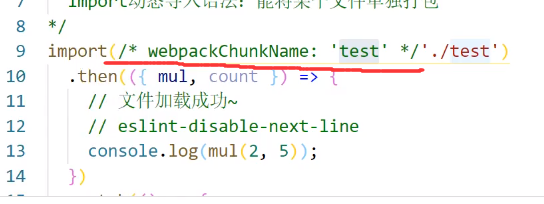
这里他的名字就变成 test 了:
这里我们使用splitChunk配合import动态导入语法将一整个大的js文件分割成多个小的js文件,从而实现并行加载,速度更快
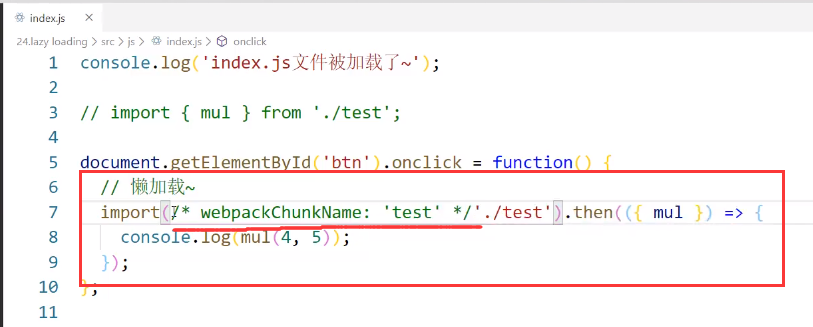
懒加载
这里不是指图片的懒加载,而是指js文件的懒加载
懒加载就是指不是一上来就加载,而是等触发了某些条件我才去加载
结果:
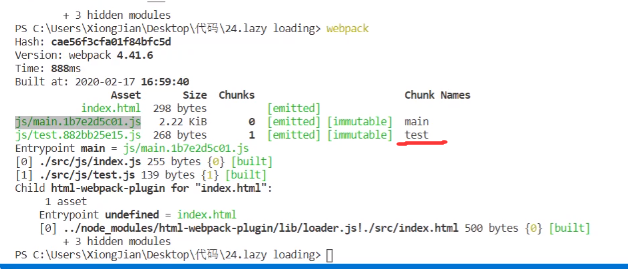
果不其然,./test.js文件被单独打包成一个js文件,因为只有单独打包成一个js文件,才可以被懒加载
那他会不会重复加载呢?
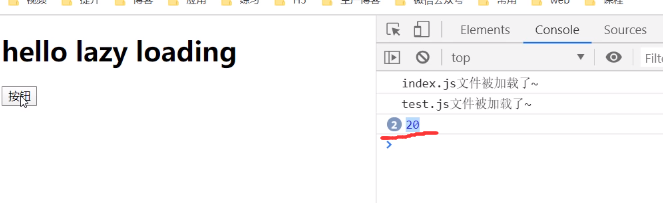
是不会的,第二次他会去读取缓存
注意:
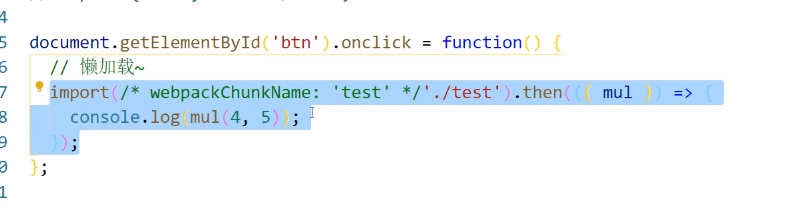
这里是一个异步的回调函数
预加载
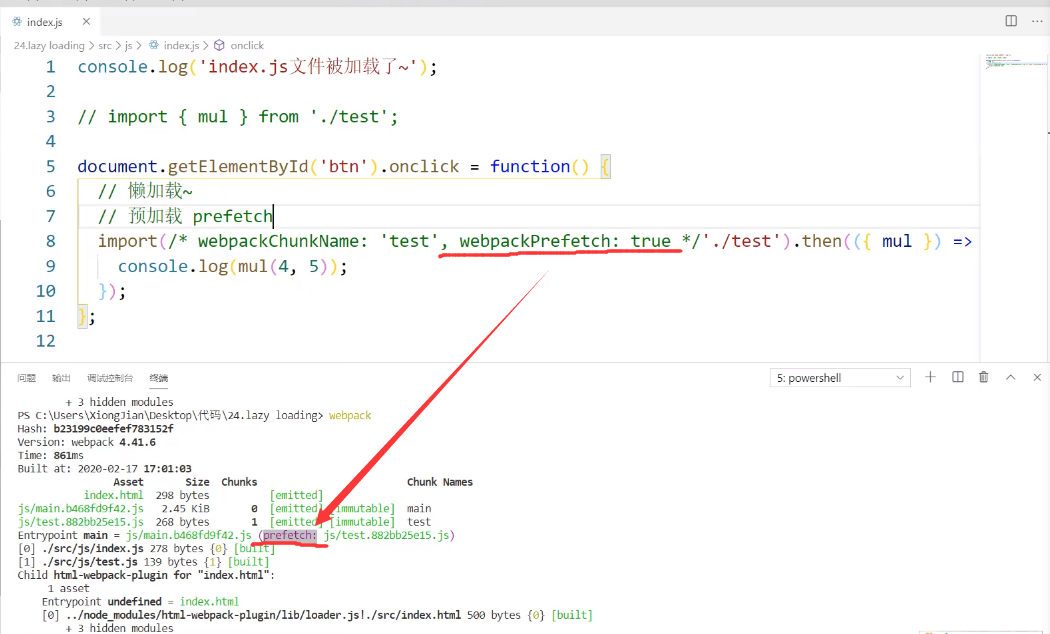
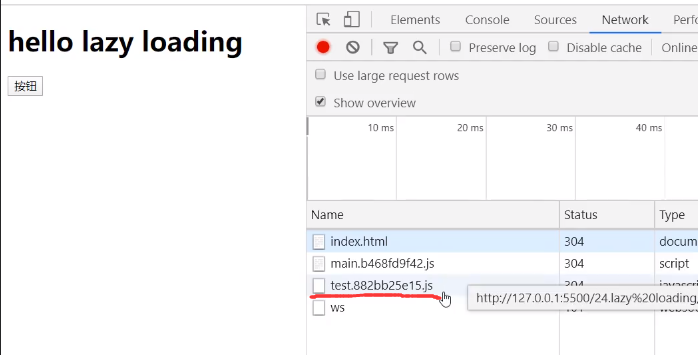
我们刷新页面后发现其实test已经被预加载好了
点击按钮(调用test.js里面的函数),发现他读取的是之前预加载的js的缓存:
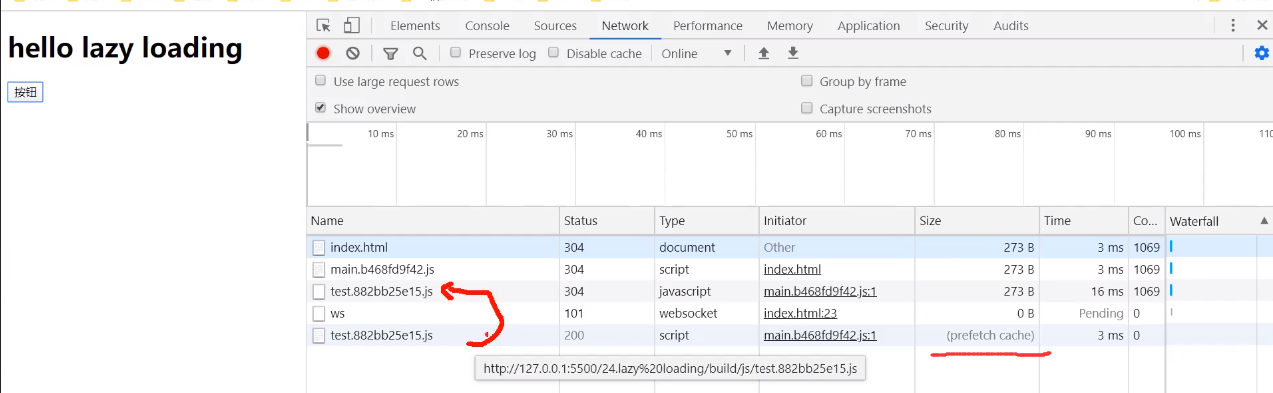
预加载和普通加载区别
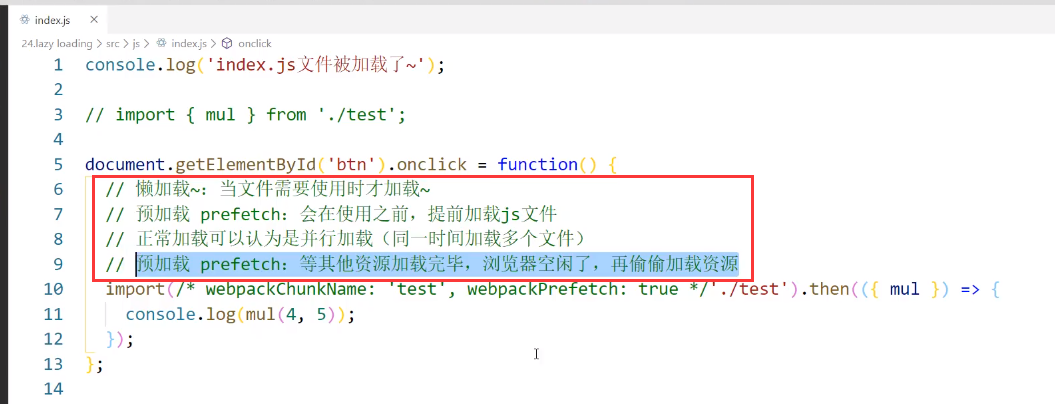
但是预加载兼容性不太好,尤其是在移动端
PWA(渐进式网络开发应用程序,离线可访问)
离线访问网站
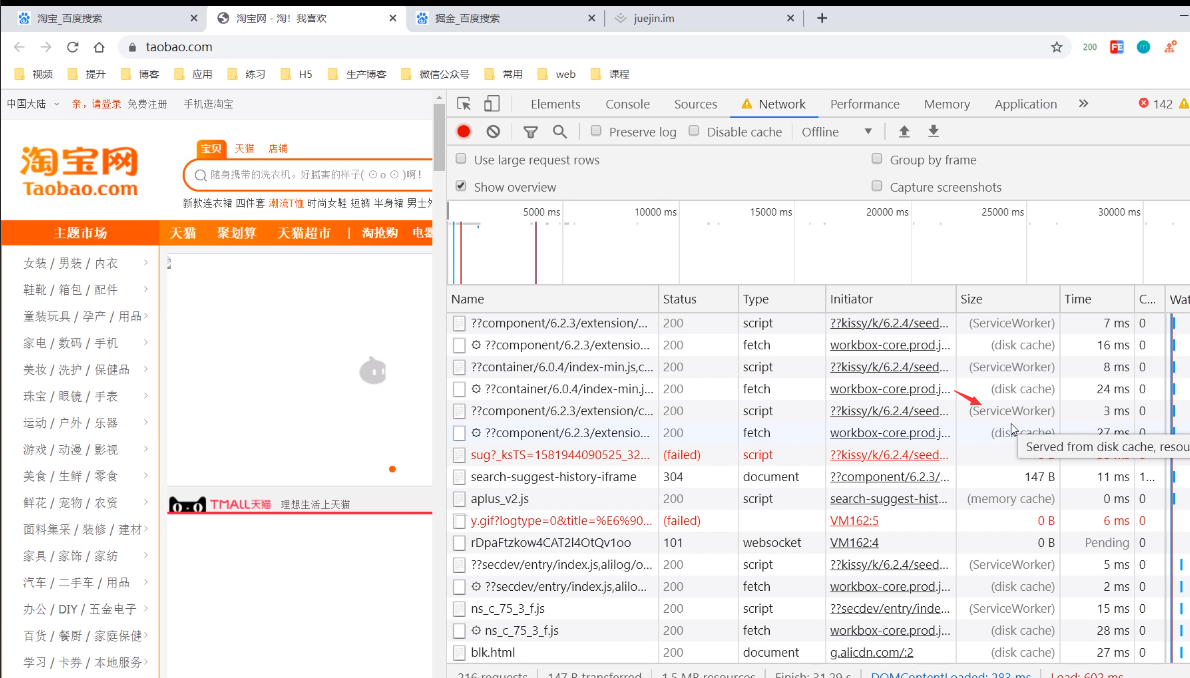
淘宝就是用了PWA技术,离线也能访问部分资源
没问题的资源基本来自ServiceWork
使用插件之后出现问题:

eslint不认识window、navigator等全局变量
解决方法:
package.json中添加配置:
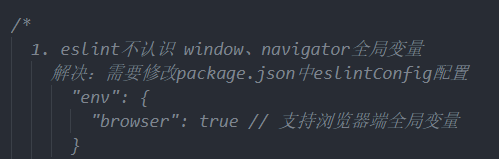
同理,要eslint支持nodejs中的变量则需这么写:
"env": {
"node": true
}
serviceWorker需要运行在服务器端
serviceWorker注册成功后:
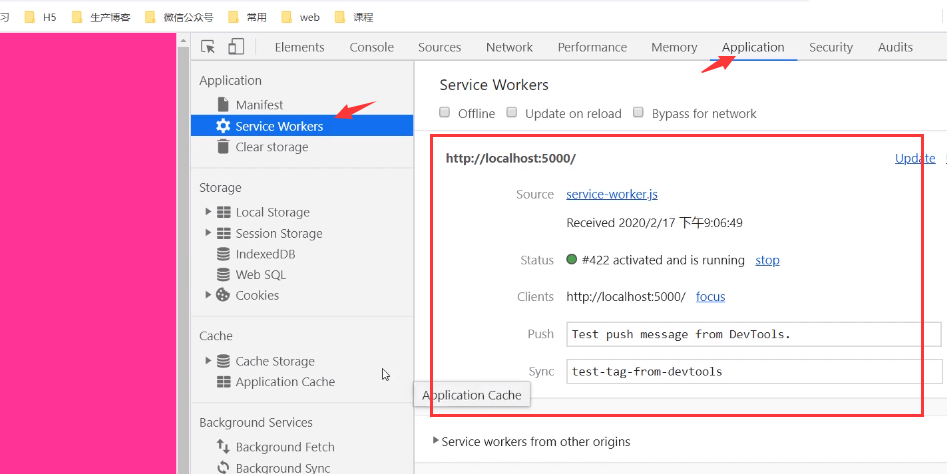
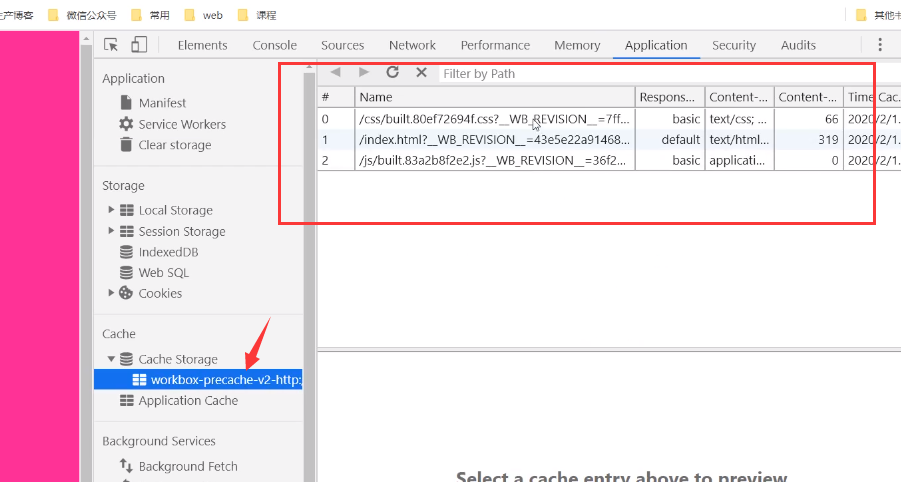
我们还能从Cache找到缓存的资源:
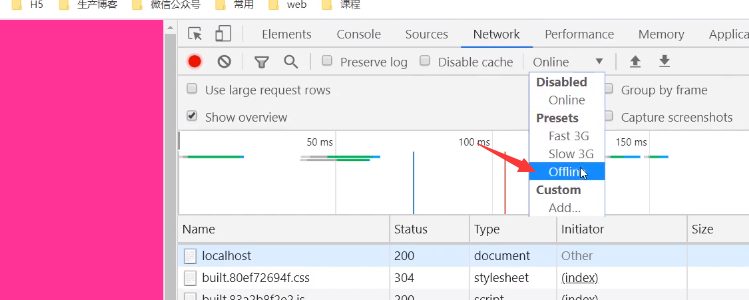
现在我们将服务器关闭或者网络调为offline:
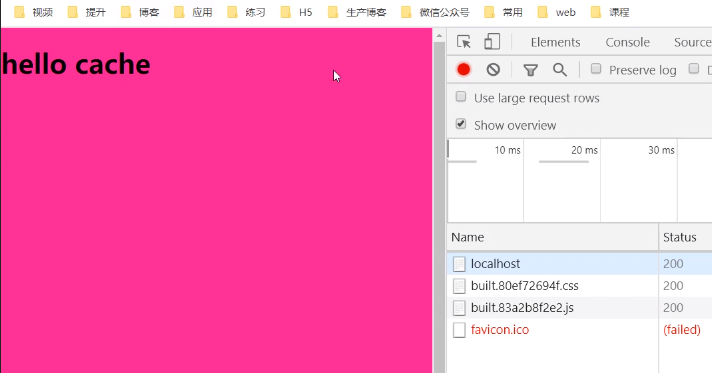
刷新页面之后页面资源还可以访问:
多进程打包
一般给babel用
哪个模块要用就给哪个模块加
externals
有些包我们希望使用script标签加url的方式引入,而不希望他也被打包:

语法:
库名 : 包名
如下:
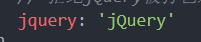
注意:
如果使用了externals,我们需要像上上图那样手动给他引入script标签
Dll
像externals一样指定哪些库不参与打包
还可以对某些库进行单独的打包,将多个库打包成一个chunk
dll可以和code split联用
code split将node_module单独打包成一个庞大的文件
dll可以将node_module中的一部分拆开成几个单独打包,其余的node_module中不想用dll拆开的部分就使用code split打包成一个
其他参数
publicPath
公共前缀
chunkFilename
非入口chunk名称
像import动态引入在打包时产生的chunk以及code split中将node_module打包成一个chunk的时候生成的文件名称将会遵循chunkFilename命名
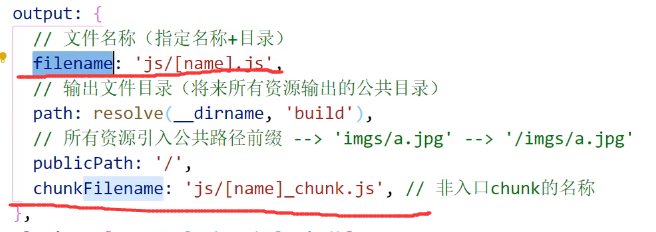
如果不指定chunkFilename,则遵循filename命名
library
之前打包好的文件:
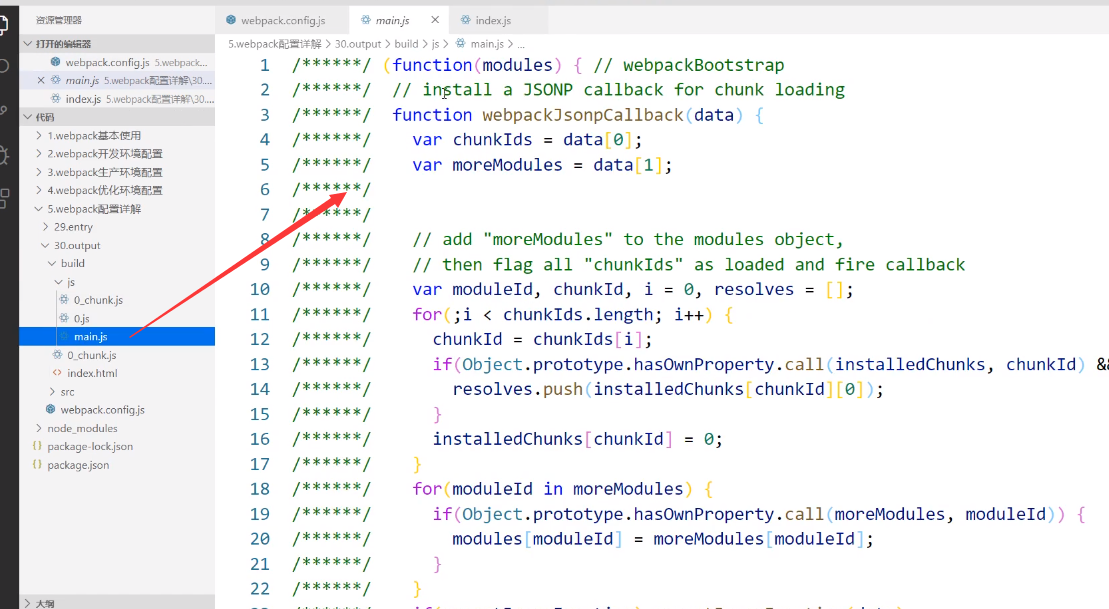
整个外面包了一层函数,因此里面的内容都在函数作用域下,外面想引用的话是不可以的
那么我们想把里面的内容暴露出去的话就需要使用library了

再次打包,我们发现:
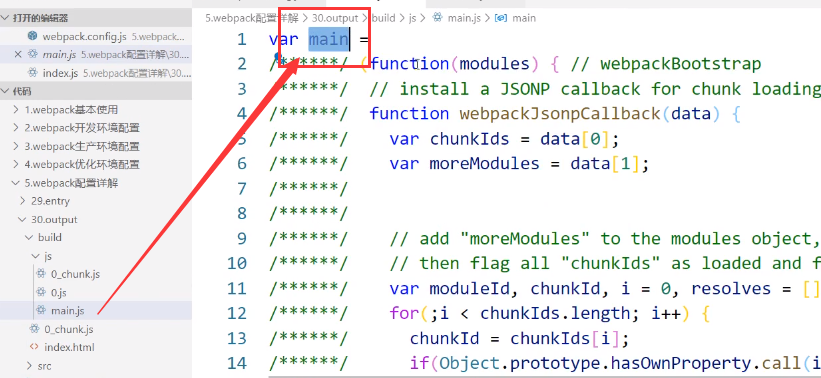
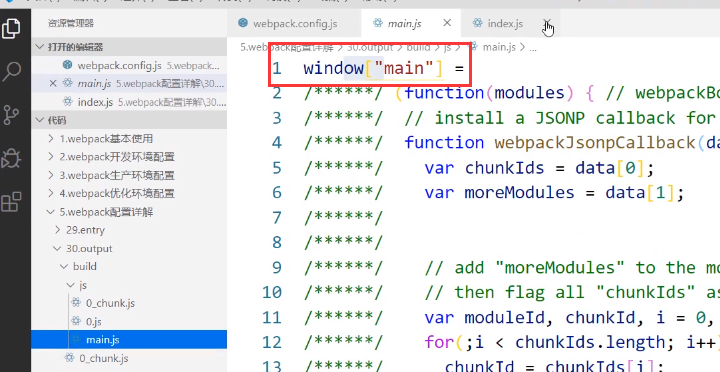
有了一个变量 main (之所以是main是因为名称[name]默认就是“main”)
这样我们可以通过引入该js文件找到里面的main变量从而来使用这个打包后的js文件中的东西
libraryTarget
不写这个参数只写library那就是简单的暴露一个变量
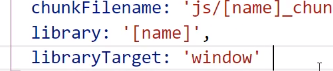
定义library这个变量定义到哪里
比方说上图,意思就是定义到window里:
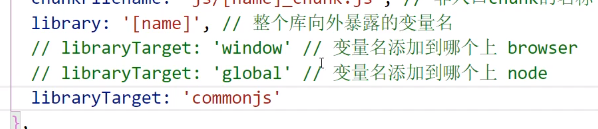
其他的还可以添加到node,commonjs等:
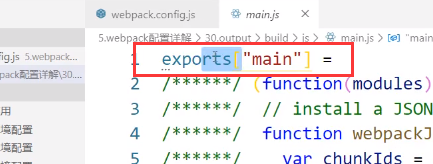
再举一个例子,比方说上图是将变量名添加到commonjs上,那打包之后的文件就是这样的:
library与dll连用
library一般会与dll连用,使用dll将某些库单独打包,然后使用library去暴露这些打包好的库,从而来使用这些库
enforce
指定loader的执行顺序
enforce: “pre"表示优先执行
enforce: “post"表示延后执行
如果不写这个参数那就是正常的中间执行
resolve
解析模块的规则
alias
指定路径别名
应用场景:
在入口文件中我们需要引入文件,但是这个文件可能嵌套了好几层(可能项目里有好几个组件,组件里面还能嵌套组件),导致我们想要引用的文件在很深的地方,手写路径名很容易出错
alias就可以解决这个问题:

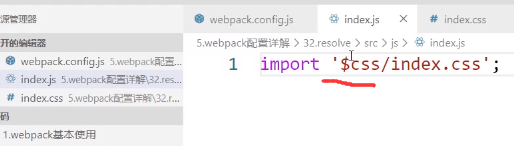
extensions
配置省略文件路径的后缀名
例子:
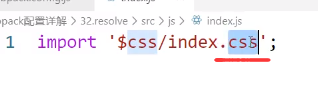
我现在想省略这个.css
配置:
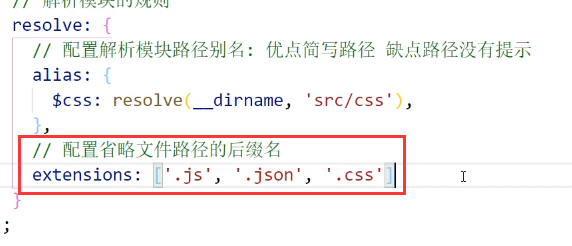
效果:
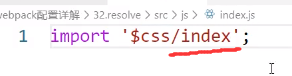
原理:从extensions数组中找后缀,尝试index.js发现不对,下一个,尝试index.json发现不对,下一个,尝试index.css,发现对了,那就是这个了
所以他的问题也显而易见了:index.js和index.css傻傻分不清,因此如果要用extensions,文件名最好不要取一样的
modules
告诉webpack解析模块是去哪里找
一般来讲node_modules都是从当前目录下找,找不到再去上一层,再找不到再去上上层,如果嵌套比较深的话将会十分麻烦
可以使用modules直接指定node_modules在哪:

后面那个参数“node_modules”是为了防止他直接指定路径之后还是找不到node_modules,所以给他写的:

optimization
问题:
假设我们给文件取名使用的是[contenthash]
假设index.js引入a.js,那么index.js打包后生成的文件中会保留a.js所生成的hash值:
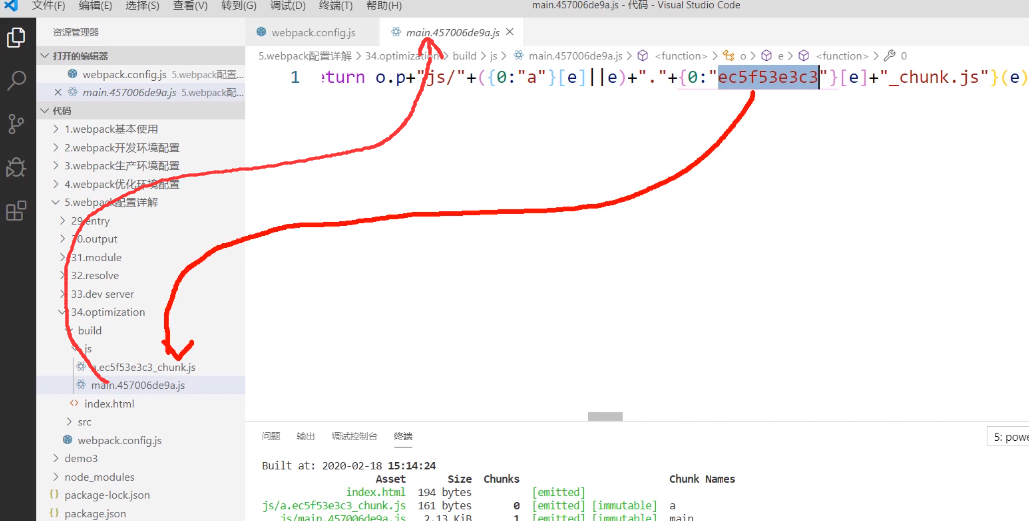
这就出问题了,如果这个时候我们修改a.js的代码,由于使用的是contenthash,a.js打包后生成的文件文件名必定会修改,导致index.js打包后生成的main.js中保存的a.js的hash值发生变化,相当于main.js文件发生了变化,导致最后执行打包命令的时候index.js跟着一起被重新打包,导致了缓存失效
解决方法就是将main.js中记录的a.js的hash值单独拿出来打包,这样main文件中就不记录a.js的hash值了,自然不会出现上面的问题
这个配置叫runtimeChunk
runtimeChunk
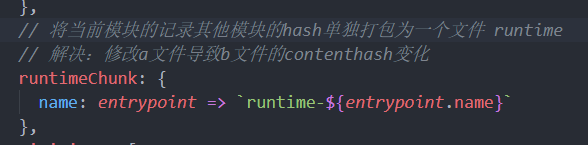
现在打包后的文件就会多一个runtime的文件了:
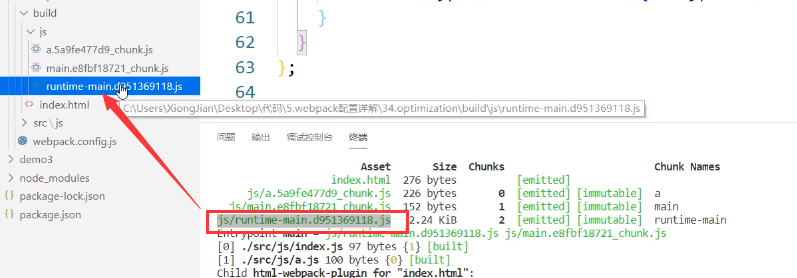
现在main.js中就不会存储a.js的hash值了,都存到runtime文件中了
这个时候a.js文件如果在发生变化,是不会影响到main.js的(main.js由于缓存的原因不会重新打包),重新打包的只会是a.js和runtime文件
minimizer
上面讲过js文件怎么压缩的:启动生产者模式,就会自动开启Uglifyjs去压缩js,现在这个库已经不维护了,转而使用terser去进行js的压缩
如果我们不需要修改terser配置,那就别动他了,不需要再去写额外配置了,但如果我们想要修改他的配置,那就可以在minimizer中去写他:
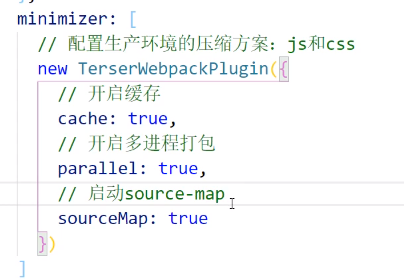
注意,如果需要source-map,这里一定要启用source-map,如上图,否则它会被压缩掉的
同理,如果想修改css也可以在这个minimizer中去修改
跨域问题
浏览器和服务器之间存在跨域问题,而服务器与服务器之间是没有跨域问题的
代理服务器就是利用了这一点,首先浏览器和代理服务器(端口3000)之间没有跨域问题,那么浏览器发送请求到代理服务器,代理服务器再转发到真正的服务器(端口5000),而服务器之间是没有跨域问题的,所以可以正常转发,之后真正的服务器再返回请求给代理服务器,代理服务器再返回信息给浏览器
所以就有一个应用的例子:
在配置中的dev server中有个参数proxy,他就是用来解决我们的开发环境遇到的跨域问题的,当开发环境遇到跨域问题,就可以配置proxy来解决跨域问题:

webpack4与webpack5
webpack4中有一个遗留问题:
假设我们有三个文件:a.js、b.js、index.js,b引入a,index引入b,index中再去调用a的东西:
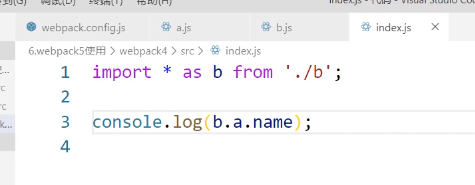
a中有两个变量,其中一个被index通过b.a.name的方式使用了,但是还有一个没有被使用
此时我们打开生产环境,按照道理来讲a中的那个没有被用的变量应该被tree shaking掉,但是并没有,这就是webpack4遗留的问题:间接调用之后webpack就无法分析哪些东西需要被tree shaking了
同样在production环境下,在webpack5中测试同样的问题我们会发现不仅没用到的东西被tree shaking了,打包后代码还变得非常简单:
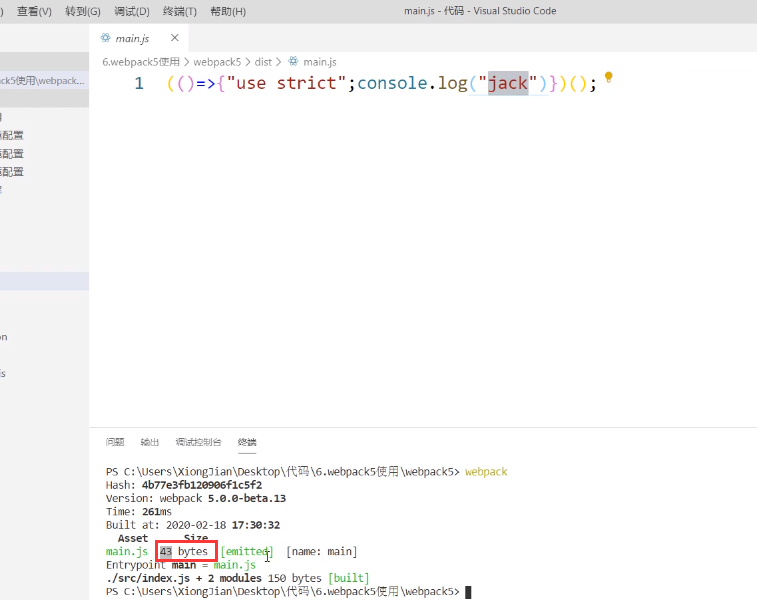
跟webpack4比起来那简直就不是一个量级的,同样内容的打包5比4小了900多bytes,而且打包后内容还非常干净
webpack5
关于5的说明见代码中的第6部分中的README文件: